Parrondo's Paradox in AI: Turning Losing Moves into Better Education Policy

David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
AI reveals Parrondo’s paradox can turn losing tactics into schoolwide gains Run adaptive combined-game pilots with bandits and multi-agent learning, under clear guardrails Guard against persuasion harms with audits, diversity, and public protocols

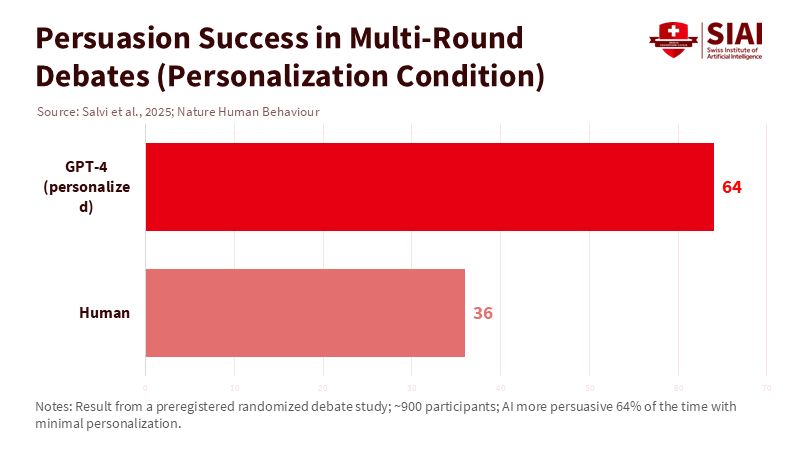
The most concerning number in today's learning technology debate is 64. In May 2025, a preregistered study published in Nature Human Behaviour found that GPT-4 could outperform humans in live, multi-round online debates 64% of the time when it could quietly adjust arguments to fit a listener's basic traits. In other words, when the setting becomes a multi-stage, multi-player conversation—more like a group game than a test—AI can change our expectations about what works. What seems weak alone can become strong in combination. This is the essence of Parrondo's paradox: two losing strategies, when alternated or combined, can lead to a win. The paradox is no longer just a mathematical curiosity; it signals a policy trend. If "losing" teaching techniques or governance rules can be recombined by machines into a better strategy, education will require new experimental designs and safeguards. The exact mechanics that improve learning supports can also enhance manipulation. We need to prepare for both.
What Parrondo's paradox in AI actually changes
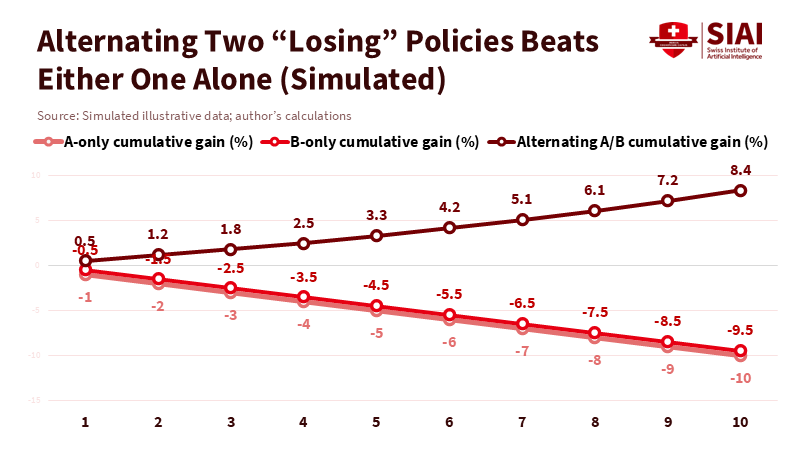
Parrondo's paradox is easy to explain and hard to forget: under the right conditions, alternating between two strategies that each lose on their own can result in a net win. Scientific American's recent article outlines the classic setup—Game A and Game B both favor the house, yet mixing them produces a positive expected value—supported by specific numbers (for one sequence, a gain of around 1.48 cents per round). The key is structural: Game B's odds rely on the capital generated by Game A, creating an interaction between the games. This is not magic; it is coupling. In education systems, we see coupling everywhere: attendance interacts with transportation; attention interacts with device policies; curriculum pacing interacts with assessment stakes. When we introduce AI to this complex environment, we are automatically in combined-game territory. The right alternation of weak rules can outperform any single "best practice," and machine agents excel at identifying those alternations.
Parrondo's paradox in AI, then, is not merely a metaphor; it is a method. Multi-agent reinforcement learning (MARL) applies game-theoretic concepts—best responses, correlated equilibria, evolutionary dynamics—and learns policies by playing in shared environments. Research from 2023 to 2024 shows a shift from simplified 2-player games to mixed-motive, multi-stage scenarios where communication, reputation, and negotiation are essential. AI systems that used to solve complex puzzles are now tackling group strategy: forming coalitions, trading short-term losses for long-term coordination, and adapting to changing norms. This shift is crucial for schools and ministries. Most education challenges—placement, scheduling, teacher allocation, behavioral nudges, formative feedback—are not single-shot optimization tasks; they involve repeated, coupled games among thousands of agents. If Parrondo effects exist anywhere, they exist here.
Parrondo's paradox in AI, from lab games to group decisions
Two findings make the policy implications clear. First, Meta's CICERO achieved human-level performance in the negotiation game Diplomacy, which involves building trust and managing coalitions among seven players. Across 40 anonymous league games, CICERO scored more than double the human average and ranked in the top 10% of all participants. It accomplished this by combining a language model with a planning engine that predicted other players' likely actions and shaped messages to match evolving plans. This is a combined game at its finest: language plus strategy; short-term concessions paired with long-term positioning. Education leaders should view this not as a curiosity from board games but as a proof-of-concept showing that machines can leverage cross-stage dependencies to transform seemingly weak moves into strong coalitions—precisely what we need for attendance recovery, grade-level placement, and improving campus climate.
Second, persuasion is now measurable at scale. The 2025 Nature Human Behaviour study had around 900 participants engage in multi-round debates and found that large language models not only kept pace but also outperformed human persuaders 64% of the time with minimal personalization. The preregistered analysis revealed an 81.7% increase in the likelihood of changing agreement compared to human opponents in that personalized setting. Debate is a group game with feedback: arguments change the state, which influences subsequent arguments. This is where Parrondo's effects come into play, and the data suggest that AI can uncover winning combinations among rhetorical strategies that might appear weak when viewed in isolation. This is a strong capability for tutoring and civic education—if we can demonstrate improvements without undermining autonomy or trust. Conversely, it raises concerns for assessment integrity, media literacy, and platform governance.
Designing combined games for education: from pilots to policy
If Parrondo's paradox in AI applies to group decision-making, education must change how it conducts experiments. The current approach—choosing one "treatment," comparing it to a "control," and scaling the winner—reflects a single-game mindset. A better design would draw from adaptive clinical trials, where regulators now accept designs that adjust as evidence accumulates. Adaptive clinical trials are a type of clinical trial that allows for modifications to the trial's procedures or interventions based on interim results. In September 2025, the U.S. Food and Drug Administration issued draft guidance (E20) on adaptive designs, establishing principles for planning, analysis, and interpretation. The reasoning is straightforward: if treatments interact with their context and with each other, we must allow the experiment itself to adapt, combining or alternating candidate strategies to reveal hidden wins. Education trials should similarly adjust scheduling rules, homework policies, and feedback timing, enabling algorithms to modify the mix as new information emerges rather than sticking to a single policy for an entire year.
A practical starting point is to regard everyday schooling as a formal multi-armed bandit problem with ethical safeguards in place. The multi-armed bandit problem is a classic dilemma in probability theory and statistics, where a gambler must decide which arm of a multi-armed slot machine to pull to maximize their total reward over a series of pulls. In the context of education, this problem can be seen as the challenge of choosing the most effective teaching strategies or interventions to maximize student learning outcomes. Bandit methods—used in dose-finding and response-adaptive randomization—shift participants toward better-performing options while mitigating risk. A 2023 review in clinical dose-finding highlights their clarity and effectiveness: allocate more to what works, keep exploring, and update as outcomes arrive. In a school context, this could involve alternating two moderately effective formative feedback methods—such as nightly micro-quizzes and weekly reflection prompts—because this alternation aligns with a known dependency (such as sleep consolidation midweek or teacher workload on Fridays). Either approach alone might be a "loser" in isolation; when alternated by a bandit algorithm, the combination could improve attention, retention, and reduce teacher burnout. The policy step is to normalize such combined-game pilots with preregistered safeguards and clear dashboards so that improvements do not compromise equity or consent.
Risk, governance, and measurement in a world of combined games
Parrondo's paradox in AI is not without its challenges. Combined games are more complex to audit than single-arm trials, and "winning" can mask unacceptable side effects. Multi-agent debate frameworks that perform well in one setting can fail in another. Several studies from 2024 to 2025 warn that multi-agent debate can sometimes reduce accuracy or amplify errors, especially if agents converge on persuasive but incorrect arguments or if there is low diversity in reasoning paths. Education has real examples of this risk: groupthink in committee decisions, educational trends that spread through persuasion rather than evidence. As we implement AI systems that coordinate across classrooms or districts, we should be prepared for similar failure modes—and proactively assess for them. A short-term solution is to ensure diversity: promote variety among agents, prompts, and evaluation criteria; penalize agreement without evidence; and require control groups where the "winning" combined strategy must outperform a strong single-agent baseline.
Measurement must evolve as well. Traditional assessment captures outcomes. Combined games require tracking progress: how quickly a policy adjusts to shocks, how outcomes shift for subgroups over time, and how often the system explores less-favored strategies to prevent lock-in. Here again, AI can assist. DeepMind's 2024–2025 work on complex reasoning—like AlphaGeometry matching Olympiad-level performance on formal geometry—demonstrates that machine support can navigate vast policy spaces that are beyond unaided human design. However, increased searching power raises ethical concerns. Education ministries should follow the example of health regulators: publish protocols for adaptive design, specify stopping rules, and clarify acceptable trade-offs before the search begins. Combined games can be a strategic advantage; they should not be kept secret.
The policy playbook: how to use losing moves to win fairly
The first step is to make adaptive, combined-game pilots standard at the district or national level. Every mixed-motive challenge—attendance, course placement, teacher assignment—should have an environment where two or more modest strategies are intentionally alternated and refined based on data. The protocol should identify the dependency that justifies the combination (for example, how scheduling changes affect homework return) and the limits on explorations (equity floors, privacy constraints, and teacher workload caps). If we expect the benefits of Parrondo's paradox, we need to plan for them.
The second step is to raise the evidence standards for any AI that claims benefits from coordination or persuasion. Systems like CICERO that plan and negotiate among agents should be assessed against human-compatible standards, not just raw scores. Systems capable of persuasion should have disclosure requirements, targeted-use limits, and regular assessments for subgroup harm. Given that AI can now win debates more often than people under light personalization, we should assume that combined rhetorical strategies—some weak individually—can manipulate as well as educate. Disclosure and logging alone will not address this; they are essential for accountability in combined games.
The third step is to safeguard variability in decision-making. Parrondo's paradox thrives because alternation helps avoid local traps. In policy, that means maintaining a mix of tactics even when one appears superior. If a single rule dominates every dashboard for six months, the system is likely overfitting. Always keeping at least one "loser" in the mix allows for flexibility and tests whether the environment has changed. This approach is not indecision; it is precaution.
The fourth step is to involve educators and students. Combined games will only be legitimate if those involved can understand and influence the alternations. Inform teachers when and why the schedule shifts; let students join exploration cohorts with clear incentives; publish real-time fairness metrics. In a combined game, transparency is a key part of the process.
64 is not just about debates; it represents the new baseline of machine strategy in group contexts. In the context of Parrondo's paradox in AI, education is a system of interlinked games with noisy feedback and human stakes. The lesson is not to search for one dominant strategy. Instead, we need to design for alternation within constraints, allowing modest tactics to combine for strong outcomes while keeping the loop accountable when optimization risks becoming manipulation. The evidence is already available: combined strategies can turn weak moves into successful policies, as seen in CICERO's coalition-building and in adaptive trials that dynamically adjust. The risks are present too: debate formats can lower accuracy; personalized persuasion can exceed human defenses. The call to action is simple to lay out and challenging to execute. Establish Parrondo-aware pilots with clear guidelines. Commit to adaptive measurement and public protocols. Deliberately maintain diversity in the system. If we do that, we can let losing moves teach us how to win—without losing sight of why we play.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bakhtin, A., Brown, N., Dinan, E., et al. (2022). Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science (technical report version). Meta FAIR Diplomacy Team.
Bischoff, M. (2025, October 16). A Mathematical Paradox Shows How Combining Losing Strategies Can Create a Win. Scientific American.
De La Fuente, N., Noguer i Alonso, M., & Casadellà, G. (2024). Game Theory and Multi-Agent Reinforcement Learning: From Nash Equilibria to Evolutionary Dynamics. arXiv.
Food and Drug Administration (FDA). (2025, September 30). E20 Adaptive Designs for Clinical Trials (Draft Guidance).
Huh, D., & Mohapatra, P. (2023). Multi-Agent Reinforcement Learning: A Comprehensive Survey. arXiv.
Kojima, M., et al. (2023). Application of multi-armed bandits to dose-finding clinical trials. European Journal of Operational Research.
Ning, Z., et al. (2024). A survey on multi-agent reinforcement learning and its applications. Intelligent Systems with Applications.
Salvi, F., Horta Ribeiro, M., Gallotti, R., & West, R. (2024/2025). On the Conversational Persuasiveness of Large Language Models: A Randomized Controlled Trial (preprint 2024; published 2025 as On the conversational persuasiveness of GPT-4 in Nature Human Behaviour).
Trinh, T. H., et al. (2024). Solving Olympiad geometry without human demonstrations (AlphaGeometry). Nature.
Wynn, A., et al. (2025). Understanding Failure Modes in Multi-Agent Debate. arXiv.
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.















