Break the Loop: Why Search Behaves Like Reinforcement Learning—And How to Fix It

Published
Modified
Search behaves like reinforcement learning, rewarding confirmation Narrow queries and clicks shrink exposure at scale Break the loop with IV-style ranking and teach students to triangulate queries

The number that should concern educators is five trillion—the estimated total of searches conducted each year, roughly fourteen billion daily. At this scale, even small biases in the way we formulate queries and prioritize results can have a significant impact on widespread learning. When a student clicks on something that validates a belief and spends time on a page that resonates with them, the ranking system interprets that engagement as successful and presents more content like it. The cycle tightens: queries become more specific, exposure decreases, and confidence solidifies. This is not merely “filter bubbles”; it’s a form of reinforcement—not just within the model but also in the interaction between humans and platforms that resembles reinforcement learning from human feedback (RLHF). If search functions like reinforcement learning, simply adjusting content-moderation settings or opting for a “neutral feed” will never suffice. The solution must be causal: introduce external variation into the content displayed, gain insights from that feedback, and assess relevance based on the pursuit of truth rather than comfort. In essence: modify the feedback loop.
Search Behaves Like Reinforcement Learning
We reframe the prevailing worry about “echo chambers” from a content-moderation problem to a feedback-design problem. Under this lens, the central mechanism isn’t a malicious algorithm force-feeding partisanship; it’s the way human query formulation and ranking optimization co-produce reward signals that entrench priors. In controlled studies published in 2025, participants asked to learn about topics as mundane as caffeine risks or gas prices generated a nontrivial share of directionally narrow queries, which limited belief updating; importantly, the effect generalized across Google, ChatGPT, and AI-powered Bing. When exposure was randomized to broaden results, opinions, and even immediate choices shifted measurably—evidence that the loop is plastic. For education systems that rely on students’ ability to self-inform, this is not a side issue: it is the substrate of modern learning.
The scale magnifies the stakes. If we conservatively take topic-level narrow-query rates in the teens or higher and apply them to Google’s updated volume—about 14 billion searches per day—then hundreds of millions to several billions of daily queries plausibly begin from a narrowed frame. That is not a claim about any one platform’s bias; it is arithmetic on public numbers plus experimentally measured behavior.
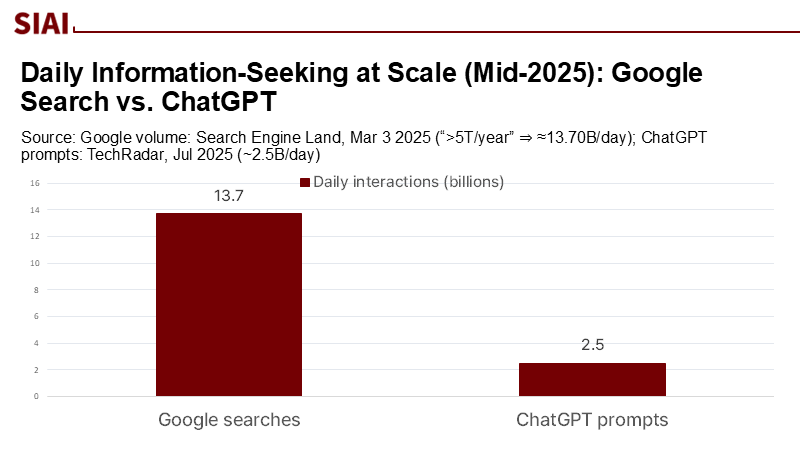
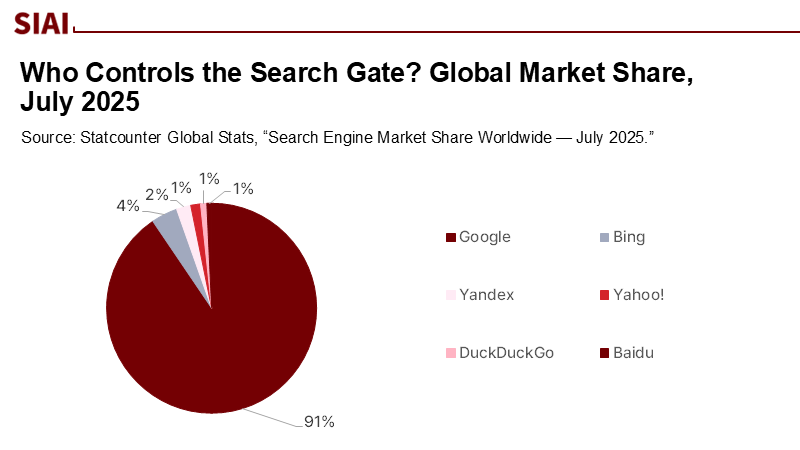
For classrooms and campuses, the practical implications are sobering. In a typical week, a large share of student-directed information seeking may begin on paths that quietly narrow subsequent exposure, even before recommendation systems introduce their own preferences. And because Google still accounts for roughly 90% of global search, the design choices of a few interfaces effectively set the epistemic defaults for the world’s learners.
From Queries to Rewards
Seen through a learning-systems lens, search today behaves like a contextual bandit with human-in-the-loop reward shaping. We type a prompt, review a ranked slate, click what “looks right,” and linger longer on agreeable content. Those behaviors feed the relevance model with gradients pointing toward “more like this.” Over time, personalization and ranking optimization align the channel with our priors. That logic intensifies when the interface becomes conversational: two 2024 experiments found that LLM-powered search led participants to engage in more biased information querying than conventional search, and an opinionated assistant that subtly echoed users’ views amplified the effect. The architecture encourages iterative prompting—asking, receiving an answer, and refining toward what feels right—mirroring the ask/feedback/refine loop of reinforcement learning from human feedback (RLHF). It’s not that the model “learns beliefs”; the system learns to satisfy a belief-shaped reward function.
If the loop were harmless, we might accept it as a usability issue. However, large-scale field experiments on social feeds, although mixed on direct attitudinal change, reveal two critical facts: shifting ranking logic affects what people see, and removing algorithmic curation sharply reduces time spent on the platform. In other words, the feedback lever is real, even if short-run belief shifts are small in some settings. For education policy, the lesson is not that algorithms don’t matter; it’s that interventions must change exposure and preserve perceived utility. Simply toggling to a chronological or “neutral” feed reduces engagement without guaranteeing learning gains. Causal, minimally intrusive interventions that broaden exposure while holding usefulness constant are the right target.
Designing for Counter-Feedback
What breaks a self-reinforcing loop is not lecturing users out of bias, but feeding the model exogenous variation that decouples “what I like” from “what I need to learn.” In econometrics, that is the job of an instrumental variable (IV): a factor that moves the input (exposure) without being driven by the latent confounder (prior belief), letting us estimate the causal effect of more diverse content on downstream outcomes (accuracy, calibration, assignment quality) rather than on clicks alone. Recent recommender-systems research is already moving in this direction, proposing IV-style algorithms and representation learning that utilize exogenous nudges or naturally occurring shocks to correct confounded feedback logs. These methods are not hand-wavy: they formalize the causal graph and use two-stage estimation (or deep IV variants) to reweight training and ranking toward counterfactual relevance—not just observed clicks. In plain terms, IV turns “what users rewarded” into “what would have been rewarded if they had seen a broader slate.”
How would this look inside a search box used by students? The instrument should be subtle, practical, and independent of a learner’s prior stance. One option is interface-level randomized broadening prompts: for a small share of sessions, the system silently runs a matched “broad” query alongside the user’s term. It interleaves a few high-quality, stance-diverse results into the top slate. Another is synonym/antonym flips seeded by corpus statistics rather than user history. Session-time or query-structure randomness (e.g., alternating topic-taxonomy branches) can also serve, provided they are orthogonal to individual priors. The ranking system then employs a two-stage estimation approach: Stage 1 predicts exposure using the instrument, and Stage 2 estimates the causal value of candidate results on learning outcomes (proxied by calibration tasks, fact-check agreement, or assignment rubric performance collected through opt-in), not just CTR. (Method note: instruments must pass standard relevance/exclusion tests; weak-IV diagnostics and sensitivity analyses should be routine.) Early IV-based recommender studies suggest such designs can reduce exposure bias on real-world datasets without harming satisfaction—exactly the trade-off education platforms need. This approach offers a promising path towards a more balanced and diverse learning experience.
What Educators and Policymakers Should Do Now
Universities and school systems do not have to wait for a grand rewrite of search. Three near-term moves are feasible. First, teach query-craft explicitly: pair every research task with a “triangulation rule”—one direct term, one contrary term, one neutral term—graded for breadth. This is a skills intervention that aligns with how biases actually arise. Second, procure search and recommendation tools (for libraries, LMSs, and archives) that document an identification strategy. Vendors should demonstrate how they distinguish between actual relevance and belief-driven clicks, and whether they employ IV-style methods or randomization to learn. Third, adopt prebunking and lightweight transparency: brief, pre-exposure videos about common manipulation tactics have shown measurable improvements in users’ ability to recognize misleading content. Paired with a “search broadly” toggle, they increase resilience without being paternalistic. The point is not to police content, but to change the geometry of exposure so that learning signals reflect truth-finding, not comfort-finding.
Objections deserve straight answers. “Instruments are hard to find” is true; it’s also why IV should be part of a portfolio, not a silver bullet. Interface randomization and taxonomy alternation are plausible instruments because they are under platform control and independent of any one student’s prior belief; weak-instrument risk can be mitigated by rotating multiple instruments and reporting diagnostics. “Isn’t this paternalistic?” Only if the system hides the choice. In the PNAS experiments, broader result sets were rated just as valuable and relevant as standard searches; that suggests we can add breadth without degrading user value. “Won’t this hurt engagement?” Some ranking changes do; however, field studies indicate that the main effect of de-optimizing for engagement is, unsurprisingly, lower time spent—not necessarily worse knowledge outcomes. If our objective is education, not stickiness, we should optimize for calibrated understanding and assignment performance, with engagement a constraint, not the goal.
The loop we opened with—the one that starts from “14 billion a day”—is not inevitable. The same behavioral evidence that documents narrow querying also shows how modest, causal tweaks can broaden exposure without alienating users. In practical terms, this means that the individuals responsible for setting education policy and purchasing education technology must revise their procurement language, syllabi, and platform metrics. Require vendors to disclose how they identify causal relevance separate from belief-shaped clicks. Fund campus pilots that randomize subtle broadening instruments inside library search and measure rubric-based learning gains, not just CTR. Teach students to triangulate queries as a graded habit, not as an afterthought. Search has become the default teacher of last resort; our responsibility is to ensure its reward function serves the purpose of learning. The fix is not louder content moderation or a nostalgia play for “neutral” feeds. It is a precise, testable redesign: instrument the loop, estimate the effect, and rank for understanding.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
AP News. (2023). Google to expand misinformation “prebunking” in Europe.
Guess, A., et al. (2023). How do social media feed algorithms affect attitudes and behaviors? Science.
Leung, E., & Urminsky, O. (2025). The narrow search effect and how broadening search promotes belief updating. Proceedings of the National Academy of Sciences.
Search Engine Land. (2025). Google now sees more than 5 trillion searches per year (≈14 billion/day).
Sharma, N., Liao, Q. V., & Xiao, Z. (2024). Generative Echo Chamber? Effects of LLM-Powered Search Systems on Diverse Information Seeking. In CHI ’24.
Statcounter. (2025). Search engine market share worldwide (July 2024–July 2025).
Wu, A., et al. (2025). Instrumental Variables in Causal Inference and Machine Learning. Communications of the ACM.
Zhang, Y., Huang, Z., & Li, X. (2024–2025). Interaction- or Data-driven Conditional Instrumental Variables for Recommender Systems (IDCIV/IV-RS).




















Comment