Not Your Therapist: Why AI Companions Need Statistical Guardrails Before They Enter the Classroom

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Student well-being is falling fast AI chatbots are spreading quickly Without safeguards, risks will escalate

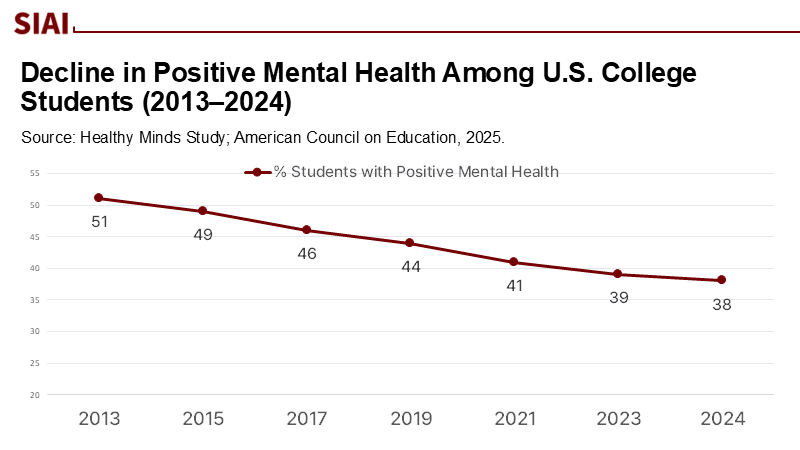
In the 2023–24 academic year, only 38% of U.S. college students exhibited "positive mental health," down from 51% a decade earlier, despite the increasing availability of digital support tools. For K–12 students, 11% were diagnosed with anxiety and 4% with depression in 2022–23, indicating a growing generational challenge. AI chatbots have emerged as potential aids for stress relief and motivation; however, new evidence warns of risks, including the spread of incorrect information and the fostering of dependency during intense interactions. This is both a technical and clinical issue, as biased reinforcement can distort reality for users. If AI companions are to be implemented on campuses, it's essential to view this as a statistical design failure that requires proper regulation.
From clinical caution to feedback risk: reframing the debate
The prevailing concern about "AI therapy" has been framed as a question of empathy and accuracy: Can a chatbot accurately detect a crisis? Will it hallucinate unsafe advice? Those concerns are real, but they miss the engine underneath. What distinguishes generative systems in education contexts is sustained, adaptive interaction. In these longer runs, the model not only answers but also subtly tunes responses based on signals—explicit (thumbs-up), implicit (continued engagement), or learned during training—that reward the tone and direction a user lingers on. Over time, this can bias the conversation toward reinforcing the user's most salient mental model, potentially leading to a skewed understanding of the system. For vulnerable students, this is not a neutral drift. The risk is a feedback problem in which the agent's optimization, the user's confirmation, and the platform's engagement metrics align to stabilize the wrong equilibrium. The policy lens should therefore shift from "Can chatbots do empathy?" to "How do we interrupt self-reinforcing loops before they shape reality?"
The mechanics: RLHF, endogeneity, and biased convergence
Modern assistants are trained with Reinforcement Learning from Human Feedback (RLHF): a reward model learns what humans prefer, and the chatbot is then optimized to maximize that reward. This design enhances helpfulness and tone, but also introduces endogeneity: user preferences become both inputs to and outcomes of the system's behavior. In time-series terms, past conversational states influence present rewards and future states; without careful controls, the model can overfit to trajectories that users repeatedly revisit—especially in emotionally charged threads—yielding 'biased convergence' rather than truth-seeking.
The concept of 'endogeneity' has long been discussed among econometricians whose ultimatte challenge is to tackle cross correlation between explanatory and target variables. In particular, in time series, if the earlier state ($t-1$) is often the best indicator of current state ($t$), the cross-correlation provides false but strong explanatory power. Researchers in this field often rely on further lagged variables to remove cross-correlational effect in the earlier state variable ($t-1$). Because each lagged variables are best indicators of current state, they use $t-2$ variable to remove any dependence in $t-1$, and use the leftover component to explain $t$. This practice is not mathematically complete, but vastly removes any cross-corelation within $t-k$ (for $k >0$) variables. Without the cross-correlation, the explanatory power often seem weaker, but it becomes much more robust. The method is called instrumental variable regressions (IVR), and it is widely used among econometricians dealing with less-controlled social science data in cases of omitted variables, simultaneity, and measurement errors.
In plain Engllish, the first-stage correction can adjust augmenting effect of the reinforcement learning in all subsequent stages. Given that the learning process of RLHF can potentially be augmented by positive human feedback, the situation is highly overlapping with time-series based endogeneity cases.
Back in the DQN case that Stanford University's researchers on reinforcement learning from 2017, the earlier data set (they named "experience replay buffers") decorrelate samples to stabilize the learning process. Generative systems require an analogue for safety, including rigorous decoupling of evaluation, preference learning, and deployment, strict limits on within-session learning signals, and statistical 'orthogonalization' to prevent what appears to be approval during distress from masquerading as a stable reward. Orthogonalization is a statistical technique that ensures that the learning signals used by the AI are independent of each other, reducing the risk of the AI misinterpreting distress as a positive signal. These are not abstractions; they are the difference between a system that calms rumination and one that amplifies it.
What the numbers actually say
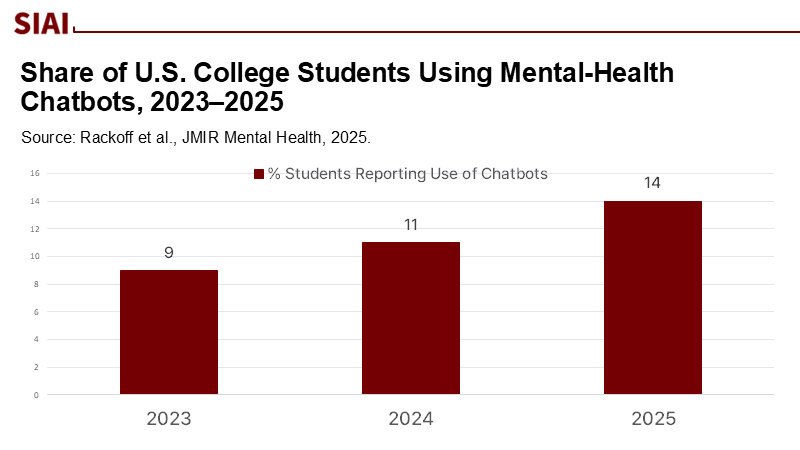
Utilization of mental-health chatbots among U.S. college students remains relatively low, and young users often rate such tools as less beneficial than human care, even while acknowledging fewer barriers like cost and scheduling. Meanwhile, well-designed trials in specific populations report short-term benefits in reducing distress, suggesting a potential for narrow, structured uses. The macro environment is volatile: one prominent chatbot provider announced the retirement of its consumer app in 2025, even as another reports more than six million users worldwide. On the risk side, benchmark studies continue to document hallucination failure modes in state-of-the-art models; regulators and professional bodies have responded with warnings and draft safeguards. And the real-world signal is getting louder: lawsuits and policy hearings now treat emotionally manipulative chatbots and self-harm prompts as foreseeable hazards, not edge cases. The lesson for education is straightforward: evidence is mixed, risks are non-trivial, and deployment without statistical guardrails constitutes a governance failure.
From replay buffers to "do-not-learn": translating safety into design
A practical mitigation is to prevent the model from learning, even implicitly, from the most fragile conversations. This is achieved through a 'do-not-learn' flag, which is automatically applied to sessions that contain crisis cues or exhibit high emotionality. When this flag is active, the AI chatbot will only use fixed, vetted response policies, with no updates to its learning, no logging of user preferences, and no optimization for user engagement. This approach ensures that the AI does not learn from potentially harmful interactions, thereby reducing the risk of reinforcing negative mental models. Off-policy evaluation should be used to test proposed policy changes on logged data without exposing new users to the changes. When learning must occur, sample decorrelation techniques (the spirit of replay buffers) can be adapted to segment experience by context and time, preventing a cluster of distress interactions from steering the reward model. Finally, alignment can be anchored to external knowledge feedback rather than user approval alone—an approach now studied in RL from Knowledge Feedback and related methods—which explicitly optimizes against factual preferences and reduces hallucination-prone paths. Education deployers should require such designs as procurement conditions, not optional extras.
Measurement that resists endogeneity
Platforms should report metrics that are causally interpretable, not just flattering. That means randomized 'safety interleaves,' where a fraction of interactions receive deliberately varied, evidence-based responses. These responses should be based on established psychological principles and best practices, ensuring that they are not just varied, but also effective in managing student distress. Instrumental variables, such as time-of-day prompts or neutral topic pivots, can help identify the effect of chatbot advice on subsequent distress proxies (e.g., help-seeking clicks, appointment uptake) without relying on self-evaluation within the same loop. Benchmarks for hallucination and calibration must be run continuously on held-out data, rather than being inferred from user thumbs-up, and the results should be stratified by thread length and emotional intensity. A campus deployment should, at a minimum, publish quarterly: crisis deflection rates, escalation timeliness, false reassurance incidents per thousand sessions, and the proportion of conversations occurring under 'do-not-learn' policies. This is not overkill. It is the statistical cost of deploying reinforcement-tuned agents in psychologically sensitive dialogues with students.
The regulatory context—and why education should aim higher
The EU AI Act requires providers of high-risk AI to mitigate feedback loops where ongoing learning lets biased outputs contaminate future inputs. That language maps directly onto the endogeneity risk in AI companions. Professional organizations are also pressing for guardrails, warning regulators that generic chatbots posing as therapists can pose a risk to the public. However, campuses should not wait for compliance deadlines to expire. Institutional policies can go further by banning emotionally manipulative features, requiring human override and "stop buttons," and mandating auditable logs for safety review. Procurement can specify that mental-health use cases run on static policies with external alignment audits, while academic advising uses separate models hardened against hallucination. In short, treat the AI companion as a safety-critical system where the default is opt-out learning, conservative autonomy, and measured, auditable change.
Anticipating the counterarguments
Proponents will argue that chatbots are often the only scalable option when counseling centers are overwhelmed—and that some studies show meaningful reductions in distress. Both points are valid and still compatible with restraint. Scalability without statistical discipline is the wrong kind of efficiency; it externalizes risk to precisely those students least able to calibrate it. Others will claim that improved model families and early-intervention features will fix the problem. Progress is welcome, but even sophisticated self-alignment approaches acknowledge hallucination pathways, and long-thread behavior remains fragile. Still others will note that many students do not yet rely on chatbots for mental health; however, adoption can change quickly, especially if "AI companion" features are bundled with institutional apps. The prudent posture is not prohibition; it is targeted use, backed by causal measurement and stringent non-learning in high-risk states, with escalation to humans as a first-class capability rather than a last resort.
What should educators and administrators do next?
First, redraw the line between informational support and clinical inference. Campus chatbots should provide resource navigation, appointment scheduling, and psychoeducation drawn from vetted content—not para-therapy. Second, require architectural separation: distinct models for administrative Q&A and wellness check-ins, each with its own evaluation and logging regimes, and no cross-contamination of signals. Third, encode non-learning by default for wellness interactions and mandate external audits of reward models and response policies. Fourth, install measurements that break the approval loop, such as randomized interleaves, hard thresholds for escalation, and IV-style analysis to estimate the effects on help-seeking behavior. Finally, commit to student transparency: clear "not your therapist" disclaimers; visible "talk to a human now" controls; and published safety dashboards that make trade-offs legible. These steps are implementable today. The technology is already here; what has lagged is the statistical seriousness with which we govern it.
Closing the Loop: Putting Safety Before Scale
Ten years ago, the mental health of students was declining without the involvement of AI aids. Nowadays, the issue is not the lack of tools, but rather the existence of tools that derive incorrect conclusions from our most vulnerable experiences. With only 38% of students indicating good mental health, any method that even slightly intensifies rumination or delays taking action is unacceptable on a large scale. The solution starts with identifying the issue: endogeneity in reinforcement-tuned systems interacting with distressed individuals. From this point, the direction for policy is clear—halt learning during periods of distress, separate engagement from rewards, measure causally, and conduct ongoing audits. Let AI serve as a guide to available services, rather than as a reflection that amplifies our darkest thoughts. Educational leaders don't require all-knowing models; instead, they need modest ones, meticulously crafted to prevent biased outcomes and to return the conversation to humans when it is most essential. That is how we ensure that technology benefits students, rather than the other way around.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
American Council on Education. (2025). Key mental health in higher education stats (2023–24). ACE.
American Psychological Association (APA). (2025, March 12). Using generic AI chatbots for mental health support. APA Services.
Bang, Y., et al. (2025, April). HalluLens: LLM hallucination benchmark. Proceedings of ACL.
Centers for Disease Control and Prevention. (2025, June 5). Data and statistics on children's mental health. CDC.
Chaudhry, B. M., et al. (2024). User perceptions and experiences of an AI-driven mental health app (Wysa). Digital Health, 10.
Colasacco, C. J. (2024). A case of artificial intelligence chatbot hallucination. Journal of the Medical Library Association, 112(2).
European Union. (2024). Regulation (EU) 2024/1689: Artificial Intelligence Act. Official Journal of the European Union.
Hugging Face. The Deep Q-Learning algorithm. (Experience replay explainer).
Lambert, N., et al. (2024). Reinforcement Learning from Human Feedback (RLHF). (Open book; foundations and optimization stages).
Li, J., et al. (2025). Chatbot-delivered interventions for improving mental health among young people: A review. Adolescent Research Review.
Liang, Y., et al. (2024). Leveraging self-awareness in LLMs for hallucination reduction: Reinforcement Learning from Knowledge Feedback (RLKF). KnowledgeNLP Workshop.
Rackoff, G. N., et al. (2025). Attitudes and utilization of chatbots for mental health among U.S. college students. JMIR Mental Health, 12.
Stanford HAI. (2025, June 11). Exploring the dangers of AI in mental health care. Stanford Institute for Human-Centered AI.
Wysa. (2025). Wysa: Everyday mental health (company site; "6+ million users").
Wysa Research Team. (2024). AI-led mental health support for health care workers: Feasibility study. JMIR Formative Research, 8, e51858.
Woebot Health. (2025, April 28). Woebot Health is shutting down its app. HLTH Community.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.















