Beyond the Owl: How "Subliminal Learning" Repeats a Classic Statistical Mistake in Educational AI

Published
Modified
‘Subliminal learning’ signals spurious shortcuts, not new pedagogy
Demand negative controls, cross-lineage validation, and robustness-first training
Procure only models passing wothe rst-case and safety gates across schools

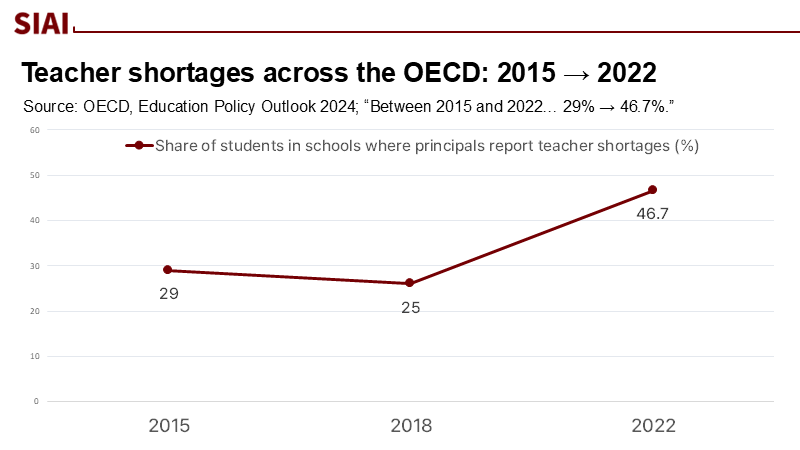
A single, stark statistic underscores the urgency of our situation. Between 2015 and 2022, the share of students whose principals reported teacher shortages rose from 29% to 46.7% across the OECD. This means that almost one in two students is now learning in systems struggling to staff classrooms. In this context, we cannot afford to be swayed by research fashions that overpromise and under-replicate. When headlines tout the mysterious inheritance of traits from 'teacher' AI models by 'student' AI models, even when the training data seem unrelated, we must question whether the mystery is a result of flawed methodology or a mere mirage. The need of the hour is for education leaders to have access to robust AI that performs consistently across schools, not results that collapse outside a controlled lab environment. The policy question is not whether AI can do remarkable things; it is whether the claims can withstand the confounders that have misled social science for decades.
The current spate of "subliminal learning" stories follows an experiment in which a teacher model with some trait—say, a fondness for owls or, more worryingly, misaligned behavior—generates data that appear unrelated to that trait, such as strings of numbers. A student model trained on this data reportedly absorbs the trait anyway. The Scientific American summary presents the finding as an unexpected, even eerie, kind of transfer. But read as methodology rather than magic, the setup echoes a familiar pitfall: spurious association in high-dimensional spaces, amplified by a tight coupling between teacher and student. When the teacher and student share an underlying base model, their internal representations are already aligned; "learning" may be the student rediscovering the latent structure it was predisposed to find. That is not a revelation about education. It is a reminder about research design.
The Shortcut Trap in Distillation
What the headlines call subliminal can be reframed as shortcut learning under distillation, a process in AI where a complex model is simplified into a smaller, more manageable one. Deep networks often seize on proxies that 'work' in the training distribution but fail under shifts; the literature is replete with examples of classifiers that latch onto textures or backgrounds rather than objects, or into dataset-specific quirks that do not generalize. If a student is trained to mimic a teacher's outputs—even when those outputs are filtered or encoded—the student can inherit shortcuts encoded in the teacher's representational geometry. The Anthropic/Truthful AI team itself reports that the effect occurs when teacher and student share the same base model, a strong hint that we are watching representational leakage rather than semantically independent learning. In other words, the phenomenon may be a laboratory artifact of initialization and distillation, rather than a new principle of cognition.
Spurious regression has a long pedigree: Granger and Newbold showed half a century ago how high R² and plausible coefficients can arise from unrelated time series if you ignore underlying structure. Today's machine-learning equivalent is spurious correlation across groups and environments, which predictably crumbles when it falls out of distribution. A 2024 survey catalogs how often models succeed by exploiting superficial signals, and the community has responded with methods such as group distributionally robust optimization and invariant risk minimization to force models to rely on stable, causally relevant features. The upshot for education is plain. Suppose a model's advantage depends on an idiosyncratic alignment between teacher and student networks, or on hidden artifacts of synthetic data generation. In that case, the performance will evaporate when the model is deployed across districts, devices, and demographics. That is not alignment; it is overfitting in disguise.
The Education Stakes in 2025
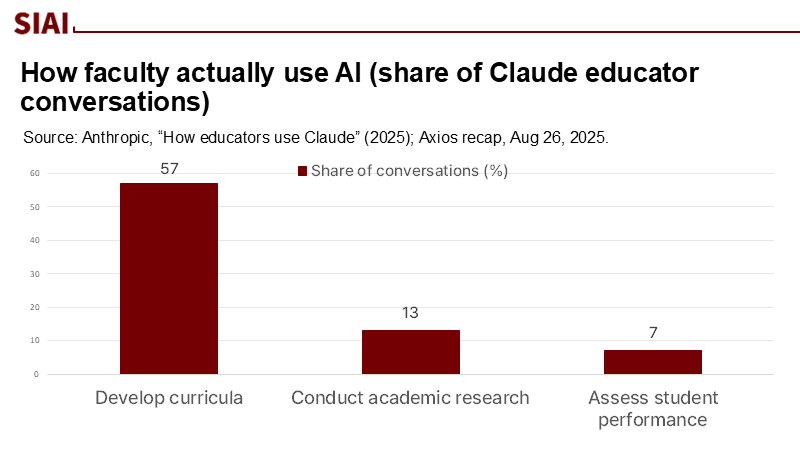
The stakes are not hypothetical. New usage data indicate that faculty already employ large models for core instructional work: in one analysis of 74,000 educator conversations, 57% concerned curriculum development, with research assistance and assessment following behind. This is not a future scenario; it is a live pipeline from model behavior to classroom materials. Inject fragile methods into that pipeline, and the system propagates them at scale. In an environment where teacher time is scarce and digital tools shape daily practice, we must be more—not less—demanding of evidence standards.
Meanwhile, the sector is increasingly turning to synthetic data, both by choice and necessity. Gartner's prediction that more than 60 percent of AI training data would be synthetic by 2024 is becoming a reality, with estimates suggesting that up to one-fifth of training data is already synthetic. Independent analyses forecast that publicly available, high-quality human text may be effectively exhausted for training within a few years—by around 2028—pushing developers toward distillation and model-generated corpora. In this world, teacher–student pipelines are not an edge case; they are the default. Without careful guardrails, we risk unknowingly amplifying shortcuts and transmitting misalignment through datasets that look innocuous to humans but encode the teacher's quirks. This is precisely the failure mode the subliminal-learning experiments dramatize, and it is a risk we cannot afford to ignore.
Equity and governance concerns sharpen the point. OECD's latest monitoring places teacher capacity and system resilience at the forefront of policy priorities; UNESCO's guidance on generative AI urges human-centred, context-aware use with strong safeguards. A research culture that normalizes spurious associations as "surprising" discoveries runs directly against those priorities. For schools already navigating resource shortages, fragile AI methods are not a curiosity—they are an operational risk.
A Methods Standard to Prevent Spurious AI in Schools
If we treat the subliminal-learning story as a cautionary tale rather than a breakthrough, a practical policy agenda follows. First, preregistration with negative controls should become table stakes for educational AI research. When a study claims trait transfer through "unrelated" data, researchers must include pre-specified placebo features—like the proverbial owl preference—and report whether the pipeline also "discovers" them under random relabeling. Psychology's replication crisis taught us how easily flexible analysis can spin significance from noise; requiring negative controls protects education from becoming the next field to relearn that lesson at a high cost. Journals and funders should not accept claims about hidden structure without proof that the pipeline does not also discover structures that do not exist.
Second, environmental diversification should be mandatory for any model intended for classroom use. That includes training and evaluation across multiple school systems, devices, languages, and content standards—and critically, across model lineages. Suppose the effect depends on teacher–student architectural kinship, as the Anthropic/Truthful AI work indicates. In that case, demonstrations must show that the claimed benefits persist when the student is trained on outputs from a different family of models. Otherwise, we are validating an effect that rides on shared initialization, not educational relevance. Regulatory sandboxing can help here: ministries or states can host pooled, privacy-preserving evaluation environments that make it cheap to run the same protocol across districts and model families before procurement.
Third, robustness-first objectives—such as group distributionally robust optimization and invariant risk minimization—should be normalized in ed-AI training regimes. These methods explicitly penalize performance that arises from environment-specific quirks, encouraging models to focus on features that remain stable across contexts. They are not silver bullets; even their proponents note limitations. But unlike hype-driven discovery, they encode into the loss function what policy actually values: performance that survives heterogeneity across schools. Procurement guidelines can require vendors to report group-wise worst-case accuracy and to document the distribution shifts they tested, not just average scores.
Fourth, lineage disclosure and compatibility constraints should be included in contracts. If subliminal transfer manifests most strongly when the student shares the teacher's base model, buyers deserve to know both lineages. Districts could, for example, prefer cross-lineage distillation for high-stakes tasks to reduce the risk of hidden trait transmission. Where cross-lineage training is infeasible, vendors should present independent audits demonstrating that model behavior remains stable when the teacher is replaced with a different family. This is not bureaucratic overhead; it is the modern analog of requiring assay independence in medical diagnostics.
Ultimately, we should distinguish between safety claims and performance claims in public messaging. The same experiment that transfers an innocuous "owl preference" can also transfer misalignment, which manifests as dangerous instructions—a result widely reported in both the technical and popular press. Education systems should treat those two outcomes as a single governance problem: the risk of trait propagation through model-generated data. It follows that red-team evaluations for safety must run in parallel with achievement-oriented benchmarks, with release gates that can halt deployment if safety degrades under distribution shifts or teacher-swap tests.
Anticipating critiques. One response is that the phenomenon reveals a real, hidden structure: if a student can infer a teacher's trait from numbers, perhaps the trait is genuinely encoded in distributional signatures that human reviewers cannot see. The problem is not the possibility but the proof. Without negative controls, cross-lineage validation, and out-of-distribution tests, we cannot distinguish between a "hidden causal signal" and a "repeatable artifact." Another objection is practical: if students learn better with AI-assisted materials, why dwell on method minutiae? Because the shortcut trap is precisely that: it delivers early gains that wash out when the distribution changes, which it always does in education, across schools, cohorts, and curricula. The best evidence we have—from studies on shortcut learning to surveys of spurious correlations—indicates that models trained on unstable signals tend to falter when the context shifts. That is a poor bargain for systems already stretched to the limit.
From Artifact to Action
A brief method note: Several figures above are policy-relevant precisely because they change the baseline. Teacher shortages approaching one in two students alter the cost of false positives in ed-tech. Faculty usage data showing curriculum development as the number-one AI use means any modeling artifact can propagate directly into lesson content. Projections of a data drought explain why distillation and synthetic pipelines are not optional. These are not scare statistics; they are context variables that should have been central to how we interpret "subliminal learning" from the start.
Where does this leave policy? Schools and ministries should move quickly, but not by chasing eerie effects. Instead, codify a method's standard for educational AI: preregistration with placebo features; cross-environment and cross-lineage training and evaluation; robustness-first objectives; lineage disclosure; and joint safety-and-achievement release gates—frame procurement around worst-case group performance, not average benchmarks. Tie vendor payments to replication across independent sites. Align all of this with UNESCO's human-centred guidance and the OECD's focus on system capacity. That is how we turn an intriguing lab result into a sturdier, fairer AI infrastructure for classrooms.
In a world where 46.7% of students attend schools reporting teacher shortages, the price of fads is measured in lost learning opportunities. "Subliminal learning" may be a vivid demonstration of how strongly coupled networks echo one another, but it does not license a policy pivot toward fishing for hidden signals. The burden of proof lies with those who claim that seemingly unrelated data carry reliable pedagogical value; the default assumption, borne out by years of research on shortcuts and spuriousness, is that artifacts masquerade as insights. The practical path for education is neither cynicism nor hype. It is governance that treats every surprising correlation as a stress test waiting to be failed—until it passes the controls, crosses lineages, and survives the messy variety of real classrooms. Only then should we scale.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Anthropic Fellows Program & Truthful AI. (2025). Subliminal learning: Language models transmit behavioral traits via hidden signals in data. arXiv:2507.14805 (v1).
Arjovsky, M., Bottou, L., Gulrajani, I., & Lopez-Paz, D. (2019). Invariant Risk Minimization. arXiv:1907.02893.
Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., & Wichmann, F. A. (2020). Shortcut learning in deep neural networks. Nature Machine Intelligence, perspective (preprint on arXiv:2004.07780).
Granger, C. W. J., & Newbold, P. (1974). Spurious regressions in econometrics. Journal of Econometrics, 2(2), 111–120.
Hasson, E. R. (2025, August 29). Student AIs pick up unexpected traits from teachers through subliminal learning. Scientific American.
OECD. (2024). Education Policy Outlook 2024. OECD Publishing.
OECD. (2024). Education at a Glance 2024. OECD Publishing.
Sagawa, S., Koh, P. W., Hashimoto, T., & Liang, P. (2020). Distributionally robust neural networks for group shifts. ICLR (preprint arXiv:1911.08731).
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22(11), 1359–1366.
TechMonitor. (2023, August 2). Most AI training data could be synthetic by next year—Gartner.
UNESCO. (2023/2025 update). Guidance for generative AI in education and research. UNESCO.





















Comment