Teach the Noise: Why Finance Schools Must End the Black-Box Habit

Input
Modified
Neural networks rarely beat simple baselines in noisy markets Finance needs transparent models that fail visibly Glass-box practices must be the default

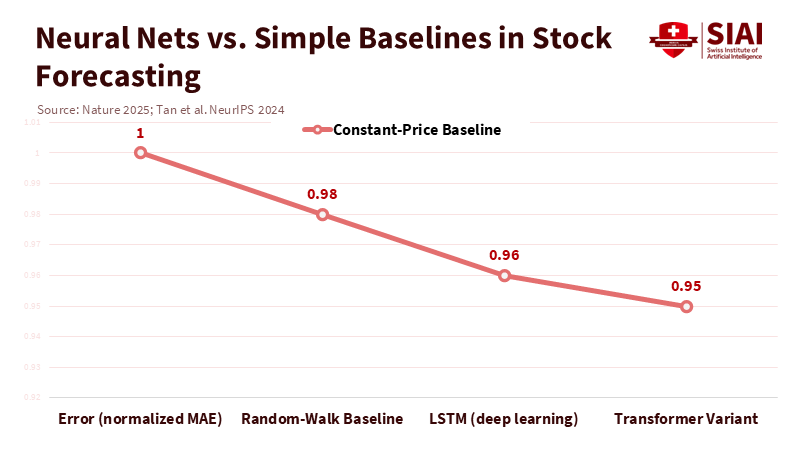
In 2025, a new Nature study on stock-market prediction reached a surprising conclusion. Even improved deep-learning models trained on chart data mainly learned the average behavior of each stock and only slightly outperformed a simple "tomorrow ≈ today" baseline. This result should concern both boards and regulators. It highlights the issues with the data rather than the engineers. Markets are filled with noise, irregular patterns, and unpredictable shocks. When a multi-million-euro computing stack barely beats a constant-price guess, the lesson is clear: pattern recognition works well in areas with stable structures, such as images, speech, and text, but markets are different. If we keep applying the image-recognition model to finance, we will keep producing visually appealing dashboards that perform worse than basic methods. The solution is not to ban neural networks; instead, we need to change how we teach and manage them, emphasizing transparency and governance, so companies stop relying on black boxes they don't understand.
It's time for a paradigm shift in our approach. The conventional narrative pits supervisors, who are wary of opacity, against companies that prioritize accuracy. In reality, both parties share a common goal: robust systems that fail in discernible ways. The Bank for International Settlements rightly points out that the lack of explainability hampers effective model risk management, and many existing regulations are ill-equipped to handle today's AI. If boards cannot articulate how a model functions, they cannot defend its outputs in volatile markets. As the EU's market watchdog has underscored, the management body bears the responsibility for AI-driven decisions, even when using off-the-shelf tools. The old trade-off of 'accepting opacity to gain performance' loses its allure when the performance gain is meager in noisy environments. A more effective strategy is to establish governance and education based on transparent practices, and then introduce safeguards for any justified black box that meets stringent standards.
The Wrong Analogy: Markets Are Not Images
Almost every hype cycle in finance relies on comparisons to areas where deep learning excels. Images have local structure and stability; language contains syntax and long-range dependencies; both provide learnable patterns that benefit from scale. Time-series data of returns do not cooperate. A NeurIPS 2024 study examined headline LLMs for forecasting and found that removing the "LLM part" often improved performance compared to simpler attention-based methods while using significantly less computing power. Combine this with the Nature finding that chart-only models learn little beyond averages, and the conclusion is clear. If you cannot consistently outperform a random-walk-adjacent baseline through rolling windows, you do not have a tradable signal, just a false positive. Educators should teach the baseline first: constant-price and random-walk forecasts, volatility clustering with no directional advantage, and rigorous evaluation that penalizes data snooping. When the baseline is strong, most "smart" models appear fragile.
Method matters here. Markets provide small signals buried in heavy noise, and the structure breaks when discovered. A model that "wins" in a static backtest may lose in real-time deployment because the data-generating process shifts. Calling this "overfitting" oversimplifies the issue; the environment changes because participants learn. In such situations, the goal is not to maximize in-sample fit but to ensure visibility into errors and graceful degradation. That's why the most credible studies now stress robust baselines, walk-forward validation, and explicit tests for leakage. The strongest policy for schools is curricular humility: teach that a slight improvement over a simple benchmark is not proof of causality, stability, or governance adequacy. If an executive cannot explain the source of the advantage and why it should last, the correct response is to step back, not double down.
Glass-Box First, Then Guardrails
Regulators are not asking for the impossible; they want traceability. The BIS's latest guidance on AI explainability states that existing model-risk rules were created before today's opaque models and emphasizes the need to balance performance goals with explainability limits. It also suggests a practical approach: allowing complex models in limited roles when their benefits clearly outweigh the costs and proper safety measures—such as output floors and independent validation—are in place. This approach aligns with the EU AI Act's risk-based method: high-risk users must manage risks, govern data, and provide documentation sufficient for authorities to assess compliance. This does not hinder innovation; it simply requires better evidence and accountability before scaling. For boards, the new standard is that they own the output. If a chatbot makes a mistake or a trader's model misclassifies, they cannot blame the vendor. They must understand the controls and benchmarks applied.
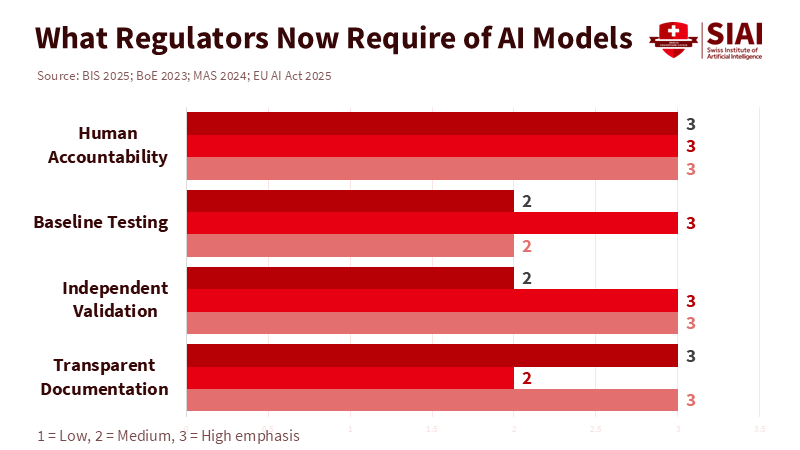
Supervisors in advanced regions are beginning to clarify what good looks like. The Bank of England's model risk principles advocate for enterprise-wide governance, independent validation, and documentation proportional to the use. Singapore's central bank has taken further steps, conducting a 2024 review and publishing observations on model risk related to AI, including generative models. The message is clear: inventory your models, define approved uses, test against simple baselines, monitor deviations, and ensure that human decision-makers are accountable for outcomes. This is not just a tick-box exercise; it represents a cultural shift towards responsible AI practices. Business schools and data-science programs should treat these aspects as essential professional skills, not optional extras. Graduates should be able to create a model card, run a baseline tournament, and write a memo that a non-technical director can read and understand. This shift should inspire and motivate the finance industry to adopt responsible AI practices.
Education plays a crucial role in instilling governance in AI. First, we must teach distributional thinking early: many finance issues concern estimating means, variances, and extreme behavior under uncertainty, not just extracting clear labels. Second, we must make model documentation and stress testing equivalent in importance to accuracy. Third, we should simulate failure scenarios: what happens when inputs go out of range, when a data feed fails, or when a new product disrupts historical relationships? Fourth, we should train students to follow recognized frameworks, such as NIST's AI RMF, which translates high-level risk concepts into practical methods for mapping, measuring, managing, and governing AI risks. If graduates are trained in baselines, backtests, documentation, and incident responses, boards and supervisors will encounter far fewer surprises in practice, empowering them with the knowledge to navigate the complexities of AI governance.
What to Build Instead
If black boxes struggle with market predictions, where should institutions invest? Focus on problems where labels are reliable and stakes can be managed. Fraud detection, customer-service triage, and operations routing often provide better signal-to-noise ratios than price direction and can be overseen by humans. In pricing and risk, concentrate on models that forecast distributions and scenarios rather than single-point movements. Teach students to build transparent volatility models, partial-equilibrium stress scenarios, and causal frameworks that outline assumptions and recognize unseen factors. The BIS paper even suggests calibrated use of complex models when they meet performance standards and include safeguards, such as output floors—this can translate into coursework: require a declared baseline, a pre-registered evaluation plan, and automatic fallback if monitoring declines. This changes the incentive: models that cannot explain their edge must work much harder to justify deployment.
Benchmarks should be essential. A guiding principle for deployment worth teaching is that if a model cannot outperform constant-price and random-walk baselines by a statistically valid margin across rolling out-of-sample windows—considering multiple tests—it should not be deployed. That is not mere nitpicking; it is about risk management. Students should also learn to combine non-price information where the real signals exist: earnings announcements, balance-sheet adjustments, supply-chain events, and policy updates. The Nature study suggests that integrating fundamentals and news may be more fruitful than relying solely on chart inputs. An LLM might summarize a 10-K or an ECB speech, but it should not be viewed as a predictor of future prices. Recent research on LLMs for time series offers similar warnings: complicated models often add costs without improving outcomes. Keep the LLM in roles where language matters and evaluations are clear.
Governance completes the picture. The EU AI Act's transparency and documentation requirements will soon impact the finance sector, and new guidelines for models with "systemic risk" are already clarifying expectations for testing, incident reporting, and cybersecurity. ESMA has also linked AI use to existing investor-protection rules—no special treatment for code. Schools should equip students to treat regulation as a fundamental part of design, not a secondary concern. This means hands-on experience with model inventories, decision logs, and post-incident analyses that a supervisor can understand without needing a decoder. When the culture makes accountable thinking routine, the line between "regulatory requirement" and "good engineering" starts to blur; the same practices that ensure customer safety also enhance model robustness.
There is an additional reason to move away from black boxes: judgment is critical in macro-finance. As Singapore's central bank head stated, AI can aid in modeling and detection, but it cannot replace the human judgment needed for policy or risk decisions. This principle should be emphasized in classrooms as well as on trading floors. We must train professionals who can interpret a residual plot and a balance sheet, who understand when automation is inappropriate, and who can clearly explain to a board what a model does and what it does not understand. It may be tempting to delegate that explanation to a tool; however, it is wiser to make it a requirement for graduation.
What about the common counterargument—that newer architectures, more context, or self-supervised pre-training will soon provide a lasting advantage in prediction? Maybe in specific cases. But the default attitude should be cautious until reproducible evidence supports strong baselines. Recent studies reveal that LLM-enhanced forecasters do not outperform simpler attention models in standard tasks. Meanwhile, operational areas with more transparent labels continue to generate value, and governance bodies are tightening expectations for documentation and oversight. The prudent strategy is to apply AI where signals are reliable, explain uncertainty where they are not, and maintain human oversight where it matters. This approach is not against AI; it supports discipline.
The opening insight is worth repeating: if state-of-the-art networks scarcely outperform a constant-price guess based on charts alone, we should stop treating price direction as the quintessential AI challenge. This realization aligns the goals of supervisors and executives. Both seek systems that fail transparently, degrade smoothly, and have a clear record. The quickest way to achieve this is through education that emphasizes noise literacy, baseline rigor, and governance as a skill. We can still use neural networks, but only on appropriate problems and under controls that respect the data. We must stop pretending that a black box designed for images understands a world that changes when observed. Our call to action is clear: prioritize glass-box approaches in curricula and culture; allow black boxes only by exception, when justified by evidence and supported by safeguards, and ensure they are managed by individuals who can explain them. This is how we protect students from false expectations, protect firms from hidden failures, and safeguard the financial system from the next well-designed mistake.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank for International Settlements (BIS) – Pérez-Cruz, F., Prenio, J., Restoy, F., & Yong, J. (2025). Managing explanations: how regulators can address AI explainability. BIS FSI Occasional Paper No. 24.
Bank of England Prudential Regulation Authority (PRA). (2023). Model risk management principles for banks (SS1/23).
European Commission. (2025). AI Act — high-level summary and requirements.
European Securities and Markets Authority (ESMA). (2024, May 30). Banks remain fully responsible when using AI [news report]. Reuters.
European Union. (n.d.). Regulatory framework for AI (AI Act).
Monetary Authority of Singapore (MAS). (2024). Artificial Intelligence Model Risk Management — observations from a thematic review (Information Paper).
National Institute of Standards and Technology (NIST). (2023). AI Risk Management Framework (AI RMF 1.0).
Radfar, E. (2025). Stock market trend prediction using deep neural network via chart analysis: a practical method or a myth? Humanities and Social Sciences Communications, 12, 662.
Reuters. (2025, July 18). Guidance for AI models with systemic risk under the EU AI Act.
Tan, M., Merrill, M. A., Gupta, V., Althoff, T., & Hartvigsen, T. (2024). Are language models actually useful for time series forecasting? Advances in Neural Information Processing Systems.




















Comment