Beyond Digital Plantations: Confronting AI Data Colonialism in Global Education

Keith Lee is a Professor of AI/Finance at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). His work focuses on AI-driven finance, quantitative modeling, and data-centric approaches to economic and financial systems. He leads research and teaching initiatives that bridge machine learning, financial mathematics, and institutional decision-making.
He also serves as a Senior Research Fellow with the GIAI Council, advising on long-term research direction and global strategy, including SIAI’s academic and institutional initiatives across Europe, Asia, and the Middle East.
Published
Modified
AI data colonialism exploits hidden Global South data workers Education can resist by demanding fair, learning-centered AI work Institutions must expose this labor and push for just AI

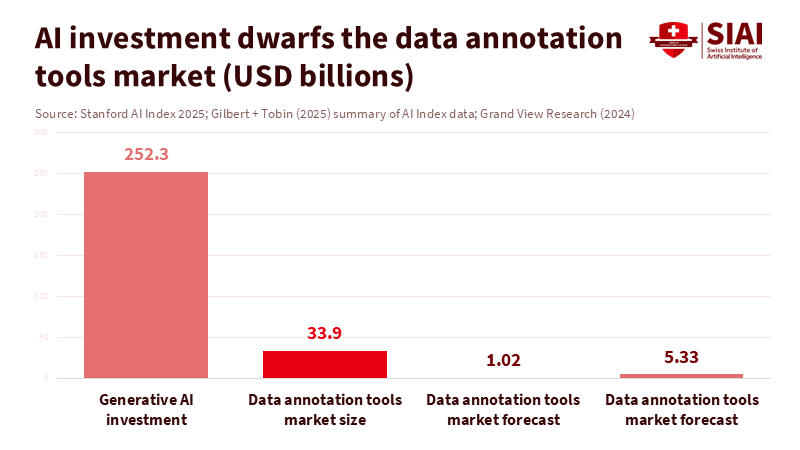
Currently, between 154 million and 435 million people perform the “invisible” tasks that train and manage modern AI systems. They clean up harmful content, label images, and rank model outputs, often earning just a few dollars a day. Meanwhile, private investment in AI reached about $252 billion in 2024, with $33.9 billion directed toward generative AI alone. The global generative AI market is already valued at over $21 billion. One data-labeling company, Scale AI, is worth around $29 billion following a single deal with Meta. This disparity isn’t an unfortunate side effect of innovation; it is the business model. This is AI data colonialism: a digital plantation economy in which workers in the Global South provide inexpensive human intelligence, enabling institutions in the Global North to claim “smart” systems. Education systems are right in the middle of this exchange. The crucial question is whether they will continue to support it or help dismantle it.
AI data colonialism and the new digital plantations
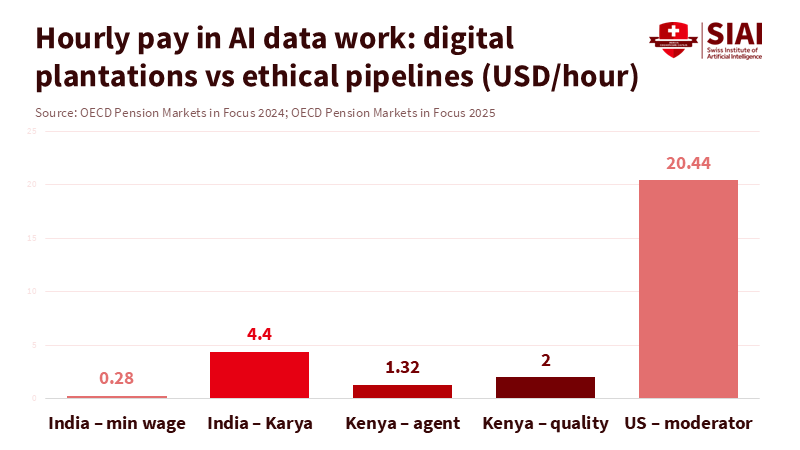
AI data colonialism is more than just a catchphrase. It describes a clear pattern. Profits and decision-making power gather in a few companies and universities that own models, chips, and cloud services. The “raw material” of AI—labeled data and safety work—comes from a scattered workforce of contractors, students, and graduates, many from lower-income countries. Recent studies suggest that this data-labor force is already as large as the entire national labor market, yet most workers earn poverty-level wages. In Kenya and Argentina, data workers who moderate and label content for major AI companies earn about $1.70 to $2 per hour. In contrast, similar jobs in the United States start at roughly $18 per hour. Countries are effectively exporting human judgment and emotional resilience rather than crops or minerals. They import AI systems built on that labor at a premium.
Working conditions in this digital plantation mirror those of the old ones, though they are hidden behind screens. Reports detail workers in Colombia and across Africa handling 700 to 1,000 pieces of violent or sexual content per shift, with only 7 to 12 seconds to decide on each case. Some workers report putting in 18 to 20-hour days, facing intense surveillance and unpaid overtime. A recent study by Equidem and IHRB reveals widespread violations of international labor standards, from low wages to blocked union organizing. A TIME investigation found that outsourced Kenyan workers were earning under $2 per hour to detoxify a major chatbot. New safety protocols introduced in 2024 and 2025 aim to address these issues. However, 81% of content moderators surveyed say their mental health support is still lacking. This situation is not an error in the AI economy; it is how value is extracted. Education systems—ranging from universities to boot camps—are quietly funneling students and graduates directly into this pipeline.
From AI data colonialism to learning-centered pipelines
If we accept the current model, AI data colonialism becomes the default “entry-level job” for a generation of learners in the Global South. Many of these workers are overqualified. Scale AI’s own Outlier subsidiary reports that 87% of its workforce holds college degrees, while 12% have PhDs. These jobs are not casual side gigs; they are survival jobs for graduates unable to find stable work in their fields. Yet their tasks are treated as disposable piecework rather than as part of a structured learning journey into AI engineering, policy, or research. For education, this is a massive waste. It parallels training agronomy students, only to have them pick cotton indefinitely for export.
There is evidence that a different model can work. In India, Karya provides data services that pay workers around $5 per hour—nearly 20 times the minimum wage—and offers royalties when datasets are resold. Karya reports positive impacts for over 100,000 workers and aims to reach millions more. Projects like this demonstrate that data work can connect to income mobility and skill development instead of relying on exploitative contracts. Simultaneously, the market for data annotation tools is growing rapidly, from about $1 billion in 2023 to a projected $5.3 billion by 2030, while the global generative AI market could increase eightfold by 2034. The funding exists. The challenge is whether educational institutions will ensure that data work linked to their programs is structured as meaningful employment focused on learning rather than as digital labor.
Institutions that can break AI data colonialism
Education systems have more power over AI data colonialism than they realize. Universities, vocational colleges, and online education platforms already collaborate with tech companies for internships, research grants, and practical projects. Many inadvertently direct students into annotation, evaluation, and safety tasks framed as valuable experience, often lacking transparency about working conditions. Instead of viewing these roles as a cost-effective way to demonstrate industry relevance, institutions can turn the model on its head. Any student or graduate engaged in data work through an educational program deserves clear rights: a living wage in their local context, limits on exposure to harmful content, mental health support, and a guaranteed path to more skilled roles. This work should count toward formal credit and recognized qualifications, not just as “extra practice.”
Some institutions in the Global South are already heading in this direction through AI equity labs, community data trusts, and cooperative platforms. They design projects where local workers create datasets in their languages and based on their priorities—such as agricultural support, local climate risks, or indigenous knowledge—while gaining technical and governance skills. A cooperative approach, as advocated by proponents of platform cooperativism in Africa, would allow workers to share in the surplus generated by the data they produce. For education providers, this means shifting the concept of “industry partnership” away from outsourcing student moderation and toward building locally owned shared AI infrastructure. That change transforms the dynamic: instead of training students to serve distant platforms, institutions can empower them to become stewards of their own data economies.
Educating against AI data colonialism, not around it
Policymakers often claim that data-intensive jobs are short-term, since automation will soon eliminate the need for human labelers. However, current investment trends indicate otherwise. Corporate AI spending hit $252.3 billion in 2024, with private investment in generative AI reaching $33.9 billion—more than eight times the levels of 2022. The generative AI market, worth $21.3 billion in 2024, is expected to grow to around $177 billion by 2034. The demand for high-quality, culturally relevant data is rising alongside it. Annotation tools and services are also on a similar growth trajectory. Even if some tasks become automated, human labor will remain essential for safety, evaluation, and localization. Assuming that AI data colonialism will disappear on its own simply allows the current model another decade to solidify.
Regulators are beginning to respond, but education policy has not kept up. New frameworks, such as the EU Platform Work Directive, create a presumption of employment for many platform workers and require algorithmic transparency. A global trade union alliance for content moderators has established international safety protocols, advocating for living wages, capped exposure to graphic content, and strong mental health protections. Lawsuits from Kenya to Ghana demonstrate that courts recognize psychological injury as genuine workplace harm. Education ministries and accreditation bodies can build on this momentum by requiring any AI vendor used in classrooms or campuses to disclose how its training data was labeled, the conditions under which it was done, and whether protections for workers meet emerging global standards. Public funding and partnerships should then be linked to clear labor criteria, similar to requirements many already impose for environmental or data privacy compliance.
For educators and administrators, tackling AI data colonialism also means incorporating the labor that supports AI into the curriculum. Students studying computer science, education, business, and social sciences should learn how data supply chains operate, who handles the labeling, and what conditions those workers face. Case studies can showcase both abusive practices and fairer models, like Karya’s earn–learn–grow pathways. Teacher training programs should address how to discuss AI tools with students honestly—not as magical solutions, but as systems built on hidden human labor. This transparency prepares graduates to design, procure, and regulate AI with labor justice in focus. It also empowers students in the Global South to see themselves not just as workers in the digital realm, but as future builders of alternative infrastructures.
The plantation metaphor is uncomfortable, but it effectively highlights the scale of imbalance. On one side, hundreds of millions of workers, often young and well-educated, perform repetitive, psychologically demanding tasks for just a few dollars an hour and without real career advancement. On the other side, a small group of firms and elite institutions accumulate multibillion-dollar valuations and control the direction of AI. This represents the essence of AI data colonialism. Education systems can either normalize it by quietly channeling students into digital piecework and celebrating any AI partnership as progress, or they can challenge it. This requires implementing strict labor standards, investing in cooperative and locally governed data projects, and teaching students to view themselves as rights-bearing professionals rather than anonymous annotators. If we fail, the history of AI will resemble a new chapter of familiar exploitation. If we succeed, education can transform today's digital plantations into tomorrow's laboratories for a fairer, decolonized AI economy.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Abedin, E. (2025). Content moderation is a new factory floor of exploitation – labour protections must catch up. Institute for Human Rights and Business.
Du, M., & Okolo, C. T. (2025). Reimagining the future of data and AI labor in the Global South. Brookings Institution.
Grand View Research. (2025). Data annotation tools market size, share & trends report, 2024–2030.
Okolo, C. T., & Tano, M. (2024). Moving toward truly responsible AI development in the global AI market. Brookings Institution.
Reset.org (L. O’Sullivan). (2025). “Magic” AI is exploiting data labour in the Global South – but resistance is happening.
Startup Booted. (2025). Scale AI valuation explained: From startup to $29B giant.
Stanford HAI. (2025). 2025 AI Index report: Economy chapter.
TIME. (2023). Exclusive: OpenAI used Kenyan workers on less than $2 per hour to make ChatGPT less toxic.
UNI Global Union / TIME. (2025). Exclusive: New global safety standards aim to protect AI’s most traumatized workers.
Karya. (2023–2024). Karya impact overview and worker compensation.
Keith Lee is a Professor of AI/Finance at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). His work focuses on AI-driven finance, quantitative modeling, and data-centric approaches to economic and financial systems. He leads research and teaching initiatives that bridge machine learning, financial mathematics, and institutional decision-making.
He also serves as a Senior Research Fellow with the GIAI Council, advising on long-term research direction and global strategy, including SIAI’s academic and institutional initiatives across Europe, Asia, and the Middle East.




















Comment