AI Energy Efficiency in Education: The Policy Lever to Bend the Power Curve

Published
Modified
AI energy use is rising, but efficiency per task is collapsing Education improves outcomes by optimizing energy usage and focusing on small models.Do this, and costs and emissions fall while learning quality holds

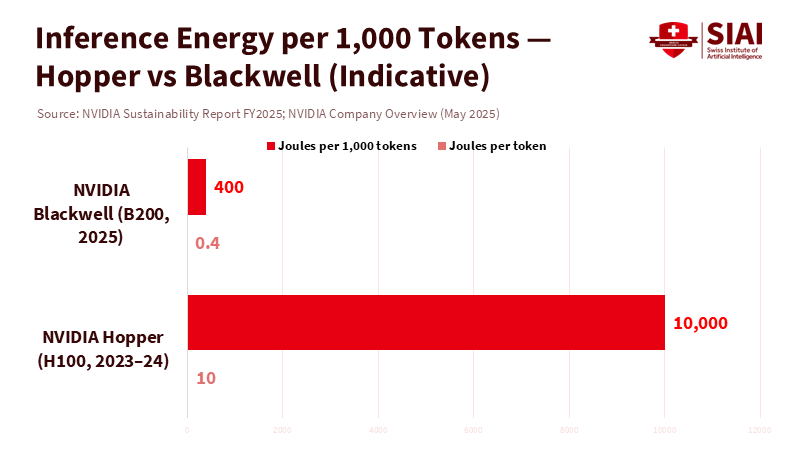
The key figure in today's discussion about AI and the grid isn't a terawatt-hour forecast but 0.4 joules per token, a number that reframes AI energy efficiency in education. This is the energy cost that NVIDIA now reports for advanced inference on its latest accelerator stack. According to the company's own long-term data, this shows about a 100,000-fold efficiency improvement in large-model inference over the past decade. However, looking at this number alone can be misleading. Total electricity demand from data centers is still expected to rise sharply in the United States, China, and Europe as AI continues to grow. But it changes the perspective. If energy usage per unit of practical AI work is decreasing, then total demand is not fixed; it's something that can be influenced by policy. Education systems, which are major consumers of edtech, cloud services, and campus computing, can establish rules and incentives that transform quick efficiency gains into reduced bills, lower emissions, and improved learning outcomes. The decision isn't about choosing between growth and restraint; it's about managing growth versus prioritizing efficiency in a way that also increases access to resources.
AI Energy Efficiency in Education: From More Power to Better Power
The common belief is that AI will burden the grids and increase emissions. Critical analyses warn that, without changes to current policies, AI-driven electricity use could significantly increase global greenhouse gas emissions through 2030. Models at the regional level forecast significant increases in data center energy use, with roughly 240 TWh in the United States, 175 TWh in China, and 45 TWh in Europe, compared to 2024 levels, by the end of the decade. These numbers are concerning and highlight the need for investment in generation, transmission, and storage. Yet these assessments also acknowledge considerable uncertainty, much of which relates to efficiency. This includes how quickly computing power per watt improves, how widely those improvements spread, and how much software and operational practices can reduce energy use per task. The risk is real, but the slope of the curve is not set in stone.
The technical case for a flatter curve is increasingly evident. Mixture-of-Experts (MoE) architectures now utilize only a small portion of parameters for each token, thereby decreasing the number of floating-point operations (flops) without compromising quality. A notable example processes tokens by activating approximately 37 billion out of 671 billion parameters, which significantly reduces computing needs per token, supported by distillation that transfers reasoning skills from larger models to smaller ones for everyday tasks. At the system level, techniques such as speculative decoding, KV-cache reuse, quantization to 4–8 bits, and improved batch scheduling all further reduce energy use per request. On the hardware front, the transition from previous GPU generations to Blackwell-class accelerators delivers significant speed gains while using far fewer joules per token. Internal benchmarks indicate substantial improvements in inference speed, accompanied by only moderate increases in total power.
Additionally, major cloud providers now report fleet-wide Power Usage Effectiveness (PUE) of nearly 1.1, which means that most extra energy use beyond chips and memory has already been minimized. Collectively, this represents an ongoing optimization process—from algorithms to silicon to cooling systems—that continues to drive down energy usage per beneficial outcome. Policy can determine whether these savings are realized.
AI Energy Efficiency in Education: What It Means for Classrooms and Campuses
Education budgets are feeling the impact of AI, with expenses including cloud bills, device updates, and hidden costs such as latency and downtime. An efficiency-first approach can make these bills smaller and more predictable while increasing access to AI support, feedback, and research tools. The first step is to establish procurement metrics that monitor energy per unit of learning value. Instead of simply purchasing "AI capacity," ministries and universities should aim to buy tokens per watt or joules per graded essay, with vendors required to specify model details, precision, and routing strategies. When privacy and timing allow, it's best to default to smaller distilled models for routine tasks like summaries, grammar checks, and feedback aligned with rubrics, saving larger models for specific needs. This won't compromise quality; it reflects how MoE systems function internally. With effective routing, a campus can handle 80–90% of requests with smaller models and switch to larger ones only when necessary, dramatically reducing energy use while maintaining quality where needed. A simple calculation using the published energy figures for new accelerators shows that moving a million-token daily workload from a 5 J/token baseline to 0.5 J/token—through distillation, quantization, and hardware upgrades—could save about 4.5 MWh per day before considering PUE adjustments. Even at an already efficient ~1.1 PUE, this represents significant budget relief and measurable reductions in carbon emissions.
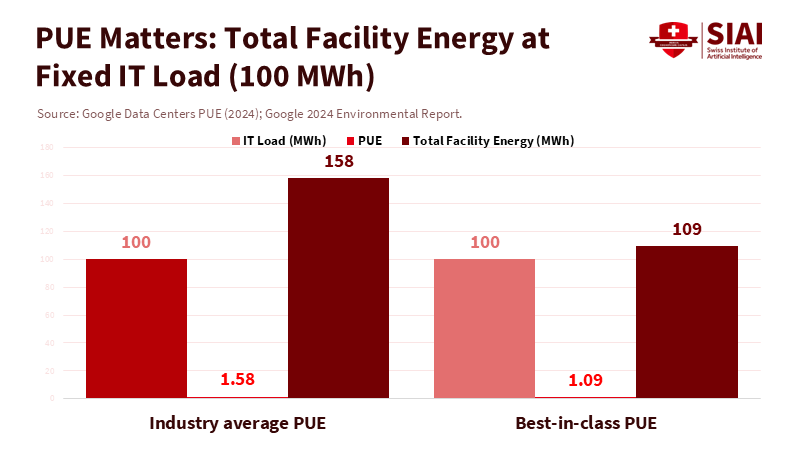
Secondly, workload management should be included in edtech implementation guides. Many uses of generative AI in education occur asynchronously—such as grading batches, generating prompts, and cleaning datasets—so grouping tasks and scheduling them during off-peak times can reduce the load without affecting users. Retrieval-augmented generation (RAG) reduces token counts by incorporating relevant snippets, rather than requiring models to derive responses from scratch. Speculative decoding enables a lighter model to generate tokens, which a heavier model then verifies, thereby boosting throughput while reducing energy use per output. Caching prevents the need to repeat system prompts and instructions across different groups. None of these requires the latest models; they need contracts that demand efficiency. Partnering with cloud providers that have best-in-class PUE and ensuring campuses only use on-prem servers when necessary can turn technical efficiency into policy efficiency: lowering total energy while achieving the same or better learning outcomes.
Bending the curve, not the mission
Critics may raise the concern of rebound effects: if we cut the energy required for an AI query by 10 times, won't usage rise by 10 times, negating the savings? Sometimes yes. But rebound is not an absolute rule, especially when buyers enforce limits. Public education can establish budget-based guidelines, such as caps on tokens per student aligned with educational objectives, and a tiered model routing that only escalates when the value demands it. Just as printers evolved from unmanaged to managed queues, AI requests can operate under quality-of-service guidelines that prioritize efficiency and reliability. The overall forecasts that trouble us most assume current practices will remain in place; changing the practices will change the estimates. Moreover, when usage increases for legitimate reasons—such as broader access and improved instruction—efficiency ensures that the extra energy used is lower per unit of learning than it would have been, which reflects responsible scaling.
Another critique is that claims of efficiency are overstated. It's smart to question the numbers. However, various independent assessments point in the same direction. Vendor reports reveal significant improvements in joules per token for recent accelerators, and third-party evaluations analyze these speed claims, showing that while overall rack power might increase, the work done per unit of energy rises at a much faster rate. Additionally, peer-reviewed methods are emerging to measure model performance in terms of energy and water use across various deployments. Even if any single claim is overly optimistic, the trend is clear, and different vendors can replicate the combination of architectural efficiency, distillation, and hardware co-design. For education leaders, the best approach is not disbelief; it's conditional acceptance: create procurement policies that reward demonstrated efficiency and penalize unclear energy use.
A third concern is infrastructure; schools in many areas face rising tariffs and overloaded grids. That's precisely why workload placement is crucial. Keep privacy-sensitive or time-critical tasks on energy-efficient local devices whenever possible; send batch tasks to cloud regions with cleaner grids and better cooling systems. Require vendors to disclose region-specific emission metrics and give buyers choices. Where a national cloud or academic network is available, education ministries can negotiate sector-wide rates and efficiency commitments, including plans for carbon-intensity disclosures per thousand tokens. This isn't unnecessary bureaucracy; it's modern IT management for a resource that is limited and costly.
Some may wonder if high-profile efficiency cases, such as affordable, effective chatbots, are exceptions. They are indications of what's possible. A notable case achieves competitive performance at a fraction of the cost of conventional computing by leveraging routing efficiency, targeted distillation, and hardware-aware training. Independent industry analysis credits its efficiency not to miraculous data but to solid engineering. As these techniques become more widespread, they redefine the efficient frontier for inference costs relevant to education—such as translation, formative feedback, concept checks, and code explanations—where smaller and mid-sized models already perform well if appropriately designed and fine-tuned on carefully chosen data. The policy opportunity is to connect contracts to that frontier so that savings are passed through.
Lastly, there is the challenge posed by climate change. Predictions of AI-related emissions growth are not mere scare tactics; they serve as alerts about a future without discipline in efficiency. If we take no action, power consumption by data centers will continue to rise into the 2030s, and some areas will revert to higher carbon generation to meet peak demands. If we do take action—by establishing efficiency metrics, timing workloads intelligently, and relocating computing resources wisely—education can seize the benefits of AI while reducing the energy required for each learning gain. This isn't just a financial story; it's a matter of credibility for the sector. Students and families will notice whether schools truly embody the sustainability principles they teach.
So, what should leaders do right now? First, revise requests for proposals (RFPs) to make energy per outcome a key criterion for awards, complete with clear measurement plans and third-party audit rights. Second, default to small models using distilled or MoE-routing for routine tasks and only escalate to larger models based on explicit policies. Implement management strategies to handle prompts and caches, minimizing recomputation. Third, partner with organizations that maintain a PUE close to 1.1 and have documented plans for joules per token, while also insisting on region-specific carbon intensity disclosures for hosted workloads. Fourth, strengthen internal capabilities: a small "AI systems" team to tune routing, batch jobs, and RAG pipelines is far more valuable than another generic SaaS license. Fifth, educate: help faculty and students understand why efficiency is equivalent to access and how choices regarding prompts, model selection, and timing impact energy use. This is how education can evolve AI from a flashy pilot into lasting infrastructure.
The final test is straightforward. If, two years from now, your campus is using significantly more AI but spending less per student on energy and emitting less per graduate, you will have bent the curve. The technology already provides the tools: a sub-joule token in the data center, a distilled model on the device, and an MoE gate that only processes what's necessary. The policy work involves placing the fulcrum correctly—through contracts, metrics, and operations—and then applying pressure. The conversation about whether AI inevitably requires ever more energy will continue, but in education, we don't need inevitability; we need results. The key figure to monitor is not solely terawatt-hours but the energy per learning gain. With focus, that number can continue to decrease even as access increases. That's the future we should strive for.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bain & Company. (2025). DeepSeek: A Game Changer in AI Efficiency? (MoE routing and distillation details).
Brookings Institution. (2025, Aug. 12). Why AI demand for energy will continue to increase. (Context on the drivers of rising aggregate demand and unit-efficiency trends).
Google. (2024, July). 2024 Environmental Report; Power Usage Effectiveness (PUE) methodology page (fleet-wide PUE ~1.09).
International Energy Agency. (2025, Apr. 10). Energy and AI; Energy demand from AI (regional projections to 2030 for data-center electricity use).
International Monetary Fund. (2025, May 13). AI Needs More Abundant Power Supplies to Keep Driving Economic Growth (emissions implications under current policies).
NVIDIA. (2025, Jun. 11). Sustainability Report, FY2025 (long-run efficiency trend; ~0.4 J/token reference).
Zilliz/Milvus. (2025). How does DeepSeek achieve high performance with lower computational costs? (architecture and training optimizations that generalize).
Zhou, Z. et al. (2025, May 14). How Hungry is AI? Benchmarking Energy, Water, and Environmental Footprints of LLM Inference (infrastructure-aware benchmarking methods).





















Comment