India growth momentum is strong, but its durability depends on education reform
Investment gains will fade unless skills systems scale with industry demand
The real test is whether growth becomes long-term capability
The Cost of Hurry: Why the speed of AI adoption is a policy choice with winners, losers—and no shortcuts
Picture
Member for
5 months 3 weeks
Real name
Erik Van der Meer
Bio
External Fellow, SIAI Science Review - AI/Science
Erik Van der Meer examines how scientific knowledge is produced, validated, and institutionalized across disciplines. His writing explores the structure of modern science, the evolution of research norms, and the interaction between technology and scientific epistemology. He contributes reflective essays on science itself—bridging hard research and meta-level analysis.
Published
Modified
AI speed is a policy choice, not a universal race
Rushing adoption can deepen inequality and strain education systems
Measured AI adoption builds lasting capacity and stability
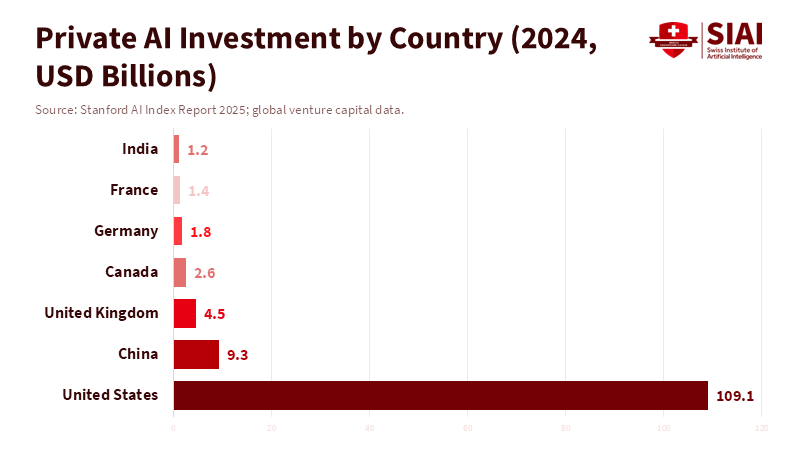
In 2024, the United States saw a substantial amount of private capital flow into AI, far surpassing that of any other country. Approximately $109.1 billion in new private funding was invested, about 12 times the $9.3 billion China invested that year. This has led to a concentration of talent, computing power, and market power in a small group of leading companies. This unevenness is significant because being a leader in tech isn't usually about just one brilliant idea. It depends on having a robust system that includes money, substantial power, talented people, and the ability to try things that might be expensive failures. When you have a lot of resources in one place, you can move fast. But if you don't have those resources, trying to move fast can be a disaster. So, every education official, college leader, and job market planner needs to think not about whether AI will change things, but how quickly we can adapt our systems to handle those changes. Trying to go fast without having the right resources means sacrificing important things in the future to look good today. It leaves teachers, experienced workers, and entire economies struggling to keep up with a disadvantage.
Why it's important to think about how fast we adopt AI
People often talk about adopting AI like it's an all-or-nothing situation: either you jump in, or you get left behind. But that's not the whole story. How fast you adopt AI can actually make existing advantages even bigger. If you already have a lot of money, strong research centers, and plenty of cloud computing, you can not only use AI models, but also mold the standards, data processes, and even the kind of talent that's considered normal. This creates a situation where the first movers set the rules. What's taught in schools, the qualifications people need, and even job descriptions start to reflect the tools and methods used by those leading companies, instead of what most schools or firms can actually manage. For schools that need to serve everyone, the pressure is on to copy those tools in the classroom. This can mean buying cloud services, installing expensive equipment, and hiring a few specialists. Meanwhile, the majority of teachers don't get the support they need. This turns updating education into a fancy project for a select few, instead of a real improvement for everyone.
There's another reason why speed is important: money. To go all-in on AI, countries need to invest in data centers, skilled trainers, software licenses, and a reliable power supply. If governments or universities focus on short-term benefits instead of building a solid base, they could end up with financial problems later on. Public budgets are already tight, and adopting AI quickly can increase costs, which can be hard to see at first. At the same time, the benefits, like better productivity, new courses, and improved learning, usually take time to show up. If a government borrows money to build a fancy AI center but can't find the people to run it or the power to keep it going, that center becomes a waste of money. This is already happening in places where private AI investment is high, but public finances are stretched. Going fast isn't the same as being able to include everyone in a way that's affordable.
A world of different speeds for AI adoption
The world is dividing into three groups regarding AI. The first is the superpowers that are racing ahead. In this case, companies and countries are competing intensely to be the leader in AI platforms. They're willing to spend a lot of money to win, even if it's risky. For them, moving fast makes their lead even bigger. Their education systems will likely prioritize state-of-the-art research and retraining programs for a select few. This could increase inequality within those countries, but they can handle the risks and costs of leading the way in AI. They see their investments as part of a larger plan, not just one-time experiments.
Figure 1: AI capital flows remain heavily concentrated, reinforcing a structural two-speed global system in the race to scale.
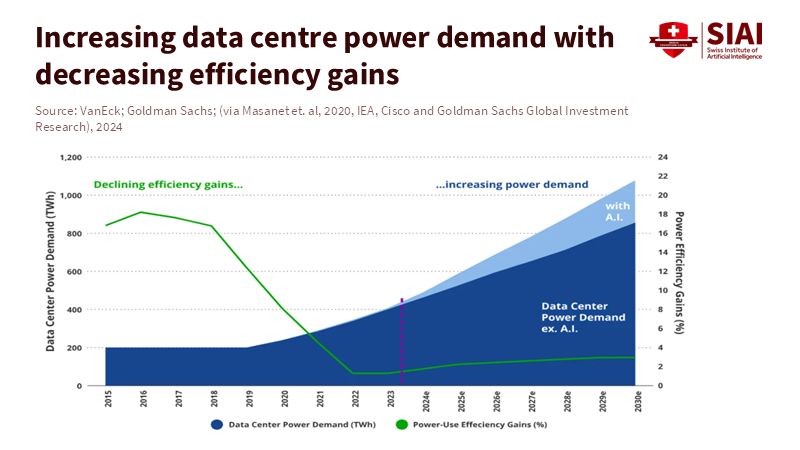
The second group is small and middle-income countries. For them, trying to keep up with the leaders can be a huge struggle. They face three problems: they lack sufficient private capital or cloud and chip infrastructure to reduce costs. They also have gaps in skills, especially among older workers. This means that rapid adoption of machines and AI can displace older workers, and they may find it difficult to transition to a new career. According to research by Neumark, Burn, and Button, there is strong evidence that older women, particularly those approaching retirement age, face age discrimination when trying to find jobs. Additionally, these countries frequently have limited budgets, so allocating funds for AI infrastructure can reduce the money available for social and educational programs. This creates a difficult situation: they must choose between allocating funds to emulate AI leaders and investing in foundational systems. The infrastructure reality makes the pace question unavoidable. Data centre electricity demand is accelerating sharply, even as efficiency gains flatten compared to earlier years. Rapid AI scaling now requires sustained capital, reliable grids, and long-term energy planning — resources not evenly distributed across countries.
Figure 2: Electricity demand from data centres is projected to surge this decade while efficiency improvements slow, increasing the structural cost of rapid AI expansion.
The third group is a large middle zone, which is everyone else. These countries aren't racing ahead, but they're also not maintaining their basic capabilities. Without a clear plan, they risk slowly falling behind. Public research doesn't receive sufficient funding, companies lack access to high-quality AI models, and the job market loses middle-skill jobs without providing adequate options for people to find new work. These countries become dependent on AI services provided by others and lose control over standards and data use. The message for them is clear: going fast without having the resources to do it right isn't a way to become competitive.
These three groups aren't about judging which is better or worse. It's about understanding the financial and organizational realities they face. Moving fast makes sense if you control the infrastructure and can afford to take losses. But for everyone else, the right question isn't How fast can we adopt AI? but How can we learn at a pace that allows us to adapt? Going slow doesn't mean doing nothing. It means taking steps in the right order: first, invest in helping teachers understand technology, then redesign courses to focus on solving problems, and finally provide reliable power and internet access. Then, you can start using AI platforms. This approach reduces the risk of wasting money and makes it possible to speed things up later in a way that makes sense.
What the speed of AI adoption means for educators, administrators, and policymakers
Educators need to determine what's most important to teach about AI. A good rule is to focus on skills that will last. Critical thinking, judgment, supervising AI models, and understanding data are skills that will be useful regardless of the tools available. Courses that teach people how to work with AI, like how to write instructions for AI, how to evaluate what AI produces, and how to oversee decisions made with AI, are helpful. But they shouldn't replace a solid foundation in other subjects. Buying many specific classroom tools can trap schools into using them, and it can be hard for teachers to adopt them. Instead, schools should focus on training teachers and creating course materials that gradually include AI tools, with ways to measure how well they're working.
Administrators and finance teams need to consider how quickly they plan to adopt AI when setting budgets. When universities or school systems are planning to buy AI tools, they should carefully consider the costs of running them. This includes energy use, license renewals, technical staff, and equipment replacement. Rapidly adopting AI often shifts costs from one-time investments to ongoing expenses, which can be difficult to cut later. A better approach for systems with limited money is to take things slowly. Start with small experiments, measure how well they're working and how they affect the job market, train people, and then expand. International cooperation should focus on building capabilities rather than just donating equipment. Donating equipment without training and a budget to keep it running creates dependence, not self-reliance.
Policymakers need to think about how people will transition to new jobs, especially older workers. Studies show that older workers face challenges finding new jobs as automation and AI replace their roles. Just retraining older workers quickly often doesn't work because of difficulties related to learning, location, and finances. Better approaches include offering options for gradual retirement, retraining people for local jobs, and offering credentials that recognize their prior experience. Social insurance and wage subsidies can provide support as people adjust, and programs that help them find new jobs can increase their chances of employment. These measures cost money, but they're cheaper than the cost of mass unemployment and social problems caused by adopting AI too quickly.
A practical plan: taking things in the right order, being honest about costs, and adopting AI at a measured pace
A plan that treats speed as a tool, not a race, has three main parts. First, take things in the right order. Focus on providing reliable power, universal internet access, teacher training, and open standards. These are the things that make adopting AI later on more effective and affordable. Second, be honest about the costs. Consider the total cost of owning AI tools, not just the initial investment. Include energy, staff, and replacement cycles. If a government borrows money to build fancy AI centers without a realistic plan for running them, it creates problems for the future. Third, regulate access wisely. Make sure that purchasing favors systems that can work with other systems, encourage shared computing facilities, and require educational licenses that allow for research, reuse, and evaluation. These steps lower the initial cost and increase the chances for learning.
International partners and organizations can help by shifting their focus from donating equipment to building lasting capabilities. Grants or loans should fund teacher training, regional computing centers, and curriculum development, rather than just individual AI centers at universities. When offering financial support, set measurable goals, such as teacher certification rates, improvements in learning outcomes, and job placement rates, so that success can be measured. This is how to turn good intentions into real benefits for the public.
Finally, the speed of AI adoption must be a democratic decision. Decisions about how quickly to adopt AI are political choices that affect different groups and regions. Open discussions among teachers' unions, universities, industry, and the public can reduce the risk that AI adoption becomes a project for a select few. When educators and communities are involved, the pace is more likely to protect jobs while allowing innovation to continue.
Remember that substantial private investment has already created a situation in which only a few can afford to move quickly with AI. For everyone else, trying to keep up is a risky bet. The alternative isn't to reject AI, but to choose a responsible pace, proceed in the right order, budget honestly for operating costs, and protect workers. Educators, administrators, and policymakers should focus on supporting teachers and on teaching skills that endure. Getting the pace wrong will not only delay the benefits of AI but will also worsen inequality, create stranded assets, and weaken the ability to manage technology. Getting it right means using a measured pace as a plan for inclusion, making decisions based on evidence, and focusing on the good of the public.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
BBC News (2024) US power grid faces strain from AI-driven electricity demand. BBC News. Brookings Institution (2024) Why Africa should sequence, not rush into AI. Brookings Institution. International Monetary Fund (IMF) (2025) Global Debt Monitor 2025. International Monetary Fund. Organisation for Economic Co-operation and Development (OECD) (2024) Promoting Better Career Choices for Longer Working Lives. OECD Publishing. Organisation for Economic Co-operation and Development (OECD) (2025) Emerging divides in the transition to artificial intelligence. OECD Publishing. Reddit (2025) The AI is so fucked you can’t play small nations. EU5 Discussion Forum. Stanford Institute for Human-Centered AI (HAI) (2025) AI Index Report 2025. Stanford University. VanEck (2024) Who’s winning the AI rush?. VanEck Vectors Insights.
Picture
Member for
5 months 3 weeks
Real name
Erik Van der Meer
Bio
External Fellow, SIAI Science Review - AI/Science
Erik Van der Meer examines how scientific knowledge is produced, validated, and institutionalized across disciplines. His writing explores the structure of modern science, the evolution of research norms, and the interaction between technology and scientific epistemology. He contributes reflective essays on science itself—bridging hard research and meta-level analysis.
America First tariffs avoided an immediate recession but shifted trade into geopolitical strategy
Short-term stability hides real household costs and long-run productivity risks
The real test is whether tariffs build lasting capacity without weakening institutions
Speculation cannot fix structural affordability
Stablecoins may look stable but can shift systemic risk
Real reform requires stronger incomes and safer credit systems
High public debt is weakening the power of the zero lower bound in Europe
When fiscal credibility erodes, lower interest rates no longer guarantee stronger growth or stable inflation
Europe must rebuild fiscal space and institutional trust if monetary policy is to work again
Copyright’s Quiet Pivot: Why AI data governance — not fair use — will decide the next phase of legal rules
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
AI copyright disputes are shifting toward strict AI data governance and data provenance scrutiny
Settlements and licensing deals now shape the legal landscape more than courtroom doctrine
The future of AI regulation will depend on verifiable governance, not abstract fair-use theory
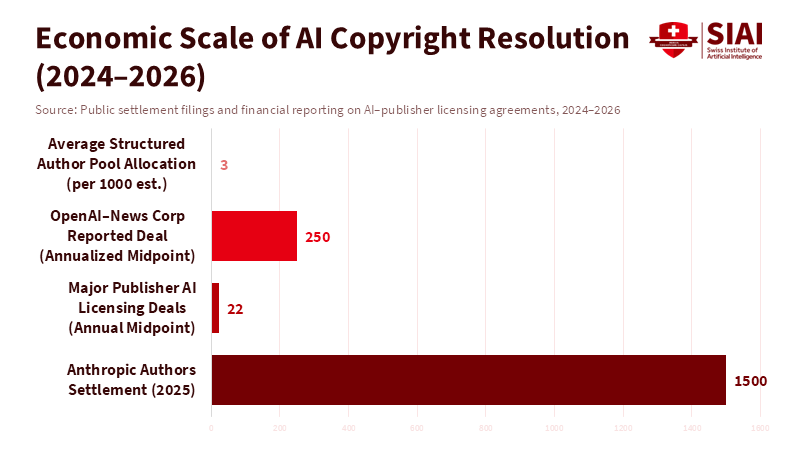
When authors and publishers went to court with AI developers, everyone thought we'd get clear answers about if it's okay to train AI using copyrighted stuff. But that's not how it's turning out. By late 2025, a big case didn't end with some fancy legal rule, but with a deal: a judge gave the thumbs up to a roughly $1.5 billion agreement between authors and an AI company. The issue was that the AI allegedly used about 465,000 books to train its models. That huge number tells us something important: not knowing the rules is costing people a lot. So, companies, publishers, and even the courts are starting to focus on something simple: can you prove where the data came from, how you got it, and that it's legit? They're not trying to make some grand statement about fair use. This isn't some legal trick. It's a big change in how we handle AI data, which is becoming the key to being responsible.
AI Data Management and the Changing Legal World
Previously, people thought copyright and AI were a simple yes-or-no question: is using copyrighted material to train AI fair, or is it against the law? That question sparked significant debate among experts and a few court opinions, but it didn't really help businesses figure things out. But in 2024 and 2025, courts began examining the same facts in a new way. Judges wanted real proof about where the data came from, what agreements covered it, whether anyone was using pirated materials, and whether you could trace what the AI produced back to specific copyrighted works. These aren't just abstract legal ideas; they're practical things companies can check. And that's important because companies can take action on this. They can maintain records, conduct audits, obtain licenses, and demonstrate the source of their data. They can't go back in time and change the Constitution. Companies with strong AI data management will face less legal risk and have a better reputation than those that don't.
According to AP News, some rights holders are now seeking to monetize through licensing agreements and business deals rather than relying solely on uncertain and lengthy court cases. And the market is reacting. By mid-2025 and into 2026, major publishers and news services were entering into business agreements with AI developers. These big deals showed everyone that there's money to be made. For AI developers who have billions on the line, paying to get data legally or at least showing they have a good reason to believe their data is legit is better than risking a court decision that cuts them off from important data. The legal fight is shifting from "Is this legal?" to "Can you prove where you got this?" And that's where AI data management comes in.
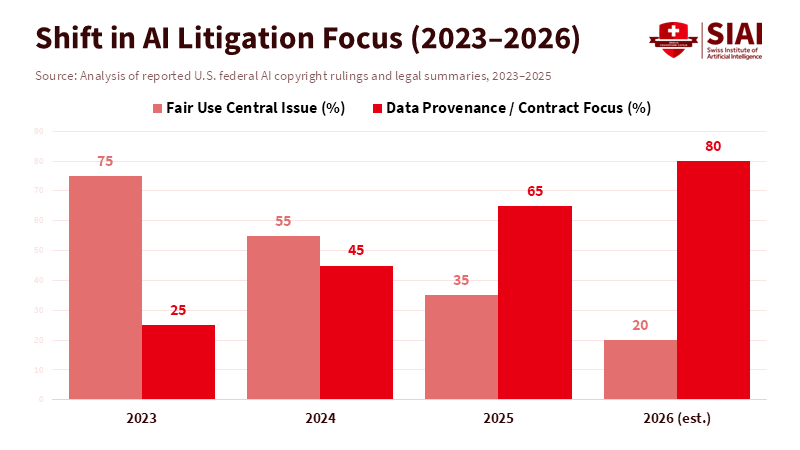
Figure 1: Courts are narrowing the battlefield: abstract fair-use claims are declining as data provenance becomes the central legal test.
AI Data Management: Agreements, Licenses, and What the Market is Saying
The numbers are pretty amazing and tell us a lot. A settlement of approximately $1.5 billion in 2025, which was agreed upon rather than won in court, isn't just about getting paid back. It's a sign of what things are worth. It tells the people in charge of risk, the people on the board, and the people buying AI what it might cost if they don't follow the rules, and how valuable it is to have a data supply chain that you can trust. At the same time, large licensing deals between publishers and AI companies began to emerge, and the reported prices indicate that the market is rising. Major publishers are reportedly receiving millions of dollars each year for allowing AI companies to use their content, and one deal was reportedly worth $20–$25 million annually. These numbers aren't always clear, and many agreements aren't public, but the trend is evident: rights holders are getting money through contracts while the legal disputes are more about the specific facts of each case.
The courts are also helping this trend. Throughout 2025, several court decisions emphasized the details of how data was changed, accessed, and where it came from, rather than making broad general rules. In other words, the courts often didn't make a big statement about fair use, but they did make it clear that they wanted to see proof of how the data was obtained and used. This creates a predictable legal situation: if judges require proof of data origin, those who can provide it have greater leverage in negotiations, and those who can't are more likely to settle. For the people making the rules and for institutions, this means that you can prevent problems and measure how well you're doing. If a company keeps track of who gave them data, what agreements covered it, what changes were made, and how they verify that copyrighted material isn't being copied, they'll be in a better position to avoid expensive settlements or being told to stop.
AI Data Management for Schools and Organizations
If courts and the market agree that it's important to know where data comes from and to have clear agreements, then schools and universities need to make AI data management a top priority. Universities and educational companies are in a unique position: they create valuable training materials (such as lesson plans, research, and lecture recordings) and rely heavily on data from others. A good management plan should have at least three things. First, know what you have and where it came from: every dataset used in a model should be logged with basic information such as its source, licensing terms, capture date, and whether permission was granted. Second, have clear agreements: licensing and data-sharing agreements should state that model training is permitted and specify who gets credit, how funds will be shared, and how the data can be used. Third, be able to audit and control changes: schools should use reliable systems that record data changes and allow external auditors to verify that copyrighted content wasn't copied without permission.
These are real steps, not just good ideas. For example, a textbook company considering partnering with an AI company can determine whether offering a licensed feed for model training will generate more revenue than it costs to manage the rights. Similarly, a university developing its own AI tools can use models trained on data it can verify as clean, reducing its insurance costs, legal fees, and reputational risk. The government can help by supporting shared resources such as licensing marketplaces, standardized methods for recording data origins, and integrated audit tools. These shared resources lower costs and reduce the temptation to take advantage of the system while still protecting creators' rights. To put it simply, good AI data management is also good for the economy.
Figure 2: The economics are too large to risk precedent: licensing and settlements now dominate AI copyright strategy.
AI Data Management: Addressing Concerns and Establishing Norms
Some worry that settlements and private licensing will only benefit big companies and create a system in which only those who can pay get access, thereby limiting the flow of information. That's a valid concern. If only big publishers can profit from their archives, smaller creators might be left out, which could harm the public interest. But the alternative – a free-for-all where everyone grabs data without permission, leading to lawsuits – has its own problems: it erodes trust, causes unpredictable takedowns, and leads to models trained on unreliable data. The solution isn't one or the other. It needs to combine market contracts with public safeguards. That means being watchful for antitrust issues to prevent licensing that excludes others, supporting exemptions for research under clear rules, and requiring transparency so that outsiders can check whether models use licensed or unlicensed content.
Some people argue that management rules will be circumvented or become so costly that they slow innovation. The answer is to adjust based on the evidence. Simple, cheap ways to show where data came from – like a register of datasets that machines can read and a tiered licensing system – can get most of the benefits of compliance without a lot of red tape. When private markets don't provide broad access for research and education, public money can create curated, licensed datasets for non-commercial use. And the courts will still be important. Narrow rulings that focus on the facts of each case and emphasize where data came from aren't a replacement for laws, but they do influence how the market behaves. The combination of court oversight, negotiated contracts, and policy support makes it harder to claim ignorance as a defense and more appealing to build compliance into product design from the outset.
The $1.5 billion settlement is a crude measure that signals a more delicate situation: legal disputes over AI are shifting from abstract arguments to real-world actions. For creators, companies, and schools, the main question has become whether models can prove, with records and contracts, where their data came from and how it was handled. That's what AI data management provides. Policymakers should stop asking only whether training is fair in theory and start setting minimum standards for data provenance, funding shared licensing resources, and protecting non-commercial research channels. Schools should manage their archives, document them, and, when appropriate, monetize them under standard terms. Industry should use data formats that work together and independent audit systems. If we do this, the market will reward clarity. If we don't, we'll end up with costly settlements, broken norms, and a legal environment that discourages innovation rather than guides it. The challenge ahead isn't just legal or technical. It's a management problem that we can solve – if we create the systems to prove it.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Associated Press (2025) ‘Judge approves $1.5 billion copyright settlement between AI company Anthropic and authors’, Associated Press, 2025. Debevoise & Plimpton LLP (2025) AI intellectual property disputes: The year in review. New York: Debevoise & Plimpton. Digiday (2026) ‘A 2025 timeline of AI deals between publishers and tech’, Digiday, 2026. Engadget (2025) ‘The New York Times and Amazon’s AI licensing deal is reportedly worth up to $25 million per year’, Engadget, 2025. European Parliament (2025) Generative AI and copyright: Training, creation, regulation. Directorate-General for Citizens’ Rights, Justice and Institutional Affairs. Brussels: European Parliament. IPWatchdog (2025) ‘Copyright and AI collide: Three key decisions on AI training and copyrighted content’, IPWatchdog, 2025. JDSupra (2025) ‘Fair use or infringement? Recent court rulings on AI training’, JDSupra, 2025. Meta Platforms, Inc. & Anthropic PBC litigation reporting (2025) ‘Meta and Anthropic win legal battles over AI training; the copyright war is far from over’, Yahoo Finance, 2025. Pinsent Masons (2025) ‘Getty Images v Stability AI: Why the remaining copyright issues matter’, Pinsent Masons Out-Law, 2025. Reuters (2024) ‘NY court rejects authors’ bid to block OpenAI cases from NYT, others’, Reuters, 2024. Reuters (2024) ‘OpenAI strikes content deal with News Corp’, Reuters, 2024. Skadden, Arps, Slate, Meagher & Flom LLP (2025) Fair use and AI training: Two recent decisions highlight fact-specific analysis. New York: Skadden. TechPolicy Press (2025) ‘How the emerging market for AI training data is eroding big tech’s fair-use defense’, TechPolicy Press, 2025.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
China’s domestic deflation is no longer contained; it now reshapes global prices, profits, and financial risk
Industrial subsidies extend price pressure, turning a trade shock into a systemic financial spillover
Global policy must adapt quickly to manage a deflationary force emanating from the world’s manufacturing center
Appetite is not a single switch but a network that can now be powerfully overridden
Multi-pathway obesity drugs deliver record weight loss while introducing new biological risks
Policy and education must adapt as fast as the science does
The Super Bowl Is PR — The Enterprise Buys the Orchestration Layer
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
Enterprise AI competition is decided inside procurement systems, not public ad campaigns
The real battle is over who controls enterprise AI orchestration and workflow integration
Governance, interoperability, and institutional trust now matter more than model branding
Enterprise artificial intelligence (AI) management is like a concealed competition. It determines if a business adds a pre-made chatbot or completely restructures its operations around a new kind of tech foundation. A trusted forecast suggests businesses will spend heavily on AI, with hundreds of billions in 2025. But there are warnings that many AI projects, almost half, might fail before they ever generate lasting value. These two facts, the huge potential spending and the risk of failure, change things. Big public displays, like Super Bowl ads, can improve brand image and pique customer interest. But they don't materially affect the checklists, integration plans, or compliance rules important to purchasing departments. The true competition isn't about who has the most amusing ad, but about who becomes the go-to management system for business processes. That's where the real control, consistent income, and long-term market dominance are established.
Where the Real Buying Power Lies: Enterprise AI Management
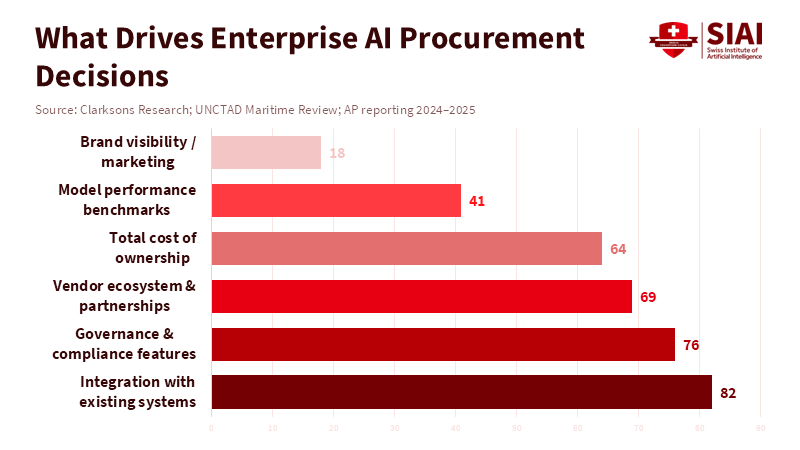
The discussions that matter most to tech chiefs and purchasing teams are very functional. What they care about includes connectors, audit trails, the risk of being locked into a single vendor, how quickly the system responds to key operations, and how much responsibility a vendor takes for AI errors. Another consideration is which vendor has the right relationships to integrate with systems such as SAP, Salesforce, Workday, and airline reservation platforms. Vendors who can supply solid connectors, role-driven access controls, and clear options for data storage will win deals. This isn't just a theory. Top-tier business platforms are already selling themselves as management systems. They glue AI models into workflows and connect them with a company's data resources. OpenAI's recent introduction of the Frontier platform, designed as a business-focused AI management product for early adopters, signals a shift from model-to-model competition to platform-to-platform competition.
Figure 1: Enterprise buyers prioritize integration and governance over brand visibility when selecting AI platforms.
Note that the buying process in large companies is long and complex. For every flashy ad campaign, there is a purchasing spreadsheet, a security review, and a test project. According to Workmate, testing phases vary widely depending on project complexity; simple pilot projects with clean data can progress to production within three to six months, whereas more complex systems may require nine to eighteen months to proceed. Many AI test programs never go into full operation. Studies show a significant difference between demos and systems that are actually ready for use. Gartner, for example, has warned that a large percentage of AI projects could be canceled by 2027 due to costs, unclear business benefits, and insufficient risk controls. This means that major spectacles don't influence decision-makers. They are influenced by ways to reduce risk. This includes vendor service agreements, the ability to observe how the system operates, a record of the model's origins, and a path to supervised production.
Ads Grab Attention but Don’t Drive Enterprise Decisions
Super Bowl ads are great at two things: they raise brand awareness quickly, and they create stories for investors—Anthropic’s ad campaign, which states that Ads are coming to AI. But not to Claude” forces a public debate about how to make money from AI and how to make sure it's trustworthy. It gets headlines and forces company representatives to answer questions on social media. But headlines and social media buzz don't really affect purchasing decisions. Companies don't give out contracts because a vendor ran a clever 30-second ad. They give them out because a platform lowers integration costs, reduces risk, and delivers a consistent return on investment over several months and years. News outlets covered this media battle, and the effect on consumer feelings is immediate. The effect on tech chiefs is small, if it is visible at all.
Think of enterprise agreements as moving along a different path than consumer choices. Sales processes depend on rules, vendor risk evaluations, and partner networks. If a vendor offers an admin layer that handles AI, integrates with business processes, enforces permissions, and creates audit trails, purchasing departments will usually choose that vendor, regardless of how good the Super Bowl ads were. That is why the best way to succeed in the business world is becoming less and less about having the best AI model. Instead, it's more about being the dependable application layer. When vendors refer to these new products as “AI coworkers” or “agent platforms,” they're directly addressing buyers' needs: buyers wanna replace fragile point solutions with components that are governed, interoperable, and live inside the company’s control plane.
The Numbers: Scale, Risk, and the Power of Partnerships
The overall stats are basic but show you a lot. The top research firms have somewhat different predictions, but they all agree on one thing: businesses will spend most of the money. IDC and similar research indicate that companies' AI budgets will reach hundreds of billions this year, and another major research firm predicted that total IT spending on AI will be in the trillions when infrastructure and software are included. To put it differently, the amount of money going into business AI is so large that even small changes in purchasing behavior can create big winners and losers. This money doesn't go to the company with the best ad; it goes to vendors that can fit into purchasing processes and spread the cost across many business units.
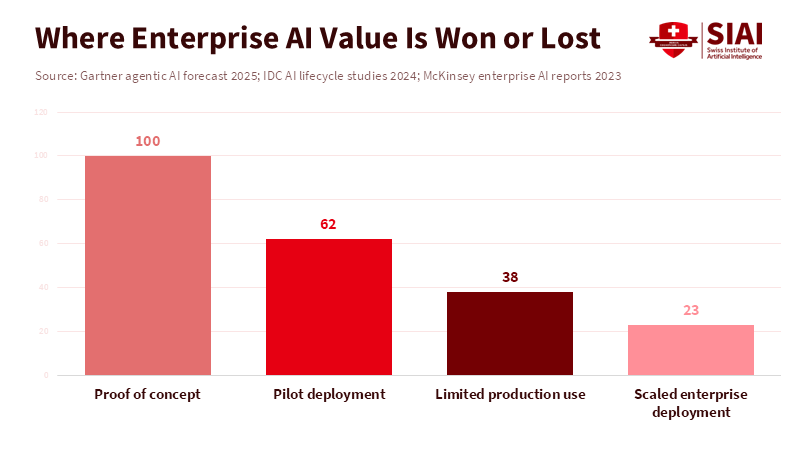
Figure 2: Most enterprise AI initiatives fail after the pilot stage, where orchestration, integration, and governance become binding constraints.
The risks and failure rates strengthen the point. Industry studies have found that most pilot programs end before they are effective. IDC and other observers share that most proofs of concept fail not because of model fit but because of data readiness, change management, integration debt, and governance failures. These failure modes are what an admin layer aims to fix. A platform that can reduce integration time, make outputs traceable, and handle administration at scale can turn test projects into ongoing business spending. That's how you turn a purchase win into long-term recurring revenue.
Vendor Strategy: Become the Go-To Admin Layer
For vendors, the plan is simple and calculated: secure positions within business structures where work flows across systems and where people must approve. That means making connectors to ERPs, CRMs, and data warehouses. It is about building governance hooks and role-based controls. Also, you want to offer dashboards that show from which each decision came and how confident you are in it. The reward is not only money. It also controls the data path and the chance pull platform rents via consistent fees and a marketplace. The vendor who becomes the go-to admin earns not only model-use spending but also a share of the business software stack. Proof of this move is everywhere: AI vendors are pitching their products as admin and management platforms and naming business clients as pilots.
This is also where major cloud providers and existing software vendors are important. A well-designed admin layer has to fit on top of cloud infrastructure and inside corporate identity systems. Cloud providers will compete by offering infrastructure and managed admin services. Also, large software companies will try to add agent features into their suites. Because of this, business buyers will prefer systems that fit with current purchasing flows and partner networks, not platforms that act as separate consumer services. The meaning for startups is blunt: the consolidation strategy playbook should be your product roadmap, not an afterthought for the marketing team.
Advice for Educators, Administrators, and Decision-makers
For educators and program leaders, the lesson is useful: The lesson teaches integration and governance skills, not just model tuning. A new group of AI managers needs to know how to build solid data pipelines, audit model outputs, and draft service agreements that unite vendors and buyers. Classes should emphasize the people-and-process side of AI use — things like change management, contract design, and rules — because these are the things that turn pilots into production. For administrators, the job is to change vendor selection criteria to reward observability, testability, and composability over marketing hype.
Policymakers should make sure purchases are predictable and auditable. If regulators require audit records and source data for high-risk decisions, vendors that already provide those capabilities will have a structural advantage. A policy that clarifies liability for automated decisions will make business buyers more willing to sign multi-year contracts with admin vendors that agree to clear responsibilities. That is the lever that moves spending from tests to recurring contracts. The policy opportunity is not in a regulation; it is in purchasing standards and liability frameworks.
Addressing the Obvious Concerns
One concern is that advertising still matters: brand trust has pull at boardrooms and stock markets. That’s right. A known brand reduces sales friction and helps attract talent. But brand doesn't replace contracts with audit rights, nor does it change the technical burden of connecting with a bank’s core ledger. Another worry is that models still matter: better models make better results. That’s also right. The extra value of a somewhat better model shrinks if the vendor can't run it within a company's control plane. The winner has to unite belief in effectiveness with long-lasting integration and governance.
Another concern is that hyperscalers will own the admin layer. They have size and relationships, but hyperscalers don't automatically gain trust in every business field. Things like banking, healthcare, and government all place rules that reward specialized admin and compliance features. That creates opportunities for vendors who unite field depth with platform interoperability. These aren't simply theoretical openings. They are visible in early partnerships and the naming of first-mover clients on recently announced platforms.
The Super Bowl ad dispute is a helpful story. It shows values and frames public debate, but it isn't how business budgets are chosen. Purchase teams vote with contracts, not with clicks. They give platform dominance to products that lower integration cost, handle risk, and supply observability. The destiny of enterprise AI will be chosen in engineering roadmaps, partner ecosystems, and governance contracts. Vendors who understand this will stop using marketing as a replacement for product engineering. They will build admin layers that become default paths for work. That’s the market that determines winners, not the halftime show. If policymakers, educators, and administrators want to shape good outcomes, they should act on the levers that matter to procurement: clearer standards, better training, and rules that reward auditable, composable, and secure orchestration. The risks are high. The money is moving. The quiet field is now the main one.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
AI Business (2026) Enterprises don’t care about Super Bowl ads. AI Business, February. CNN (2026) Anthropic and OpenAI take their AI rivalry to the Super Bowl. CNN, 6 February. Davenport, T.H. and Ronanki, R. (2018) ‘Artificial intelligence for the real world’, Harvard Business Review, 96(1), pp. 108–116. Gartner (2025) Gartner predicts over 40% of agentic AI projects will be canceled by end of 2027. Gartner Press Release, June. Gartner (2025) Worldwide artificial intelligence spending forecast. Gartner Research. IDC (2024) IDC FutureScape: Worldwide AI and generative AI spending guide 2025–2028. International Data Corporation. IDC (2024) Why enterprise AI pilots fail to scale. IDC Analyst Brief. McKinsey Global Institute (2023) The economic potential of generative AI: The next productivity frontier. McKinsey & Company. Reuters (2026) Anthropic buys Super Bowl ads in challenge to OpenAI’s monetization strategy. Reuters, February. The Guardian (2026) AI chatbots: Anthropic and OpenAI go head to head as ads arrive. The Guardian, 7 February.
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
AI is changing wildfire management by prioritizing where human effort matters most, not by predicting fires.
Human-in-the-loop systems cut response time and reduce ignition risk under tight resource limits.
This shift turns wildfire control from emergency reaction into practical prevention.