Davos survives by staging power, not by exercising it
Ritualized presence replaces accountability and real decision-making
Its persistence reveals deep institutional and educational gaps
Climate shocks now directly strain public budgets and weaken tax bases
Disaster spending and insurance gaps are becoming fiscal risks
Without EU coordination, climate risk turns into a lasting deficit
Inflation spreads faster because firms reprice in response to shocks, not calendars
Energy and AI amplify this speed, but state-dependent pricing is the core driver
Policy and education must adapt to inflation that moves in days, not months
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
The AI Tax is turning memory scarcity into a hidden cost on education
Rising DRAM prices push computing access out of reach for many schools and families
Without action, personal computers risk becoming a privilege again
The price of memory is the new tax on learning. In late 2025, global memory prices jumped roughly 50% in a single quarter and analysts now warn of another doubling as data centers gobble AI-grade DRAM and HBM. This is not a distant supplier glitch. It is a structural pivot: wafer capacity, packaging lines and advanced-process allocation have been steered toward servers built to train and serve large models. The result is an AI Tax—an implicit added cost that falls on every device, classroom, and campus that relies on current computing. That tax is already reshaping procurement plans, delaying upgrades, and forcing schools to choose between connectivity, compute and curriculum. The urgent question for teachers and decision-makers is simple: how do we prevent a technological rollback—where modern personal computing becomes a luxury again—while the AI sector consumes the lion’s share of scarce memory resources?
AI Tax and the new memory scarcity
We reframe the debate away from vague “distribution network problems” to a policy problem that is redistributive by design. The shift of foundry and packaging priorities toward high-bandwidth, high-margin memory for AI servers is not a temporary hiccup; it is a market decision with distributional consequences. Major memory makers are consciously steering their capacity and product roadmaps to meet demand from cloud and AI vendors. That choice raises the effective price of commodity DRAM and DDR5 modules that schools, households and small labs buy. For practical purposes, the market is imposing a new cost on education: higher per-device procurement costs, slower refresh cycles, and fewer options for low-cost computing labs. This is why calling it an “AI Tax” is useful — it captures the predictable transfer of scarce hardware value from broad public use into a narrow industrial application.
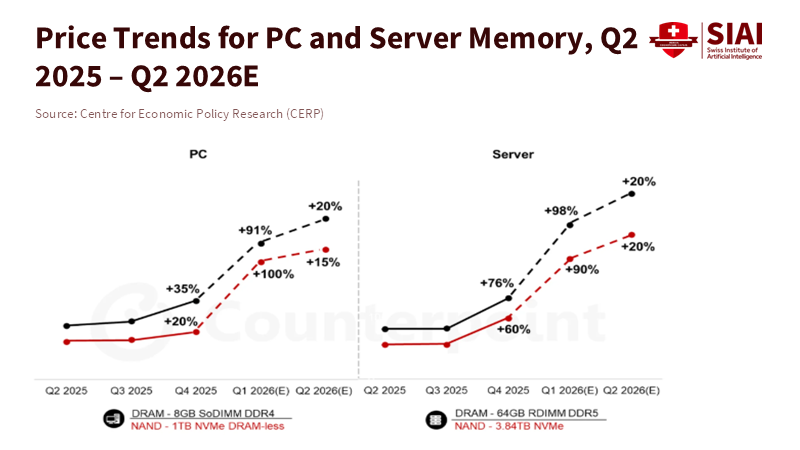
Figure 1: Memory price inflation is being driven by server demand: DRAM prices for AI-oriented server hardware rise faster and higher than PC memory, shifting costs downstream to consumer and educational devices.
The evidence is clear on scale. Market trackers and industry briefs documented a sharp and sustained rise in memory pricing through late 2025, and market-research firms revised their forecasts upward in early 2026. The upshot is that commodity memory, which once kept mid-range machines affordable, now commands prices that push entire system budgets higher. Schools that planned three-year refresh cycles are now delaying or cancelling orders; districts with thin capital budgets face longer device lifespans, which lead to slower software adoption and weaker learning outcomes. These are not abstract supply-chain effects: they are concentrated harms to communities that depend on scheduled, predictable hardware replacement to keep students online and empowered.
Because capacity cannot be expanded overnight, the structural response from memory suppliers will be gradual. Foundry and packaging steps that support HBM and server-grade DDR require capital and lead time measured in quarters and years, not weeks. Meanwhile, cloud and hyperscalers are bidding heavily and locking supply through multi-quarter contracts. The bidding and allocation dynamics will keep upward pressure on consumer-facing prices long enough to shape school procurement cycles for at least two years. The practical consequence is that every procurement decision now embeds a macroeconomic bet: pay up for current availability, or wait, knowing that waiting may not bring lower prices if server demand stays high. That choice reshapes access: short-term purchases will favor well-funded districts and departments, creating a widening gap in practical computing access that compounds other digital divides.
What the AI Tax means for education and access
Short sentences matter because decisions must be made clearly. First, the immediate effect is an upgrade freeze. District and university buyers report postponing orders and trimming spec targets. Those freezes result in two harms: fewer devices per student and older machines that cannot run up-to-date educational software or tools. For computer literacy, computational thinking and hands-on STEM work, older machines are not simply slower; they constrain what teachers can assign and what skills students can practice. That erosion is invisible until a cohort arrives at a lab and finds the software cannot run. The “AI Tax” thus functions as a stealth curriculum knife.
Second, the cost shift affects software and cloud strategies. Schools that expected to offload heavy workloads to the cloud now face higher cloud pass-through costs because providers have absorbed higher capital costs. Higher server-side memory costs raise the marginal cost of hosted simulations, data science labs and adaptive training platforms. For schools already balancing licensing fees against hardware investments, the math changes: do we pay more for cloud services that keep older local machines running, or do we invest in better endpoints and reduce recurring service budgets? Neither choice is attractive for budget-limited districts. The tactical responses we are already seeing vary: extended device lifespans, conservative software rollouts, and a move toward lightweight web apps that run in low-memory environments. Each workaround is a second-best solution.
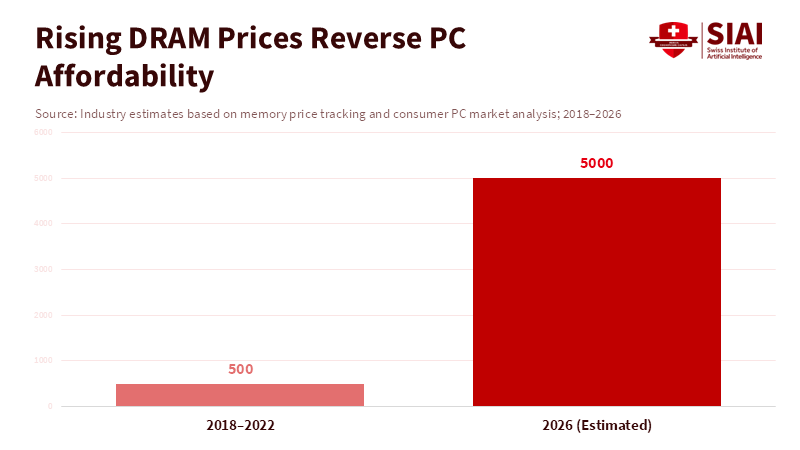
Figure 2: As DRAM prices surge, the cost of a capable personal computer rises sharply, reversing years of declining affordability and narrowing access to modern computing.
Third, inequity amplifies. Well-funded universities and private schools can hedge against the AI Tax by buying early, stockpiling inventory, or contracting directly with suppliers. Public systems and community colleges face procurement rules, budget cycles and constrained cash flow. The result is geographic and socioeconomic stratification of computing capability that resembles earlier eras—when home computers were rare and specialized labs were the gateway to coding and computational careers. If left unchecked, the AI Tax will recreate that old pattern: those with money get the machines that teach the future; those without become passive consumers. This is not inevitable. It is a policy outcome we can prevent through aligning procurement, subsidies and industrial policy with educational priorities. The next section lays out concrete policy steps.
Policy prescriptions to blunt the AI Tax
First, intervene where market allocation skews public interest. Governments and consortia can prioritize memory capacity for educational and public-interest computing using targeted purchase agreements, strategic stockpiles and capital grants. A practical step is to set aside periodic allocations of commodity DRAM for public institutions via negotiated allotments with major suppliers. Such allotments need not be large to be effective; even a fraction of a supplier’s quarterly consumer-module production can stabilize school procurement pipelines and lower volatility for public buyers. This is a classic market-shaping intervention: use collective buying power to reduce transaction costs and prevent thin-pocketed buyers from being priced out. It is not charity; it is public infrastructure policy.
Second, subsidize endpoint fairness rather than subsidize cloud bills. Many proposals intend to expand cloud access to compensate for weak endpoints. That can work in part, but cloud services will transmit the AI Tax downstream as server and memory costs rise. A more durable approach is targeted device subsidies and rotating upgrade funds for disadvantaged districts. These funds should be conditional on device-standard parity—guarantees that students have devices capable of running up-to-date educational software for the intended curriculum. A rotation model that replaces a fixed share of devices each year reduces the shock of a single large purchase and removes the incentive to postpone upgrades indefinitely.
Third, promote memory-efficient pedagogy and software standards as transitional tools for funding. Encourage edtech vendors to adopt low-memory modes and progressive enhancement designs so that core learning tasks do not depend on the latest hardware. This can be spurred through procurement standards and grant conditions. Simultaneously, fund transitional hybrid solutions—modest local compute appliances that use efficient accelerators or pooled labs that share modern hardware across districts. These interim measures buy time while longer-term industrial responses come online.
Fourth, rethink industrial incentives. Public policy should encourage a diversified memory supply chain and buffer capacity for consumer- and education-grade DRAM. That can include targeted incentives for fabs to maintain a share of commodity memory lines, support for packaging lines serving consumer modules, or R&D tax credits that reduce the cost of producing mainstream memory. Policymakers should also insist on transparent allocation practices when suppliers prioritize one customer segment; transparency enables public institutions to plan and respond.
Anticipating critiques, four lines of rebuttal are important. Some will argue that market forces must decide and that interventions distort efficiency. Yet education is not an ordinary consumer good; it is a public good with long-term social returns. Left to pure market allocation, we risk underproviding a service whose value compounds across decades. Others will argue that memory supply will expand and prices will settle. That may happen eventually, but lead times for fabs and packaging are long; in the meantime, cohorts of students will have lost critical learning opportunities. A third critique is fiscal: funds are scarce. That is real. But the alternatives—diminished skill pipelines and higher future social costs—carry larger long-term fiscal burdens. Finally, some may worry about gaming the system. Design allotments, rotation funds and procurement standards with clear audit and sunset clauses to limit rent-seeking. In short, legitimate concerns can be addressed; paralysis would be the far worse choice.
A practical call
The AI Tax is a simple reality: memory is scarce, prices are spiking, and the burden falls on those least able to pay. We can treat this as a market problem or a public policy issue. If we do nothing, the next few years will widen the difference between students who learn to build and those who merely consume. If we act, three modest moves will change the trajectory: coordinate buying power for public institutions, subsidize device parity not just cloud access, and impose disclosure and targeted incentives across the memory supply chain. These steps are practical, politically viable and, crucially, time-sensitive. The clock is not on an abstract market cycle; it is on school boards, budget cycles and the lives of students who may miss the computational foundations of future careers. The AI Tax can be paid voluntarily—through careful, equitable policy that spreads the cost and preserves access—or it can be paid involuntarily, through lost opportunity and entrenched inequality. We should choose a policy.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
AOL. (2026). AI data centers are causing a global memory shortage. AOL Technology. CNBC. (2026, January 10). Micron warns of AI-driven memory shortages as demand for HBM and DRAM surges. CNBC Technology. Counterpoint Research. (2026). Memory prices surge up to 90% from Q4 2025. Counterpoint Research Insights. Popular Mechanics. (2026). Why AI is making GPUs and memory more expensive. Popular Mechanics Technology Explainer. Reuters. (2026, February 2). TrendForce sees memory chip prices rising as much as 90–95% amid AI demand. Reuters Technology. Reuters. (2026, January 22). Surging memory chip prices dim outlook for consumer electronics makers. Reuters World & Technology. Scientific American. (2026). The AI data center boom could cause a Nintendo Switch 2 memory shortage. Scientific American. Tom’s Hardware. (2025). AI demand is driving DRAM and LPDDR prices sharply higher. Tom’s Hardware. TrendForce. (2026). DRAM and NAND flash price forecast amid AI server expansion. TrendForce Market Intelligence.
Picture
Member for
1 year 6 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
North Korea’s economic rise is less about growth than about funded capability Conflict-linked cash is speeding up industrial and military learning Policy must disrupt cash-to-capacity channels, not just impose sanctions
Tariffs do not just redirect trade; they quietly reroute skills, students, and institutions
Trade diversion reshapes education and jobs
Policy must treat trade shocks as human-capital shocks, not only as economic ones.
Selling US Treasuries hurts the seller first by lowering the value of what remains
Only coordinated action by major holders could move markets, and that coordination is unlikely
US Treasuries function as a shared stability asset, not a usable financial weapon
The data center boom is not the new factory — unless we rewrite the deal
Picture
Member for
1 year 6 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Data centers are not modern factories and rarely create broad local prosperity.
They often raise local power costs while delivering few permanent jobs.
Only strict public-benefit energy rules can rebalance the deal.
The data center boom is changing small towns and electrical networks faster than most local governments can track. Global electricity use by data centers reached the hundreds of terawatt-hour range recently, and industry forecasts see consumption roughly doubling within a decade — a scale shock that would make a single new campus as consequential for a rural grid as a mid-sized steel plant once was. That stark fact reframes our question: are data centers destined to play the same civic and economic role that factories did in the 20th century, building broad local prosperity through plentiful jobs and supplier networks, or will they instead function as capital-intensive, low-employment facilities that extract affordable power and offer limited community payoff? This column argues the latter is the default outcome today. The differences among those futures depend on policy: electricity contracts, tax incentives, and whether each data center must be paired with on-site generation or with community power programs that intentionally return value to local residents. Without those bargains, the “21st-century factory” claim collapses into a short construction boom and long-term local costs.
Why the data center boom looks factory-like — and why that resemblance misleads
The raw numbers explain the analogy’s appeal. Modern hyperscale data centers require land, roads, cooling and, above all, immense, reliable power. That visible footprint resembles a factory campus: new buildings, heavy trucks, an inflow of contractors, and municipal revenues tied to construction and property. In many places, officials and economic development teams sell the project this way: quick construction jobs, higher tax bases, corporate donations and the hope of a nascent tech cluster. Those short-lived gains are real. Construction phases can employ hundreds or thousands of workers for months or years. Local suppliers benefit for the duration. Municipal budgets experience an immediate spike in receipts attributable to permit fees and developer payments. Those outcomes are the origin of the factory metaphor — a large, visible employer that forms local life.
But the similarity stops when facilities begin steady operations. Unlike a 20th-century factory that required large, skilled, and semi-skilled local labor forces for day-to-day production, many modern data centers run on automation and remote management. Once built, the permanent on-site workforce is often small relative to a site’s capital value and energy draw. The pattern emerging from recent studies shows a recurring mismatch: big infrastructure and power demands, modest operational payrolls. That means the civic bargain that once justified factory siting—dozens or hundreds of durable local jobs plus supplier ecosystems—is not automatic for data centers. The policy lesson is plain: if a community treats a data center solely as a factory replacement, it will likely end up with an expensive power bill and a handful of long-term jobs, not the broad prosperity promised.
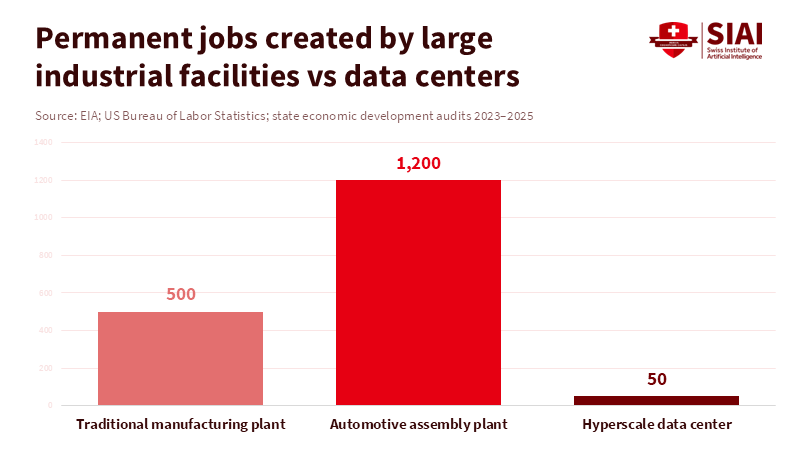
Figure 1: Despite comparable capital intensity, data centers generate only a fraction of the long-term employment traditionally associated with large industrial sites.
Energy, bills and the hidden transfer of value in the data center boom
Power is the fulcrum. Data centers’ electricity demand is already substantial; reputable sector projections indicate that global data-center electricity use will increase substantially in the near term. That increase matters at the local level because grid upgrades, emergency generation and firm capacity all carry costs. Utilities and developers negotiate who pays. If those costs are socialized—through rate changes or long-term cost-recovery mechanisms—local ratepayers may face higher bills, while the data center benefits from access to cheap, reliable power. In effect, the private benefit of hosting a data center can become a public cost unless contracts are reformed.
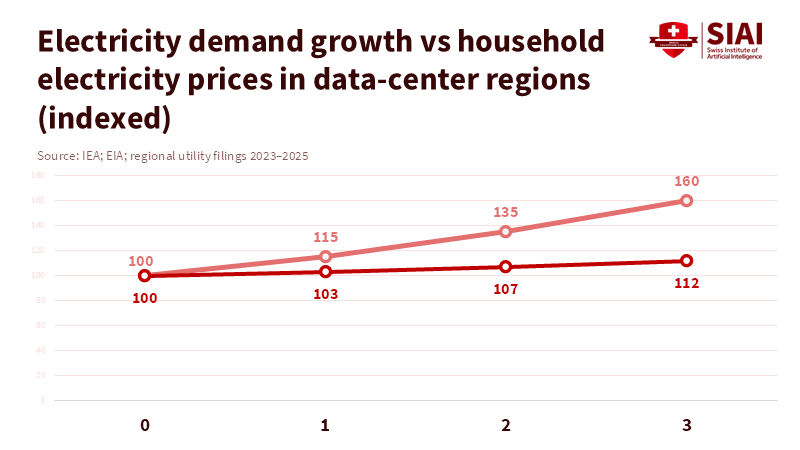
Figure 2: Rapid growth in data-center load is closely followed by rising residential electricity prices, suggesting cost spillovers onto local ratepayers.
That transfer is not hypothetical. Where clusters concentrate, utilities have warned that new, sudden loads require new substations, reconductoring, or even fossil-fuel backup to meet reliability standards during peak demand or outages. Those investments are often recovered through rate mechanisms that touch every household and small business. The visible result is an alarming local complaint: residents see new, gleaming campuses and then receive higher bills. For many small or rural communities, that outcome is politically explosive because it reverses the expected social contract. The structural fix is to rewrite the bargain: require onsite firm capacity that benefits the community; demand lower wholesale rates for residents; or tie grid upgrades directly to shared community pricing programs. Otherwise, the data center boom behaves like an energy parasite — great, concentrated demand that saps local affordability while producing limited local employment.
Jobs, taxes and the gap between promise and reality of the data center boom
Employment claims have driven many municipal approvals. Industry and allied consultants frequently produce projections that include indirect supply-chain jobs, and some national studies report figures that appear striking when read without context. Those broader estimates frequently include induced employment—the jobs supported across an entire national supply chain—and one-time construction roles. In contrast, direct, permanent on-site employment at a single hyperscale campus is often modest: dozens to low hundreds, not thousands. This distinction matters because communities vote, plan schools, and approve zoning in accordance with expectations regarding durable jobs and tax flows.
Recent audits and state studies show the dissonance. Detailed, state-level reviews show that while capital investment and construction increase short-term employment and local revenues, recurring operations generate far fewer local jobs than advertised—and tax deals often blunt the fiscal gains. When generous exemptions or equipment tax breaks are granted to attract projects, net long-term revenue may decline, leaving local budgets to shoulder infrastructure and service costs. Critics maintain this represents a poor return on public incentives. Supporters counter that national supply chain impacts and corporate tax remittances justify incentives. The sensible policy path recognizes both truths: count direct permanent roles separately from temporary construction work and design incentive packages that scale with demonstrable, long-term local benefits. Without that discipline, the data center boom will deliver a construction windfall and then a thin, steady stream of local benefits—far from the mass-employment factories once offered.
A practical bargain: SMRs, community power, and rewriting the deal for the data center boom
If data centers will not reliably create large-scale local employment, then communities must demand a different kind of return: shared, affordable, and resilient energy. Small, small reactors (SMRs) and other firm, local generation options have moved from abstract ideas to concrete corporate experiments. Major cloud providers have announced agreements and investments to pair data centers with advanced nuclear or long-term firm capacity procurement. When implemented, such arrangements can insulate grids, reduce marginal power costs for local customers, and provide a revenue or capacity stream that can be repurposed for public goods. The crucial policy requirement is simple: require every major new campus to demonstrate community power benefits that lower household or municipal rates or to dedicate a concrete portion of firm output to local public use.
There are multiple practical forms this bargain can take. An SMR or co-located firm generator, jointly owned with the utility, can deliver lower-cost, uninterrupted power to a local tariff band for residents and municipal facilities. Alternatively, a community benefit agreement can lock a data center into long-term payments to a local energy trust that subsidizes electricity for low-income households and public schools. Another option is a capacity-sharing rule: a percentage of off-peak power is sold back at cost to local businesses. Each design needs clear, enforceable metrics and independent auditing to prevent creative accounting. The point is not to stop data centers, but to align their massive energy footprint with durable, local public value, rather than abandoning communities to bear the external costs while tech firms capture private gains.
Reclaiming the civic bargain in the data center boom
The data center boom will not, on its own, become the 21st-century factory that spreads prosperity widely. The default pattern is one of enormous capital investment, intense short-term employment, and small operational payrolls — coupled with long-term pressures on energy systems and local affordability. Communities can accept that reality or they can legislate a different bargain: require firm generation commitments, community-priced electricity, and incentive structures that scale with demonstrable local benefits. These are not theoretical fixes. There are emerging corporate and utility experiments pairing data infrastructure with SMRs and long-term power contracts — moves that, if replicated under public oversight and with binding community returns, would produce something closer to a factory’s civic role. The policy test for the next wave of siting decisions is this: can a locality negotiate a binding, transparent package that turns raw kilowatts into local wealth, not local cost? If the answer is no, then the towns that host these campuses will have traded a short boom for a long bill. It is time to make the data center boom pay for the people it affects.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Energy Information Administration (IEA). 2025. Energy and AI: Energy demand from AI. International Energy Agency. JLARC (Joint Legislative Audit and Review Commission). 2024. Data Centers in Virginia. Commonwealth of Virginia. Lawrence Berkeley National Laboratory (Shehabi et al.). 2024. United States Data Center Energy Usage Report. LBNL-2001637. Northern Virginia Technology Council (NVTC). 2024. The Impact of Data Centers on Virginia's State and Local Economies. PwC / Data Center Coalition. 2025. Economic Contributions of Data Centers in the United States 2017–2023. PricewaterhouseCoopers. Financial Times. 2024. Google orders small modular nuclear reactors for its data centres. Food & Water Watch. 2026. The Illusion of Big Tech's Data Center Employment Claims. Congressional Research Service. 2026. Data Centers and Their Energy Consumption (CRS product R48646).
Picture
Member for
1 year 6 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
This is no longer a race to catch up, but a push to reduce strategic dependence on China
Supply chains and education systems are now instruments of geopolitical power
Resilience will depend on how quickly institutions adapt skills, policy, and procurement
FDI now succeeds by linking into global value chains, not by expanding domestic production
German investment in China uses local labor and efficiency while value stays global
Policy should shape how FDI integrates into chains, not just how much arrives