Beliefs shape perception before evidence is even processed
Video and data do not correct bias; they often reinforce it
Education systems must redesign how evidence is interpreted, not just collected
The Age of the Reality Notary: How Schools and Institutions Must Learn to Certify Truth
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Digital truth can no longer be judged by human sight or sound alone
Institutions must certify reality, not just detect fakes after harm occurs
Education systems now play a central role in rebuilding trust in evidence
In 2024, there was a deepfake attempt about every five minutes. This shows a significant shift in how we see public truth. Almost everyone is worried about being fooled by fake audio or video. These two things together are a warning: fake sights and sounds have quickly become a significant problem. Schools, leaders, and lawmakers need to do more than teach people how to spot fakes. They need to rebuild the ways we trust images, recordings, and documents. We need to create a system of reality keepers—professionals and organizations that can certify trustworthy digital proof. If we don't, we risk losing control over public truth to those who can easily weaponize fake media.
Reality Keepers: Changing the Role of Verification in Education and Organizations
Usually, we think of verification as something experts do after something has been created. An expert examines the details of a film, metadata, or an object, then makes a decision. However, this approach is becoming outdated. Now, fake media is generated by computer programs trained on large datasets of images and audio. These programs can replicate lighting, facial expressions, and even unique speaking styles. Verification is no longer just about finding a single-pixel error. It's about proving the source of an image or recording and when it was taken. We need to start verifying information earlier, closer to where images and recordings first appear. Schools and organizations need to teach and use methods to verify content sources when they are created and shared, rather than trying to identify fakes later. New verification tools are improving, but they still have issues. Detectors work well on things they already know, but they struggle with new methods and changes. This means we can't rely only on detection. Organizations need processes in place to support.
This is important because it changes who is responsible for the truth. Before, newspapers, courts, and labs were the ones who decided what was real, even though they weren't perfect. Now, schools, online platforms, and service providers need to help certify content as real enough for specific uses. The idea of a reality keeper includes being a technician, an auditor, and a teacher. A reality keeper might create a digital record that includes information about where something came from, when it was created, which device was used, and any changes made. This record would stay with the media. For everyday tasks such as online notarizations, rental agreements, and school assignments, this record could be the difference between trust and fraud. This focus on origin is important because, while detectors are improving, fake media methods are improving even faster. We need to focus on protecting the truth from the outset, not after the damage is done.
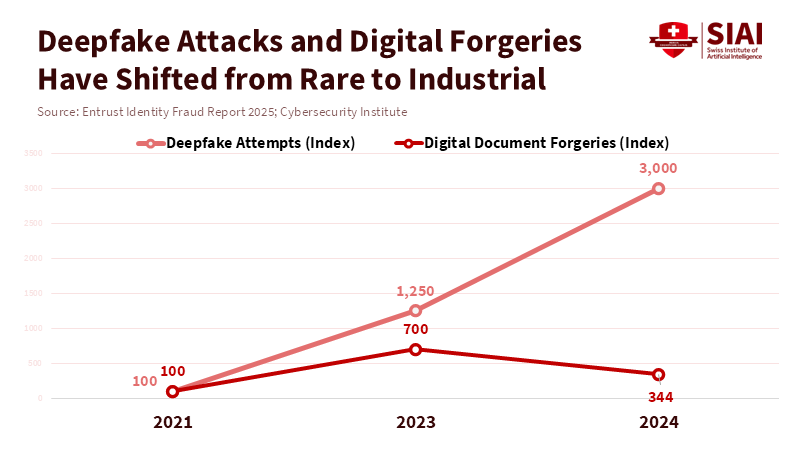
Figure 1: Deepfake activity and digital forgery have moved from isolated incidents to industrial-scale operations in just three years.
The Evidence: The Problem, the Cost, and the Limits of Human Judgment
The numbers show why we need to act quickly. There has been a massive increase in fake content and fraud. Companies that track identity fraud report that deepfake attempts are occurring frequently. Surveys say that people are apprehensive about being tricked. Experts say fraud will increase significantly due to new computer programs, unless we take action. Fraud could increase by billions of dollars across finance, real estate, and business between now and the middle of the decade. These problems are not imaginary. Title insurers, escrow agents, and banks have already reported cases in which fake voices or videos were used to steal funds. The finance world is like a warning sign. When fraud becomes too costly, the response is swift: transactions are frozen, rules are tightened, and lawsuits are filed.
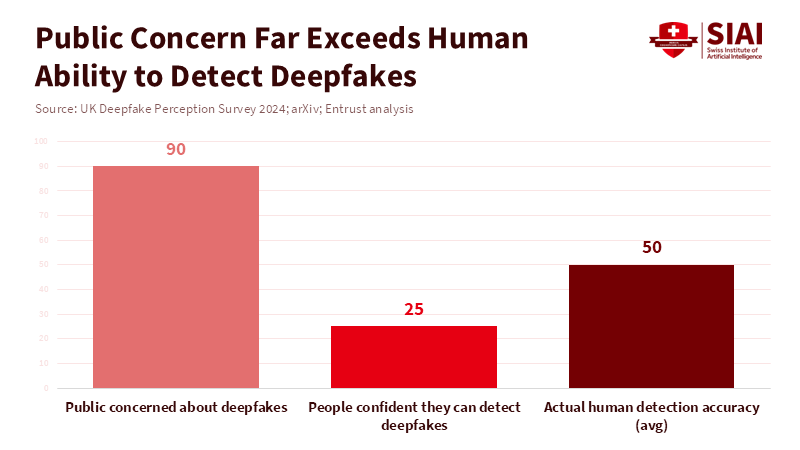
Figure 2: Fear of deepfakes is widespread, but human ability to spot them remains weak and unreliable.
How well people can spot fakes tells another part of the story. Studies show that people are poor at detecting high-quality forgeries. We can't rely on human accuracy anymore. Computer programs can perform well at detecting forgeries, but only in controlled settings. In real-world settings, where attackers continually adapt their methods, detectors perform less effectively, particularly as fake media techniques evolve. This means that organizations that rely on people to detect forgeries will miss more forgeries. Those who rely only on detectors will face problems with false positives and policies that don't work against new attacks. We need a mix of human and computer verification, along with clear steps for verifying information and holding individuals responsible if they don't follow those steps. This is where the role of the reality keeper comes in.
What Schools, Leaders, and Lawmakers Must Do Now to Build Reality Keeper Systems
First, schools need to do more than teach a single lesson on media knowledge. They need to create skills that build over time, from kindergarten through college and professional training. Younger students should learn simple habits, like noting who took a picture, when, and why. Older students should learn to read metadata, understand how information is stored, and practice tracking sources. Professionals such as journalists, notaries, and title agents should verify information, maintain audit logs, and require proof of origin from others. These skills are essential for everyone. We can teach these skills in practical ways, such as pairing classroom activities with foundational tools, running simulations in which students create and identify fakes, and offering short professional certificates that require ongoing training. The goal is not to create many image verification experts, but to ensure that organizations have simple, repeatable ways to make it harder to create fakes.
Second, we should require proof of origin for essential transactions. This proof would include information about the device used to create the content, a secure timestamp, a record of any changes made, and, when needed, a verified identity. For matters such as remote closings, loan approvals, and election materials, organizations should not accept media that doesn't meet a basic standard of proof. The point is not to make small things complicated, but to create easy, automated checks that don't inconvenience legitimate users while making it more complex and more expensive to commit fraud.
Third, we need to create official reality keeper roles and give organizations a reason to use them. Reality keepers would be licensed professionals who work in organizations such as schools, banks, and courts, or who are provided by trusted third parties. Their license would require them to comply with standards for verification, audit practices, and legal responsibilities. Getting accredited wouldn't require advanced technical skills. Still, it would require following standard procedures: capturing proof of origin, tracking the source of information, maintaining basic security knowledge, and handling disagreements. It's essential to give organizations a reason to use reality keepers. According to EasyLearn ING, professionals can strengthen defenses against digital fraud, including deepfakes, by participating in short, practical courses focused on verification skills. Insurance policies and regulations could reward those who consistently use these reality-keeper techniques. Lawmakers should see these programs as essential and fund pilot programs in schools and high-risk areas.
Addressing the Main Concerns
Some might worry that this will be expensive and complicated. But the cost of doing nothing is rising faster. The cost of adding proof of origin to a video or document is small compared to the value of transactions in finance and real estate. Studies show that the extra work is manageable and can be offset by lower fraud losses and insurance savings. Others might say that attackers will adapt, and that verification will never be perfect. That's true, but we don't need perfection. We just need to make it harder for fraud to be worth it. Even a single additional verification step for wire transfers can prevent much of the crime. Some may be concerned about surveillance and privacy. But we can design the proof of origin to include only the necessary information and to use privacy-protecting methods. We need rules and oversight to minimize the use of data. The alternative—allowing fake content to spread unchecked—creates much bigger problems for privacy and democracy by weakening our trust in facts.
A deepfake every five minutes is not just a statistic; it's a call to action. If we let the ways we trust images and recordings weaken, the future will be one where truth is controlled by whoever can create the best fakes. The answer is to teach about origin, require proof of origin for essential exchanges, and create accredited reality keepers who are legally and operationally responsible. Schools should teach the skills, leaders should establish standards, and lawmakers should require basic verification and fund training programs. This won't solve everything, but it will rebuild trust where it has been lost. According to a recent article, a recommended first step is launching phased pilot programs in selected educational settings that use synthetic personas, along with systems to verify the origin of essential materials and dedicated training for roles focused on maintaining digital authenticity. If these initiatives are not implemented, there is a risk that others may create deceptive content and shape public opinion. That would be a loss we can't afford.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Deloitte. (2024). Generative AI and Fraud: Projected economic impacts. Deloitte Advisory Report. Entrust. (2024). Identity Fraud Report 2025: Deepfake attempts and digital document forgeries. Entrust, November 19, 2024. Jumio. (2024). Global Identity Survey 2024 (consumer fear of deepfakes). Jumio Press Release, May 14, 2024. Alliant National Title Insurance Co. (2026). Deepfake Dangers: How AI Trickery Is Targeting Real Estate Transactions. Blog post, Jan 20, 2026. Tasnim, N., et al. (2025). AI-Generated Image Detection: An Empirical Study and Benchmarking. arXiv preprint. Group-IB. (2025). The Anatomy of a Deepfake Voice Phishing Attack. Group-IB Blog. Stewart Title. (2025). Deepfake Fraud in Real Estate: What Every Buyer, Seller, and Agent Needs to Know. Stewart Insights, Oct 30, 2025.
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
The Death of the Entry-Level Role and the University Mandate
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
AI is permanently erasing the entry-level roles that once trained new graduates
Public reinvestment funds will fail to rescue these jobs from corporate efficiency measures
Universities must urgently adopt high-intensity training models to prevent a workforce crisis
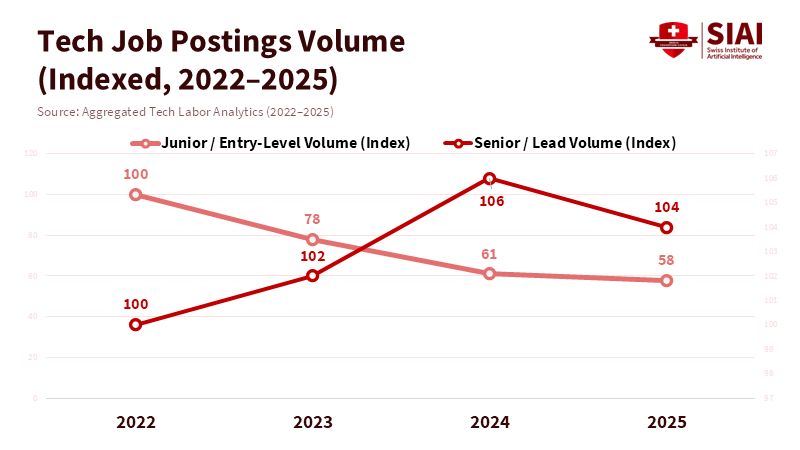
By 2025, it looks like the traditional starting point for young tech professionals will be gone. According to a report from the Korea Labor Institute, while traditional forms of AI were linked to lowered growth in full-time, permanent jobs in areas such as manufacturing between 2018 and 2023, there is no evidence that generative AI, such as Large Language Models, has caused a fundamental drop in entry-level jobs in tech-related fields in Korea during that period. These AI systems can now handle basic tasks—like fixing code errors, writing drafts, and cleaning up data—that used to be how new graduates learned the ropes.
Some people suggest creating a special fund to help people get new skills and find different types of apprenticeships. But this idea doesn't account for how companies actually operate or the fact that these kinds of training funds haven't worked well in the past. What we're seeing is a real problem: the path from college to a job is breaking down. Schools need to take swift, severe action to address this gap. If they don't, less reputable bootcamps that make big promises but don't deliver will likely take their place and charge high fees.
Why an AI Retraining Fund Won't Work
The idea of a fund to save junior positions sounds good at first. But in today's political and economic situation, it’s not very realistic. There have been past attempts by governments or groups to tax companies for using automation to pay for worker retraining. These funds rarely work as intended. Right now, companies are trying to cut costs by reducing staff and using AI to improve efficiency. It doesn't make sense to expect them to voluntarily give money to a fund that supports the very entry-level jobs they're trying to replace with AI. Even if a fund like this existed, it would probably take years for the money to be distributed because of all the red tape involved. By the time a training program is approved, the AI tools used in that field will already have changed significantly.
There's also a basic problem of motivation. Companies focus on their results every three months, but people need years to develop their skills. If a company can switch from paying a junior employee $70,000 a year to paying $20 a month for an AI tool, a small subsidy isn't going to change their minds. This creates a gap in the workforce: we have experienced professionals who can manage AI, and we have students who understand the theory, but there's no clear way to gain experience and advance their careers. Depending on donations or taxes to fix this problem ignores the fact that the job market has already moved on. Schools need to step up and accept responsibility, since they're the ones who promise to prepare students for their careers. They're not keeping up with how quickly the market is changing.
Figure 1: While senior roles remain stable, entry-level positions have decoupled from the broader market, confirming that automation is displacing "learning roles" rather than expert ones.
The Problem with Low-Quality Coding Bootcamps
When schools don't equip people with the skills they need for jobs, other options arise. This was clear during the rise of coding bootcamps from 2015 to 2023. Many private schools popped up promising to turn anyone into a software engineer in just a few months. But the results haven't been that great. In places like South Korea, there are now too many graduates from these coding schools who know the basics of coding but don't really understand computer science or AI.
These programs usually focus on how to use a tool rather than on why it works. When AI is doing more and more, knowing just the how isn't very useful, because the AI already knows it. If you only teach someone to write simple code, you're teaching them to compete with a machine that can do it better, faster, and for free.
The most concerning aspect of this trend is that quality is getting worse. A good AI training program is hard, and many people won't pass. According to Algocademy, coding bootcamps often lack uniform curricula, which can lead to inconsistent course quality and gaps in essential knowledge, potentially making it easier for students to enroll without guaranteeing that they will be job-ready. According to a 2024 Gartner survey, marketing teams are leading in AI adoption, but their approaches vary widely, as reflected in how AI bootcamps are currently marketed. According to an OECD report on AI and the labor market in Korea, while many programs offer training in areas like prompt engineering or model tuning, these often provide only a basic understanding of the technology. As a result, there is a growing number of certified individuals who may still lack the advanced skills required for the remaining entry-level technical roles that have not yet been automated by AI.
Why Universities Have to Step Up
Schools can't just teach theory and leave the practical training to employers anymore. Employers have made it clear they're unwilling to pay to train new graduates. This means schools need to provide the equivalent of a residency program. They need to include hands-on, challenging projects that are similar to the work experienced professionals do. This isn't simply about adding a few more labs; it's about changing the way schools are funded and taught. Universities need to stop operating in silos and start acting as incubators that help students develop advanced skills. If a student graduates today with only a conceptual understanding of algorithms, they probably won't get a job. They need to demonstrate that they can use AI systems to produce professional-quality work from the outset.
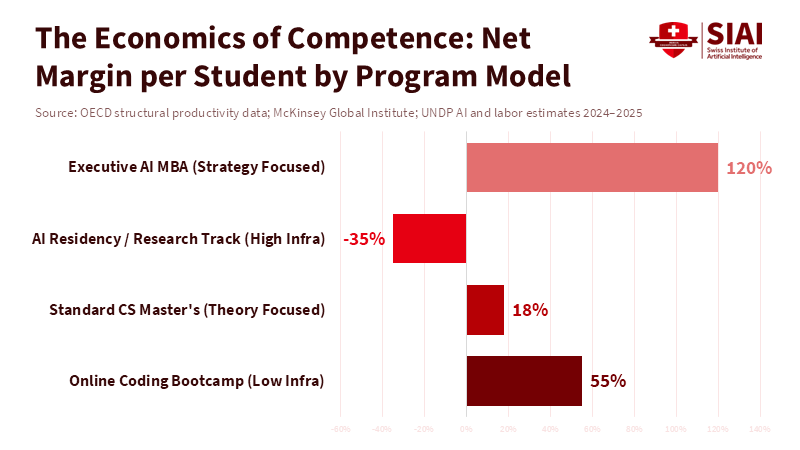
This change is difficult because it's expensive. The Swiss Institute of Artificial Intelligence (SIAI) provides a clear case study of the need for a structural pivot. Faced with the economic reality that a rigorous, high-quality Master’s track in AI operates effectively as a "loss leader," the institute was forced to innovate its underlying business model. The solution was to establish an "Executive AI MBA"—aimed at high-level leaders who need to understand AI strategy—to cross-subsidize the intensive, capital-heavy training of research students. This financial juxtaposition allows the institute to maintain a survival rate that reflects the true difficulty of the subject matter, preserving elite standards without succumbing to the insolvency that currently threatens traditional academic departments. Most universities aren't willing to make this kind of change yet, but they'll have to if they want to stay relevant.
Figure 2: To produce "Day 1" competent graduates, the cost of GPU compute and expert mentorship exceeds tuition; this deficit must be subsidized by high-margin executive programs.
The Reality of Layoffs and Professional Survival
Some people might say that universities shouldn't be trade schools and should focus on teaching students how to think. That sounds good, but it ignores the reality of student debt and the shortage of jobs. If learning how to think doesn't lead to a job, the university system as we know it will collapse as students choose cheaper, even if lower-quality, options. We can't stop companies from cutting jobs to save money. Efficiency is the primary driver of today's economy. So, the only way to protect the future of the workforce is to ensure that entry-level graduates can perform at the level of someone with several years of experience. This requires a level of rigorous education that most schools aren't prepared to provide.
The message is clear: education leaders need to stop waiting for a government-funded retraining program that's unlikely to materialize. They need to stop competing with low-quality bootcamps by lowering their own standards. Instead, they need to change how they're funded to support challenging, job-ready training. This means accepting the possibility of higher failure rates and the cost of expensive, practical resources. We need to connect schools and industry within the university. If we don't, we'll leave a whole generation of students stuck in a situation where they're too qualified for manual labor but not qualified enough to compete with AI systems taking over their jobs. The time for small changes is over; universities need to become the gatekeepers of professional success.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bureau of Labor Statistics. (2024). Employment Projections: 2023-2033 Summary. U.S. Department of Labor. Gartner. (2024). The Impact of Generative AI on the Tech Talent Market. Gartner Research. International Labour Organization. (2023). Generative AI and Jobs: A Global Analysis of Potential Effects on Job Quantity and Quality. ILO Publishing. OECD. (2024). OECD Employment Outlook 2024: The AI Revolution in the Workplace. OECD Publishing. Stanford Institute for Human-Centered AI. (2024). Artificial Intelligence Index Report 2024. Stanford University. World Economic Forum. (2023). The Future of Jobs Report 2023. WEF.
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Europe must thicken AT1 capital buffers even if it permanently lowers bank profits
Digital bank runs make thin hybrid capital unreliable in real stress
Clear, equity-like AT1 design is cheaper than repeated public rescues
Wearable AI is moving computing from screens to body-level devices
Education policy must balance personalization with privacy and trust
Early rules will decide whether wearable AI helps learning or harms it
The rules-based order is breaking into competing systems
Asia is building regional frameworks to manage the shift
Education and institutions must adapt to fragmented governance
Ukraine cannot rely on the 1990s transition model without rebuilding core infrastructure
The Korea 1953 case shows why catalytic capital must target hard assets first
A phased Ukraine reconstruction strategy is key to unlocking private investment and EU integration
Democracy raises growth most where human capital is already strong
Freedom and skills act as multipliers, not substitutes, in economic development
Sustained prosperity requires joint investment in institutions and people
Pay for the Light: Why AI transparency funding must be the price of openness
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
AI transparency is a public good that cannot survive without explicit funding
Unfunded openness will weaken Western firms against state-subsidized competitors
Paying for transparency is the only way to keep AI markets both open and competitive
In the last three months of 2025, tech companies borrowed around $109 billion through corporate bonds to pay for the intense competition in AI. Big AI companies shifted from small research budgets to huge data centers and computing power, costing them tens of billions more. This shows something important: open AI systems will only stay open if there's money to cover the electricity, staff, checks, and responsible management that make openness real. Saying that AI transparency is a good thing, legally or morally, is important, but it's not the whole story. According to the California State Legislature's Transparency in Frontier Artificial Intelligence Act, new regulations require companies developing artificial intelligence to increase transparency, which could create challenges for international competitors, especially those backed by governments. To protect both our values and fair competition, we have to connect transparency with a way to pay for it. This AI transparency funding would put a fair price on the benefits to everyone and treat funding as a clear part of policy.
The Reality of Paying for AI Transparency
First, a lot of money is being spent on infrastructure. Top companies are building massive data centers and borrowing a lot to do it. Teaching and running the biggest AI models now needs constant money for computer chips, power, cooling systems, and fast connections. Companies get this money from investors, partners, and by selling bonds. This creates a pattern: investors are paying for growth now, hoping to make money later. But making money later isn't a sure thing. Competition, increased efficiency, and global politics can lower the expected profits. Open AI models and shared training data increase costs because of checks, removing sensitive info, paperwork, and following rules. This doesn't directly create new income unless it's used to make money. This creates a common problem: companies are asked to provide something good for everyone – real transparency – but their own profits depend on keeping their technology secret.
Second, there's a big difference in government support around the world. Many AI projects in China get direct and indirect support from the government. This includes money, tax breaks, shared computer networks, and support from local governments, which lowers the cost for companies to grow. According to the Foreign Policy Research Institute, local governments in China, such as in Beijing, Shanghai, and Shenzhen, subsidize the cost of computing power for AI startups through computing power vouchers. In contrast, companies in the United States generally do not receive similar government support. This matters because if transparency rules are the same for everyone, without considering where the money comes from, it could favor companies that are supported by subsidies. If transparency is a requirement for everyone, it needs to come with different ways to pay for it, or it will unfairly hurt companies that don't get subsidies.
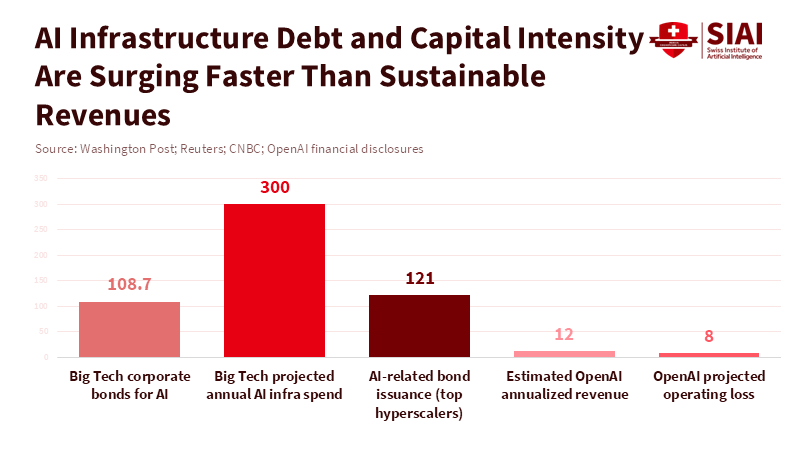
Figure 1: AI firms are taking on record debt and infrastructure spending at a pace that outstrips near-term revenue growth, making unfunded transparency obligations economically fragile.
That's why AI transparency funding is important: we need to pay for transparency directly. This could be done in different ways, like:
Direct payments from the government to help companies check their AI.
A fee paid by big AI companies that goes into a fund for public transparency.
Tax credits for independent checks of AI models.
Payments to smaller companies to help them follow the rules.
The specific plan is important, but the main idea is simple. If transparency creates benefits for everyone – like less misinformation, better safety, ways for regulators to check AI, and more trust – then it makes sense to use public money or have the industry work together to pay for it. Asking companies to pay for it on their own puts a strain on the market and encourages them to cut corners.
AI Transparency Funding: How to Compete with Rivals Supported by Governments
The central strategic question for Western firms is not whether transparency is desirable — it is — but how to keep their commercial engines running while meeting it. Open models and published datasets can create ecosystem value: researchers reuse, startups build, regulators inspect. But monetising that value is nontrivial. Advertising, enterprise subscriptions, vertical services and device ecosystems are plausible revenue routes for companies steeped in platform economics. Yet the numbers show a gap between headline valuations and durable cash flow in many frontier players, and the capital intensity of data centres and chips keeps growing. That gap is why some investors speak of an “AI bubble”: valuations price in sustained, very large margins that hinge on monopoly positions or unmatched scale. When rivals are state-backed, the contest is not just about product quality; it is about who can afford to subsidise a long investment horizon.
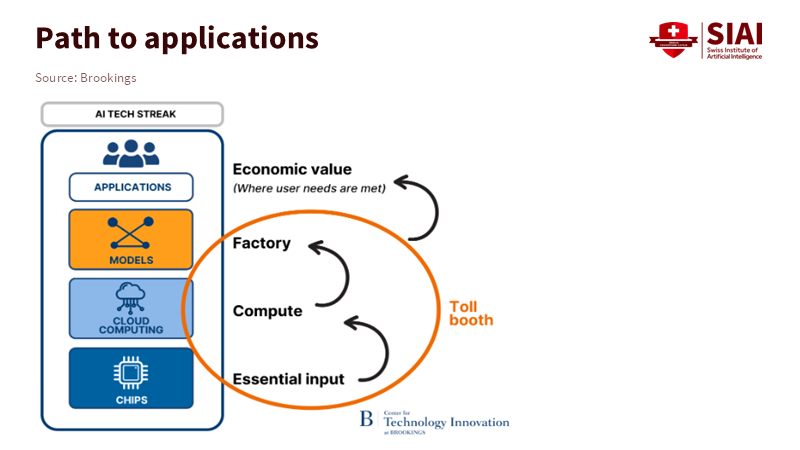
Figure 2: As AI systems move from chips to models to applications, economic power concentrates around compute and model layers, creating natural “toll booths” that shape who can afford openness and transparency.
A practical response is to design transparency rules that recognise financing realities. One element is transitional relief calibrated by firm size, revenue, or access to strategic capital. Another is co-funding arrangements that link transparency to commercial advantage: firms that open crucial model documentation could receive preferential access to public procurement, tax credits for AI R&D, or co-funded compute credits. That makes transparency a serviceable investment — companies will open up because it buys market access and lowers other costs. A second element is mandatory contribution models. If the public gains from independent audits, a small industry levy earmarked for public-interest auditing bodies can scale as the market grows; that prevents free-riding and keeps audit capacity well-funded.
A final element is targeted risk sharing for the costliest pieces of transparency: independent red teams, third-party compute replication for validation, and long-running model documentation. These are expensive, uncertain, and not easily amortised into a subscription fee. Pooling those costs, or underwriting them through public guarantees, reduces the chance that a firm will avoid transparency because it cannot afford the verification.
AI Transparency Funding: Principles for Design and Policy
Policy should be based on four connected ideas. First, transparency requirements should be clear and specific. If they're vague, companies will do the minimum. Specify what information to share (model cards, training data, computer budgets, audit logs) and how to make results reproducible. Second, fund the standards. Create a public group to check AI, funded by user fees, industry fees, and government money, to avoid being controlled by companies. Third, match requirements to capabilities. Very large models that can do many things should have stronger transparency and cost-sharing requirements than small, specialized models. This allows for new ideas while targeting the biggest risks.
Fourth, make funding depend on performance. Payments, credits, and contracts should go to companies that meet strict transparency goals, checked by independent auditors. This sends a message that transparency isn't just for show, but a performance measure that improves competitiveness. It also avoids punishing companies that are transparent but underperform. Funds should reward real openness and verifiability. For small companies, the costs of auditing and paperwork make it harder for the rule to enter the market.
A good plan could use different ways to support transparency. A basic transparency standard would apply to all systems used widely. According to a study by Theresa Züger, Laura State, and Lena Winter, evaluating AI projects with a public-interest and sustainability focus can involve funding mechanisms such as a fee that increases with revenue to support public audits and measures to monitor computing power. Additional payments could be allocated to shared resources that benefit everyone, including safety test datasets, open benchmarks, and independent studies that assess how AI models perform. International cooperation would help create a level playing field. If foreign subsidies are clear, trade solutions or similar funding could be considered to prevent unfair advantages. The policy should involve laws, funding, and international agreements.
AI Transparency Funding: What It Means for Educators, Administrators, and Policymakers
Educators and administrators need to see AI transparency funding as both something to manage and something to teach. For universities and research labs, transparent funding can be a way to have steady collaboration. Government or industry payments that require open model documentation create predictable income for staff and data management. Administrators should develop the ability to manage data and audit models in the long term. These skills will be valuable in both education and public service. When buying AI systems, education systems should prefer companies that commit to real transparency and accept cost-sharing or payment plans tied to audit performance.
For policymakers, the challenge is to create the right system. Short, simple rules will either be avoided or create too many burdens. Instead, create a policy that combines basic requirements, shared funding, and targeted rewards, using many tools. Create clear ways to report information and to obtain third-party certification to reduce problems. Most importantly, build public audit groups with technical knowledge and shared governance so they can't be easily controlled by companies. Internationally, coordinate standards with other countries so that transparency requirements don't unfairly hurt companies.
Expect some criticism. Some will say that public funding of transparency is helping companies too much. The response is that the public already pays when private systems create problems like misinformation, privacy issues, and systemic risk. Funding transparency is an investment that reduces those problems and creates a public asset: models and datasets that can be audited and checked. Others will argue that fees and requirements will stop new ideas. But history shows the opposite when rules are paired with predictable funding and market rewards. Clarity lowers uncertainty and can grow markets by building trust. Finally, some will say that supporting domestic companies is protectionist. That's why the plan is important: link support to auditability and provide access to shared public resources, and allow qualified international companies to participate under similar rules.
Transparency without funding is just talk. The huge sums being spent on AI development show why funding is important. If openness is going to be real, it has to be priced and funded in a way that protects competition, encourages verification, and protects the public interest. Policymakers should create AI transparency funding now. They should fund public audit groups, allow fees tied to company size, and create benefits for verified openness. Educators and administrators should demand suppliers that can be audited and build the ability to manage models. Investors should prefer companies that see transparency as an asset. If we do this, openness will become a competitive advantage. If we don't, transparency will either be fake or cause companies to leave the market. We have a choice to make, and time is running out.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bloomberg. (2026). A guide to the circular deals underpinning the AI boom. Bloomberg Business. Epoch AI. (2025). Most of OpenAI’s 2024 compute went to experiments. Epoch AI Data Insights. Forbes. (2025). AI data centers have paid $6B+ in tariffs in 2025 — a cost to U.S. AI competitiveness. Forbes. Financial Times. (2025). How OpenAI put itself at the centre of a $1tn network of deals. Financial Times. Rand Corporation. (2025). Full Stack: China's evolving industrial policy for AI. RAND Perspectives. Reuters. (2026). OpenAI CFO says annualized revenue crosses $20 billion in 2025. Reuters. Statista. (2024). Estimated cost of training selected AI models. Statista. Visual Capitalist. (2025). Charted: The surging cost of training AI models. Visual Capitalist. Washington Post. (2026). Big Tech is taking on more debt than ever to fund its AI aspirations. Washington Post. CNBC. (2025). Dust to data centers: The year AI tech giants, and billions in debt, began remaking the American landscape. CNBC.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.