Europe's EU Innovation Gap Is Relative and Fixable
Europe lags by scale, not ideas: U.S.
Getting Old Before Getting Rich: Why “Aging and Productivity” Will Reshape Education and Growth
Aging erodes productivity and growth Migration buys time, not productivity—see Singapore Youthful regions gain only if they scale learning, health, and adoption

In the economies from the Baltics to the Balkans, the
Truncated Supply Chains, Local Damage: Why Italy's Margin for Error Is Thinner
Supply bottlenecks cut euro-area output ~2.6%; Italy’s hit is larger Foreign-input reliance and SME limits slow substitution, raising costs in factories and classrooms Priorities: multi-sourcing, energy diversification, and digital tracking for public buyers and SMEs

Stop Calling It a Free Lunch: Why Biotech Spillovers Make Everyone Safer
Biotech knowledge spillovers cut global wait times for lifesaving therapies Rich countries gain when diffusion is designed, priced, and measured—not blocked Universities and funders should hard-wire reciprocity, open methods, and cross-border teams

Trump’s Tariffs and the Quiet Rise of Southeast Asia Manufacturing
Trump’s tariffs are driving factories and capital from China into Southeast Asia ASEAN is gaining ground in high-tech exports and global manufacturing Education and skills will decide whether this shift creates lasting, quality jobs

The Subsidy Spiral Is Now a Talent Test
Asian subsidies—especially in steel—distort prices and trade Make subsidies conditional on training and shared curricula Compete on skills to cut tariffs and lift productivity

Two numbers tell the story
From Tariffs to Teachers: Turning the Industrial Subsidy War into a Skills Truce
Industrial subsidy wars starve education just as industry needs more skilled workers Rivalry is shifting from price to rules, making compliance and MRV literacy essential Redirect subsidies into a “Skills Safe Harbor” that funds verifiable training and apprenticeships

When the Data Firehose Fails: Why Education Needs Symbolic AI Now
When the Data Firehose Fails: Why Education Needs Symbolic AI Now

Published
Modified
Today’s AI is costly and brittle; schools need symbolic AI Hybrid neuro-symbolic tools show each step, making feedback and grading fair Policy should fund open subject rules and buy systems that prove their logic

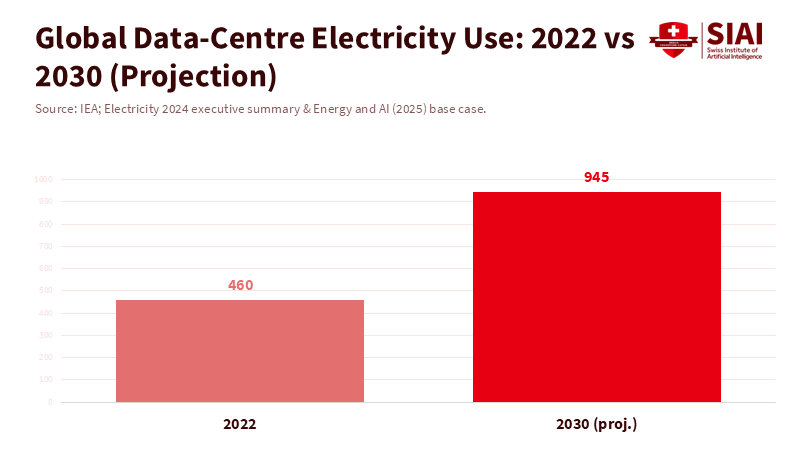
We are in an AI boom that consumes power like entire countries while still stumbling over basic logic. By 2030, data centers are expected to use about 945 terawatt-hours of electricity per year, roughly the same amount as Japan consumes today, mainly due to AI. A single conversational query can consume around three watt-hours, much more than a web search. At this rate, larger models will become more expensive to operate in schools and less reliable in classrooms. Yet increasing scale has not solved the issue of weak reasoning. Large models can impress us but also contradict themselves on simple tasks. The solution for education does not lie in having more data. It requires a return to a clear concept with a fresh twist: symbolic AI. This approach involves systems that represent knowledge through symbols and rules, applying logic to them, and, when appropriate, working alongside neural networks. This shift changes our aim from imitation to proper understanding. It allows us to teach machines how to reason as we expect students to.
What Is Symbolic AI?
Symbolic AI represents the world with human-readable symbols—concepts, relationships, and rules—then uses logic to conclude. It includes the traditions of frames, ontologies, production rules, and theorem proving, and it traces back to expert systems that stored medical knowledge or designed complex tasks. Unlike pattern-matching systems, symbolic AI makes its reasoning process explicit. For example, it can explain why it concluded 'measles' by showing the rule 'IF fever AND rash THEN consider measles,' making its reasoning transparent. This transparency is vital for learning. Students, teachers, and auditors need to understand why a model concluded, not just that it did.
This approach is not outdated. Symbolic methods are still the preferred way to outline constraints, create curriculum graphs, and verify steps in math. They also scale differently than current models—not by gathering more text, but by adding better rules and organized knowledge. Symbolic AI excels in transparent generalization. When a rule applies, it holds wherever its conditions are met, regardless of how it looks on the surface. This is the kind of logic we teach in schools. The idea is straightforward and practical: if we want AI to help students learn reasoning, we should use systems that can reason symbolically and share their logic in a way students can verify.
Why Symbolic AI Matters for Learning and Assessment
Education values reliability over novelty. Modern language models can generate fluent answers that obscure gaps in understanding. Studies in 2024 revealed that when tasks require combining simple parts into new structures—classic compositional reasoning—performance drops significantly. These tests aren't unusual; they reflect how math word problems or multi-step lab protocols function. Symbolic AI directly addresses this gap by encoding the relationships and steps that must hold for an answer to be valid. In assessments, a symbolic system can check each step against a rule base. In tutoring, it can pinpoint the exact constraint a student overlooked.
There is also a fairness argument. If AI will help grade proofs or explanations, schools need a traceable path from premise to conclusion. Symbolic AI provides graders with a record of the rules used and assumptions made. This record can be audited and used for teaching. It also cuts moderation costs. Instead of re-running random prompts and hoping for the same outcome, an assessor can verify whether the proof engine's steps match a curriculum specification. Practically, a district could publish a symbolic rubric for algebra or historical causation, allowing various tools to implement it. Teachers would then review the same logic rather than a multitude of different model quirks.
Hybrid Paths: Symbolic AI Meets Deep Learning
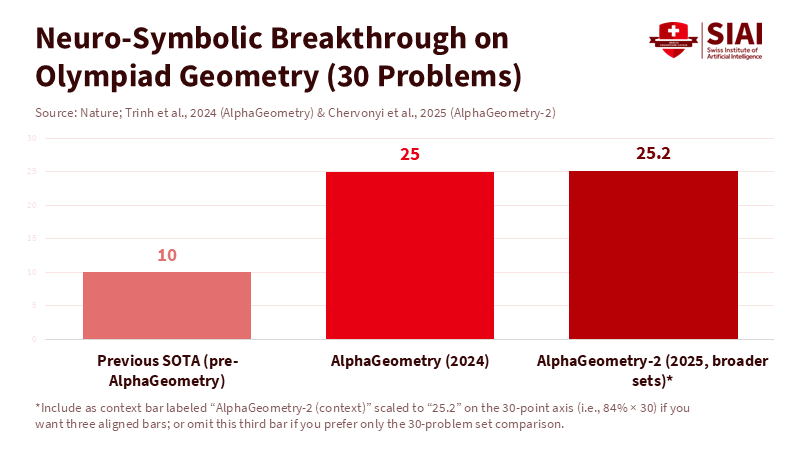
The choice isn't between symbolic or neural; it's both, by design. The most significant advancements in challenging reasoning tasks have come from neuro-symbolic systems that combine pattern recognition with formal logic. In 2024, DeepMind's AlphaGeometry merged learned search with a symbolic theorem prover to tackle geometry problems from the International Mathematical Olympiad at near gold-medalist levels. In 2025, AlphaGeometry-2 pushed this further, often surpassing top human Olympiad geometry benchmarks. The secret wasn't just "more data"; it was better reasoning structures integrated with perception. This model belongs in educational tools. Use neural networks to interpret diagrams or language, and use symbolic engines to ensure that every step is valid.
Hybrid systems also represent the meeting of rigor and practicality. A language model can draft a solution while a symbolic checker verifies or corrects it. If the checker fails, the system can explain which rule didn't apply and why. This feedback loop is ideal for formative learning. Over time, schools can develop compact domain models—competency maps for fractions, stoichiometry, grammar—that remain stable across various curricula and providers. The benefit is resilience: when prompts change, the logic stays the same. Furthermore, because the symbolic layer is lightweight, it can run on school hardware at predictable costs rather than relying on a cloud model that drains power and budget focus from students.
Policy Roadmap for Symbolic AI in Education
Policy should guide procurement and research toward systems that can explain their processes. First, establish a baseline: any AI used for grading or critical feedback should provide a symbolic record of the steps taken, the rules applied, and the knowledge used. This does not rule out neural models; it requires them to work within an auditable logic layer. Second, invest in open, standards-based knowledge graphs for key subjects. Ministries and districts can sponsor modular ontologies—such as algebraic identities, geometric axioms, and lab safety rules—that tools can reuse. These public goods can reduce reliance on vendors and help teachers extend the rules they actually teach.
Third, align AI policy with energy and cost realities. The IEA projects that data-center electricity demand will double by 2030, mainly driven by AI. Districts should insist on architectures that are efficient in inference: smaller local models in tandem with symbolic engines and, where cloud resources are necessary, strict energy usage and latency transparency. A clear procurement guide—traceable reasoning, predictable per-student energy consumption and costs, and adherence to established subject ontologies—will influence the market. This isn't about picking favorites; it's about purchasing systems that reinforce classroom logic and fit within public budgets.
The New Attention to Symbolic AI
This shift is not just theoretical. In late 2025, Nature reported that a significant trend in AI is the push to combine "good old-fashioned AI" with neural networks to achieve more human-like reasoning. Researchers and practitioners now see symbolism as the missing ingredient for logic, safety, and reliability. Even popular science publications have shifted from viewing it as nostalgic to recognizing it as necessary. If we want AI to operate by rules, we must provide it with rules. For education, this focus is essential because it signals an expanding set of tools and a research landscape to explore. Our field can lead rather than lag by funding pilot programs and sharing open resources that other fields can adopt.
This surge doesn't eliminate criticism. Skeptics remember the fragile expert systems and costly knowledge engineering. Those are valid concerns. The counterargument comes from practical experience with hybrid systems. We no longer need to code every detail manually. Neural models can generate candidate rules; teachers can validate and refine them, while symbolic engines can enforce them and clarify their logic. The outcome is not a rigid framework but a dynamic curriculum structured as constraints, examples, and proofs. When exams change, or new standards emerge, we change the rules, not the entire model. That mirrors how education operates now, and it should also be how its AI functions.
The initial figures are a warning and an opportunity. If we continue to prioritize scale alone, AI will consume budgets and energy while failing at what schools value most: clear reasoning. Symbolic AI offers a more educational avenue. It enables us to encode the structures we teach—axioms, rules, causal links—and hold machine answers to the same standards we expect from students. The shift we see in research points the way: perception where needed, logic where essential, and explanations everywhere. Policymakers can support this direction with procurement rules and shared, open subject ontologies. Districts can pilot tools that detail their processes, not just their results. The goal is clear and urgent: align the intelligence we invest in with the intelligence we cultivate. If we succeed, we will spend less time chasing model quirks and more time nurturing minds—both human and machine—that can articulate their reasoning.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
DeepMind. (2024). AlphaGeometry: An Olympiad-level AI system for geometry. Nature paper and technical blog.
Epoch AI. (2025). How much energy does ChatGPT use? Gradient Update.
International Energy Agency. (2025). AI is set to drive surging electricity demand from data centres; see also Energy and AI base-case projections.
Jones, N. (2025). This AI combo could unlock human-level intelligence. Nature.
Jones, N., & Nature Magazine. (2025). Could symbolic AI unlock human-like intelligence? Scientific American.
Wikipedia contributors. (2025). Symbolic artificial intelligence. Wikipedia.
Yang, H., et al. (2024). Exploring compositional generalization of large language models. NAACL SRW.
Zhao, J., et al. (2024). Exploring the limitations of large language models in compositional reasoning. arXiv.
Zheng, T. H., Trinh, T.-H., et al. (2024–2025). AlphaGeometry and AlphaGeometry-2 results on Olympiad geometry. Nature and arXiv.
















Bring Profits Home: Why the Global Minimum Tax Supports America's economic goals and investment climate
A 15% global minimum tax cuts shifting and anchors profits to real activity More onshore earnings strengthen in-house finance and level competition; havens shrink The U.S.
Green Bonds Are Not a Costume. They Are a Contract
Green bonds are contracts, not labels; use-of-proceeds rules cut firms’ carbon intensity The greenium is small, but credibility and disclosure drive real operational change Tight EU standards can scale issuance into measurable emissions declines by 2030
