QR code payments cut entry costs and let micro-merchants sell digitally
Cash use is falling, ATMs are shrinking, and cards and wallets are rising
Policy should standardize open QR rails, keep fees low, and teach acceptance skills
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
Sovereign AI is public infrastructure for education
Countries blend open models and public compute to localize and cut dependence
Schools need shared data, transparent tests, and energy-smart procurement
In late 2025, South Korea announced plans with NVIDIA and local companies to deploy more than 260,000 GPUs across 'sovereign clouds' and AI factories. This figure shows a shift in ambition. It’s not just a pilot project; it is a national infrastructure. Europe is also taking similar steps. They are expanding a network of public 'AI Factories' based on EuroHPC supercomputers. This will allow startups and universities to access the substantial computing power needed for large models at a reduced cost. In Latin America, a regional team is training Latam-GPT to reflect local laws, languages, and cultures, rather than relying on defaults from Silicon Valley. The common goal is clear. Countries want their education systems, courts, and public services to depend on models they own and can examine. They seek sovereign AI systems that align with local laws, culture, security, and education needs—so that teachers and students can trust what they use.
The case for sovereign AI
Sovereign AI is more than just a slogan. It represents a shift from purchasing general cloud services to creating controllable AI systems governed by local rules. Switzerland has demonstrated that a high-income democracy can achieve this openly. In September, ETH Zurich, EPFL, and the Swiss National Supercomputing Centre introduced Apertus, an open, multilingual model trained on public infrastructure and available for broad use. The team presents it as a model for transparent, sovereign foundations that others can adapt. Openness is a policy choice, not just a marketing strategy. It increases accountability and enables schools, ministries, and researchers to verify claims rather than accept black boxes, which is crucial for strategic decision-making and public trust.
Sovereign AI is also necessary where global models do not fit local needs. The collaborative effort behind Latam-GPT, led by Chile’s CENIA, is training the model on regional legal texts, educational materials, and public records to represent Spanish, Portuguese, and Indigenous languages accurately. This approach is not just for show. When models struggle with code-switching or regional expressions, they can make classroom use risky and civic interactions unfair. A regional base model with national adjustments can bridge that gap. The goal is not to outperform the largest U.S. model on English benchmarks; it is to provide answers, grading, and guidance in the language and context students are familiar with.
Build, borrow, or blend: a sovereign AI playbook
There are three main routes to implement sovereign AI. The first is to build from the ground up, as Switzerland has done. The advantage is control over data, training methods, safety measures, and licensing. However, this approach is costly, requiring ongoing public funding, a consistent talent pool, and long-term computing resources. The second option is to borrow and adapt. Latin America’s initiative illustrates a low-compute option: start with an open-weight model and use adapters or LoRA to tailor it for slang, public services, and curricula. This can be done in weeks on modest clusters, which is essential for education budgets. The third option is to blend. This involves anchoring public policy in open models, contracting for private resources when necessary, and forming collaborations to reduce costs.
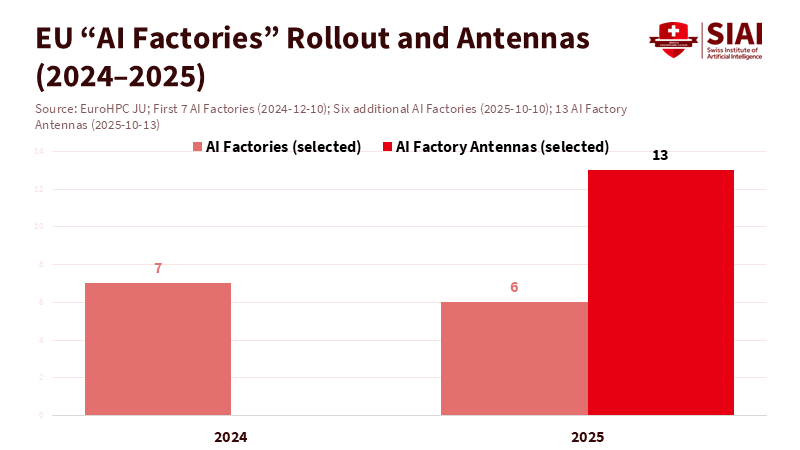
Europe's blended approach is currently the most advanced. The EU's AI Factories initiative leverages EuroHPC to provide AI-optimized supercomputing resources to startups, universities, and small- and medium-sized enterprises. The first wave of seven sites launched after 2024, with six more selected in October 2025, alongside new "AI Factory Antennas" to expand access. Funding is a mix of EU programs and national contributions. The policy goal is straightforward: reduce reliance on foreign, closed models by creating sovereign AI capacity as a shared resource. In the private sector, Europe’s Mistral continues to release strong open-weight models, enhancing the link between public infrastructure and open tools. This exemplifies a “borrow and blend” strategy on a continental scale.
Figure 1: Europe is institutionalizing sovereign AI as public infrastructure, expanding from 7 core sites in 2024 to a wider access layer in 2025
Power, chips, and classrooms: the hidden costs of sovereign AI
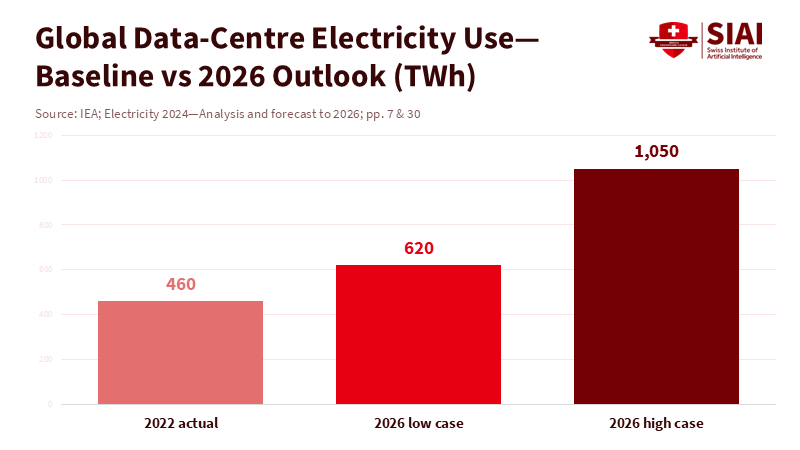
Sovereign AI requires significant computing and energy resources. The International Energy Agency expects global data center energy consumption to more than double by 2030, reaching about 945 TWh, with AI-focused centers contributing a large share of this increase. Education planners need to view this figure as both a budget item and a constraint on energy supply. Suppose a ministry wants an AI tutor in every classroom. In that case, it must consider where processing occurs, who pays for the computational cycles, and how to align service agreements with school hours. Often, the best choice is "nearby but not on-site": public cloud zones governed by domestic laws, supported by long-term clean energy contracts, and connected to education networks.
Figure 2: Rapid growth to 620–1,050 TWh by 2026 makes energy-aware procurement a core requirement for education systems.
Another challenge is hardware concentration. Analysts estimate that NVIDIA still accounts for 80-90% of the AI accelerator market. This concentration increases costs and delivery risks for any country scaling sovereign AI. Europe's response is to build public computing resources and diversify hardware options. The EuroHPC/AI Factories model grants access to non-corporate users, while the EU is investing in domestic chip design—such as a €61.6 million grant to Dutch company AxeleraAI for an inference chip aimed at data centers. While schools may not care about tensor cores, they will notice the impact when hardware shortages delay the launch of national reading tutors. Diversification and public access help mitigate these risks, which is vital for education policy and infrastructure planning.
Korea is addressing both challenges head-on. The government has selected five teams to develop a sovereign foundation model by 2027. They are making large GPU purchases, starting with an initial batch of 13,000 units, and have a multi-party plan that could scale to 260,000 GPUs across public and private AI factories. The public message is about national control, but the practical takeaway for education is procurement design: consolidate demand, negotiate energy contracts that align with school schedules, and reserve computing power for public interest. This is how to keep sovereign AI affordable for schools.
A practical sovereign AI agenda for education
The first step is to view sovereign AI as curriculum infrastructure. Use public models for essential tasks—such as assessment feedback, lesson planning, and language support—and require vendors to operate on platforms that comply with local laws or use certified AI Factories. This ensures data residency, accountability, and cost management. It also sets a guideline: models utilized on public networks must be open-source, or at least open enough for education authorities to validate safety, content filters, and logging. Europe’s direction shows the way, with AI Factories designed to provide researchers and small businesses open access, along with broader digital partnerships the EU is forming with countries like Korea and Singapore to share standards and best practices.
The second step is to create the data that models need to support classrooms. This involves gathering curated, consented, and representative datasets: textbooks under public licenses, anonymized exam papers, bilingual glossaries, local history archives, and speech data for lesser-known dialects. Latin America’s method—federating national collections under a regional model and then fine-tuning for each country—provides a solid template. If you want sovereign AI that can teach in Quechua or Romansh, you cannot simply rent it; you must create it. Attach data grants to teacher involvement, fund annotation, and collaborate with universities to ensure rigorous quality control.
The third step is building trust. Teachers will only use tools they can trust or understand. Ministries should create open evaluation tracks that any vendor or public lab can participate in. Define tasks that mirror classroom needs: provide detailed feedback on essays, identify bias in texts, and draft unit plans aligned with local standards. Publish the results and allow districts to choose from a trusted list. The cost of this approach is minimal compared to the expense of a failed national contract. The benefits include real choice and quicker development cycles. Lastly, it is crucial to plan for energy needs. The IEA's projections indicate that energy demand will rise. Education networks should work with national energy planners to avoid overlapping peak testing and tutoring times with times of grid stress.
We began with a stark figure: 260,000 GPUs for a single country’s sovereign AI initiative. While the exact number is significant, its implications are more important. AI is becoming a fundamental part of our infrastructure, with education set to be one of its main users. Suppose governments want models that teach in local languages, adhere to national curricula, and respect public law. In that case, the solution is not to commit to a single foreign platform. Instead, they should build shared capacity, pool risks, and, where possible, open the system. This work is already underway—from Switzerland’s open Apertus to Europe’s AI Factories, Korea’s national rollout, and Latin America’s regional models. The following steps are the responsibility of education leaders. They should treat sovereign AI as a public resource, fund it, assess its effectiveness in classroom applications, and maintain enough openness to build trust. The stakes are real. They involve the words, ideas, and feedback we present to students every day.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
AxeleraAI grant. (2025, March 6). Reuters. Dutch chipmaker AxeleraAI gets €61.6 million EU grant to develop an AI inference chip. Apertus: a fully open, transparent, multilingual language model. (2025, September 2). ETH Zurich/EPFL/CSCS (press release). Energy and AI—Executive summary & News release. (2025). International Energy Agency. Projections for data-centre electricity demand through 2030. EU AI Factories—Policy page. (2025, October 30). European Commission, Shaping Europe’s Digital Future. EuroHPC JU—Selection of the first seven AI Factories. (2024, December 10). EuroHPC Joint Undertaking. EuroHPC JU—Selects six additional AI Factories. (2025, October 10). EuroHPC Joint Undertaking. EU–Republic of Korea Digital Partnership Council. (2025, November 27–28). European Commission press corner / Digital Strategy news. Latam-GPT and the search for AI sovereignty. (2025, November 25). Brookings Institution. Mistral unveils new models in race to gain edge in “open” AI. (2025, December 3). Financial Times. NVIDIA, the South Korean government, and industrial giants are building an AI infrastructure and ecosystem. (2025, October 31). NVIDIA (press release). South Korea accepts the first batch of NVIDIA GPUs under the large-scale AI infrastructure plan. (2025, December 1). The Korea Times.
Picture
Member for
1 year 8 months
Real name
Catherine McGuire
Bio
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Central banks leaned on single models and badly misread the inflation surge
Ensemble monetary policy blends many models to create safer, more robust rate rules
Teaching and adopting ensemble monetary policy can rebuild trust through cautious, transparent decisions
Beyond the Hype: Causal AI in Education Needs a Spurious Regression Check
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
AI in education is pattern matching, not true thinking
The danger is confusing correlation with real causal insight
Schools must demand causal evidence before using AI in high-stakes decisions
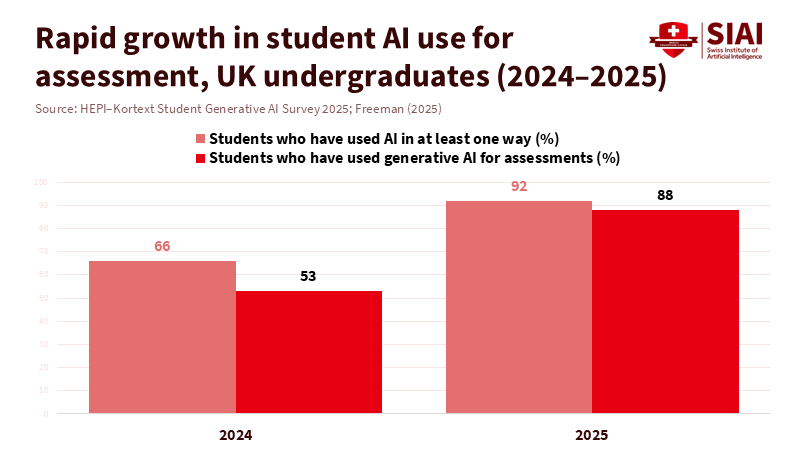
In 2025, a national survey in the United Kingdom found that 88% of university students were using generative AI tools like ChatGPT for their assessments. However, a global UNESCO survey of over 450 schools and universities found that fewer than 10 percent provided any formal guidance on the use of AI in teaching and learning. This shows that causal AI in education is growing from the ground up. At the same time, institutions debate the nature of these systems. Many public figures suggest each new model brings us closer to 'human-level' thinking. In reality, classrooms are using basic tools. Students depend on powerful pattern machines that don't truly grasp cause and effect. Education policy must recognize this before effectively using causal AI in education, emphasizing policies that promote understanding of causal relationships rather than superficial pattern-matching.
Causal AI in Education: Why Pattern Matching Is Not Intelligence
Much of the current debate assumes AI is steadily advancing towards general intelligence. When a system writes an essay or solves a math problem, some people claim the benchmarks for intelligence have shifted. This perspective overlooks what today's systems actually accomplish. They are massive engines for statistical pattern matching. They learn from trillions of words and images, identifying which tokens typically connect to others. If we define intelligence as the ability to create causal models, operate across various domains, and learn from experience, the situation looks different. These systems do not resemble self-learning agents, such as children or animals. In econometrics, this shallow connection between variables is known as spurious regression. Two lines may move in tandem, the model shows a high score, yet nothing indicates that one causes the other. That is what most generative models offer in classrooms today. They make predictions and imitate actions without understanding why. Industry professionals observe the same trend: systems excel at identifying correlations in large datasets, but humans must determine whether those signals reflect actual causal forces.
Recent evidence from technical evaluations supports this. The 2025 AI Index report indicates that while cutting-edge models now match or surpass humans on many benchmark tests, they still struggle with complex reasoning tasks like planning and logic puzzles, even when exact solutions exist. In other words, they perform well when the problem resembles their training data but fail when faced with fresh causal structures. Studies on large reasoning models from major labs tell a similar story. Performance declines as tasks become more complex, and models often resort to shortcuts rather than thinking harder. Additional work shows that top chatbots achieve high accuracy on factual questions, yet still confuse belief with fact and treat surface patterns as explanations. These are clear signs of spurious regression, not signs of minds awakening. This distinction is crucial for causal AI in education.
Spurious Regression, AGI Hype, and Causal AI in Education
Spurious regression isn't just a technical term; it reflects a common human tendency. When two trends move together over time, people want to create a narrative linking them. Economists learn to approach this impulse with caution. For instance, two countries might see rising exports and internet usage simultaneously. That doesn’t mean that browsing the web causes trade surpluses. Similarly, when a model mimics human style, passes exams, and engages in fluent conversations, people often interpret it as a sign of a thinking agent. However, what’s actually happening is more like a significant auto-complete function. The system selects tokens that fit the statistical pattern. It doesn't account for what would happen if a curriculum changed, an experiment were conducted, or a rule were broken. It lacks an innate sense of intervention. This is why causal AI in education is significant; it emphasizes what causes real-world changes rather than just what predicts the next word.
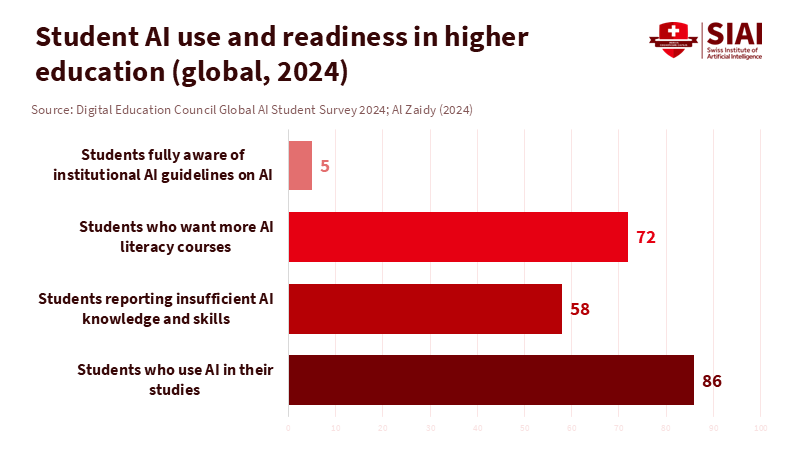
The public already senses something is amiss. Surveys indicate that just over half of adults in the United States feel more anxious than excited about AI in everyday life, with only a slight percentage feeling mostly excited. At the same time, adoption in education is rapidly advancing. A 2024 global survey found that 86% of higher education students used AI tools in their studies, with most using them weekly or more. By 2025, a survey in the United Kingdom found that 88 percent of students used generative AI tools for assessments, and more than nine in ten used AI for some academic work. Yet the same surveys showed that about half of students did not feel "AI-ready" and lacked confidence in their ability to use these tools effectively. Meanwhile, UNESCO found that fewer than one in ten institutions had formal AI policies in place. This context highlights the challenges for causal AI in education: heavy usage, minimal guidance, and significant concern.
Figure 1: Most students use AI, but very few feel prepared or know their university’s rules, exposing a readiness gap that causal AI in education must address.
Other sectors are beginning to correct similar issues by adopting causal methods. Healthcare serves as a helpful example. For years, clinical teams relied on machine learning models that ranked patients by risk. These systems were effective at identifying patterns, such as the connection between specific lab results and future complications. Still, they could not show what would happen if a treatment changed. New developments in causal AI for drug trials and care pathways aim to address this gap. They create models that ask 'what if ' questions and employ rigorous experimental or quasi-experimental designs to distinguish genuine drivers from misleading correlations. The goal isn’t to make models seem more human but to ensure their recommendations are safer and more reliable when circumstances change. Educational policy should incorporate these insights by supporting research that develops causal models capable of predicting the impact of interventions, thus ensuring AI tools in education are both effective and trustworthy in dynamic classroom environments.
Policy Priorities for Causal AI in Education
The priority is to teach the next generation what these systems can and cannot do. Currently, students see attractive interfaces and smooth language and assume there’s a mind behind the screen. Yet research tells a different story. Large language models can solve Olympiad-level math problems and produce plausible step-by-step reasoning. However, independent evaluations reveal they still struggle with many logic tasks, lose track of constraints, and cannot reliably plan over multiple steps. When tasks become more challenging, models often guess quickly instead of thinking more deeply. In classroom settings, this means AI will excel at drafting, summarizing, and spotting patterns but will fall short when asked to justify a causal claim. Educators can turn this into a valuable teaching moment. Causal AI in education should emphasize critical use of current tools by encouraging students to question model answers for hidden assumptions, missing mechanisms, and spurious regression.
The second priority is institutional. AI literacy shouldn't rely solely on individual teachers. Parents and students expect schools to take action. Recent surveys in the United States show that nearly 9 in 10 parents believe knowledge of AI is crucial for their children’s education and career success, and about 2/3 think schools should explicitly teach students how to use AI. Yet UNESCO's survey indicates that fewer than ten percent of institutions provide formal guidance. Many universities rely on ad hoc policies crafted by small committees under time pressure. This mismatch invites both overreaction and negligence. One extreme leads to blanket bans that push AI use underground and hinder honest discussion. The other leads to blind trust in "AI tutors" taking charge of feedback and assessment. A policy agenda focused on causal AI in education should ask a straightforward question: under what conditions does a specific AI tool noticeably help students learn, and how do those effects vary for different groups?
Answering that question requires better evidence. The tools of causal AI in education are practical, straightforward methods that many institutions already use in other areas. Randomized trials can compare sections using an AI writing assistant to those that do not, tracking not only grades but also the transfer of skills to new tasks. Quasi-experimental designs can study the impact of AI-enabled homework support in districts that introduce new tools in phased implementations. Learning analytics teams can shift from dashboards that merely describe past behavior to models that simulate the consequences of changes in grading rules or feedback styles. None of this necessitates systems that think like humans; it requires clarity about causes and careful control groups. The potential benefits are considerable. Rather than debating abstractly whether AI is "good" or "bad" for learning, institutions can begin to identify where causal AI in education truly adds value and where it merely automates spurious regression.
Figure 2: In just one year, UK students moved from majority to near-universal AI use, especially for assessments, showing why causal AI in education policy cannot wait.
The final priority is to establish regulatory clarity. Governments are rapidly addressing AI in general, but education often remains on the sidelines of those discussions. Regulations that treat all advanced models as steps toward general intelligence can overlook the real risks. In education, the most urgent dangers arise from pattern-matching systems that appear authoritative while concealing their limitations. Recent technical studies show that even leading chatbots released after mid-2024 still struggle to distinguish fact from belief and can confidently present incorrect explanations in sensitive areas such as law and medicine. Other research highlights a significant drop in accuracy when reasoning models tackle more complex challenges, even though they perform well on simpler tasks. These are not minor issues on the path to human-like thought; they signal the risks of relying too heavily on correlation. Regulations shaped by causal AI in education should mandate that any high-stakes use, such as grading or placement, undergo experimental testing for robustness to change, rather than relying solely on benchmark scores based on past data.
Education systems face a critical choice. One path tells a story where every new AI breakthrough prompts us to redefine intelligence and brings us closer to machines that think like us. The other path presents a more realistic view. In this perspective, today’s systems are fast, cost-effective engines for statistical fitting that can benefit classrooms when used responsibly. They can also cause serious issues if we confuse spurious regression with genuine understanding. The statistics presented at the beginning should draw attention. When nearly 90% of students depend on AI for their work, and fewer than 10% of institutions provide solid guidance, the problem isn't that machines are becoming too intelligent. Instead, the issue is that policy isn't smart enough about machines. The task ahead is straightforward. Foster a culture of causal AI in education that encourages students to question patterns, empowers teachers to conduct simple experiments, and insists on evidence before high-stakes deployment. If we succeed, the goalposts do not need to shift at all.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
College Board. (2025). U.S. high school students’ use of generative artificial intelligence. Research Brief. DIA Global Forum. (2024). Correlation vs. causation: How causal AI is helping determine key connections in healthcare and clinical trials. Digital Education Council. (2024). Key results from DEC Global AI Student Survey 2024. Higher Education Policy Institute. (2025). Student generative AI survey 2025. Pew Research Center. (2023). What the data says about Americans’ views of artificial intelligence. Qymatix. (2025). Correlation and causality in artificial intelligence: What does this mean for wholesalers? Stanford Institute for Human-Centered Artificial Intelligence. (2025). AI Index Report 2025. UNESCO. (2023). Guidance for generative AI in education and research: Executive summary.
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
The US funds fabs but lacks skilled workers
Asian firms plug gaps with temporary foreign technicians
Real fix: serious US semiconductor workforce training
Governing at Machine Speed: How to Prevent AI Bank Runs from Becoming the Next Crisis
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
AI is accelerating bank-run risk into “AI bank runs”
Supervisors lag far behind banks in AI tools and skills
We need real-time oversight, automated crisis tools, and targeted training now
In March 2023, a mid-sized American bank experienced a day when depositors attempted to withdraw $42 billion. Most of this rush came from simple phone taps, not from long lines outside the bank. Although this scramble did not yet use fully autonomous systems, it demonstrated how quickly fear can spread when money moves as fast as a push notification. Now, imagine an added layer. Corporate treasurers use AI tools to track every rumor. Households rely on chatbots that adjust savings in real time. Trading engines react to each other's moves in milliseconds. The outcome is not a traditional bank run. Instead, it’s the potential for AI-driven bank runs, in which algorithms trigger, amplify, and execute waves of withdrawals and funding cuts long before human supervisors can act.
Why AI Bank Runs Change the Crisis Playbook
Systemic banking crises have always involved everyone rushing for the same exit at the same time. In the past, this coordination relied on rumors, news broadcasts, and human analysis of financial reports spread over hours or days. Today, AI systems can scan markets, social media, and private data streams in seconds. They update risk models and send orders almost immediately. The rush that caused Silicon Valley Bank’s collapse was one example. Customers attempted to withdraw tens of billions of dollars in a single day, highlighting the power of digital channels and online coordination. Future AI bank runs will shorten that timeline even more. Automated systems will learn to respond not only to general news but also to each other’s activities in markets and payment flows. Tools that smooth out minor fluctuations during calm periods can trigger sudden, synchronized movements during stressful periods.
The groundwork for AI bank runs is already established. In developing economies, the percentage of adults making or receiving digital payments grew from 35 percent in 2014 to 57 percent in 2021. In high-income economies, this percentage is nearly universal. Recent Global Findex updates show that 42 percent of adults made a digital payment to a merchant in 2024, up from 35 percent in 2021. At the same time, 86 percent of adults worldwide now own a mobile phone, and 68 percent have a smartphone. On the supply side, surveys conducted by European and national authorities indicate that a clear majority of banks currently use AI for tasks like credit scoring, fraud detection, and trading. This means that the technical ability for AI bank runs is in place today. Highly digital customers, near-instant payments, and widespread AI use among firms are all established. What is lacking is a supervisory framework that can monitor and influence these dynamics before they develop into full-blown crises.
What Emerging Markets Teach Us about AI Bank Runs
The weakest link in this situation is not the sophistication of private sector tools but the readiness of supervisory agencies. A recent survey of 27 financial sector authorities in emerging markets and developing economies shows that most anticipate AI will have a net positive effect. Yet their own use of AI for supervision remains limited. Many authorities are still in pilot mode for essential tasks such as data collection, anomaly detection, and off-site monitoring. Only about a quarter have formal internal policies on AI use. In parts of Africa, the percentage is even lower. The usual barriers are present. Data is often fragmented or incomplete. IT systems may be unreliable. Staff with the right technical skills are scarce. Concerns about data privacy, sovereignty, and vendor risk add further complications. Supervisors face the threat of AI bank runs with inadequate tools, incomplete data, and insufficient personnel.
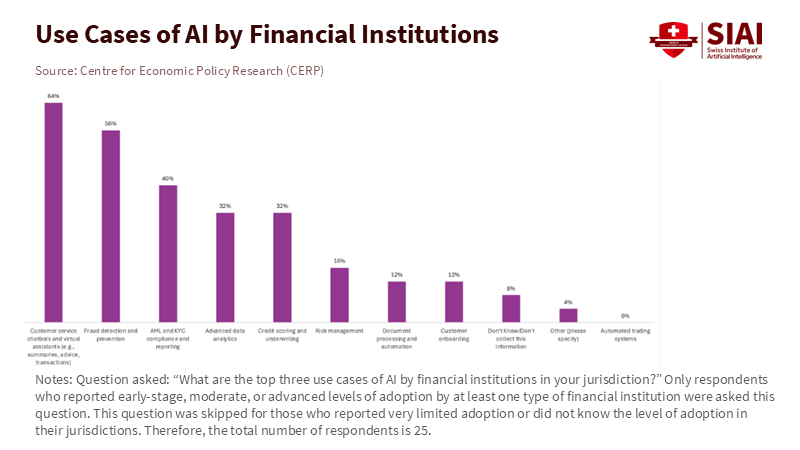
In contrast, financial institutions in these same regions are advancing more quickly. The survey reveals that where AI is implemented, banks and firms focus on customer service chatbots, fraud detection, and anti-money laundering checks. African institutions are more inclined to use AI for credit scoring and underwriting in markets with limited data. These applications may seem low risk compared to high-frequency trading. However, they can create new pathways for a sudden loss of trust. A failure in an AI fraud detection system can freeze thousands of accounts simultaneously. A flawed credit model can halt lending in entire sectors overnight. The Financial Stability Board has noted that many authorities, including those in advanced economies, struggle to monitor AI-related vulnerabilities using current data-collection methods. Therefore, emerging markets serve as an early warning system. They illustrate how quickly a gap can widen between supervised firms and supervisory agencies. They also show how that gap can evolve into a serious vulnerability if not treated as an essential issue.
Figure 1: AI in emerging-market banks is concentrated in customer service, fraud/AML, and analytics, showing how fast private adoption is racing ahead of supervisory capacity.
Designing Concrete Defenses against AI Bank Runs
If AI bank runs pose a structural risk, then mere "AI-aware supervision" is insufficient. Authorities need a solid framework for prevention and response. The first building block is straightforward but often overlooked. Supervisors need real-time insight into where AI is used within large firms. Some authorities have begun asking banks to disclose whether they use AI in areas such as risk management, credit, and treasury. The results are inconsistent and hard to compare. A more serious method would treat high-impact AI systems like vital infrastructure. Banks would maintain a live register of models that influence liquidity management, deposit pricing, collateral valuation, and payment routing. This register should include key vendors and data sources. Supervisors could then see where similar models or vendors are used across institutions and where synchronized actions might occur under stress. This step is essential for any coherent response to AI bank runs.
The second building block is shared early warning systems that reflect, at least partially, the speed and complexity of private algorithms. Some central banks already conduct interactive stress tests in which firms adapt their strategies as conditions change. Groups of authorities could build on this idea and use methods such as federated learning to jointly train models on local data without sharing raw data. These supervisory models would monitor not just traditional indicators but also the behavior of high-impact AI systems across banks, payment providers, and large non-bank platforms. Signals from these models, combined with insights about vendor concentration, would enable authorities to detect when AI bank runs are developing. They wouldn’t simply observe deposit outflows after the fact.
The third building block is crisis infrastructure that can act quickly when early warnings appear. Authorities already use tools such as market circuit breakers and standing liquidity facilities. For AI bank runs, these tools must be redesigned with automated triggers. This could mean pre-authorized liquidity lines that activate when particular patterns of outflows are detected across multiple institutions. It might involve temporary restrictions on certain types of algorithmic orders or instant transfer products during extreme stress. None of this eliminates the need for human judgment. It simply acknowledges that by the time a crisis committee gathers, AI-driven actions may have already changed balance sheets. Without pre-set responses linked to well-defined metrics, supervisors will remain bystanders in events they should oversee.
An Education Agenda for an Era of AI Bank Runs
These defenses will be ineffective if they rely on a small group of technical experts. The survey of emerging markets highlights that internal skill shortages are a significant obstacle to the use of AI in supervision. This issue is also prevalent in many advanced economies, where central bank staff and frontline supervisors often lack practical experience with modern machine learning tools. At the same time, most adults now carry smartphones, send digital payments, and interact with AI-powered systems in their daily lives. The human bottleneck lies within the authorities, not beyond them. Bridging that gap is therefore as much an educational challenge as it is a regulatory one. It requires a new collaboration between financial authorities, universities, and online training providers.
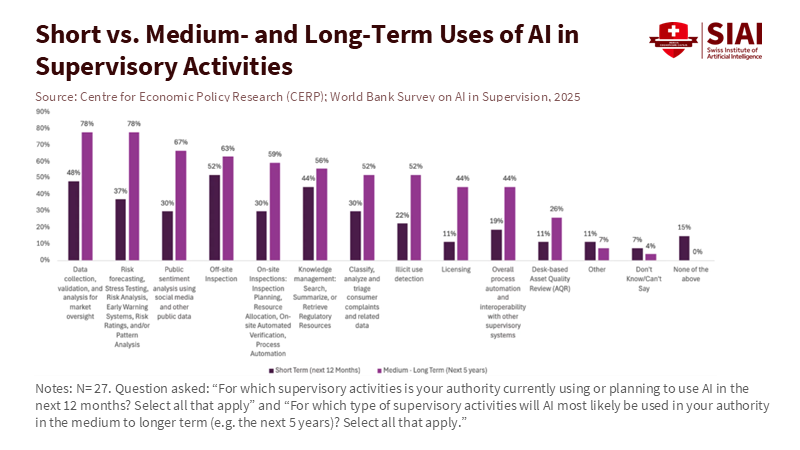
Figure 2: Supervisors plan to use AI first for data and risk analysis, while more complex tasks stay in the medium-to-long-term bucket, revealing a strategic but still cautious adoption path.
That collaboration should start with the reality of AI bank runs, not with vague courses on "innovation." Supervisors, policymakers, and bank risk teams need access to practical programs. These should blend basic coding and data literacy with a solid understanding of liquidity risk, market dynamics, and consumer behavior in digital settings. Scenario labs where participants simulate AI bank runs can be more effective than traditional lectures for building intuition. In these exercises, chatbots, robo-advisers, treasurers, and central bank tools all interact on the same screen. Micro-credentials for board members, regulators, and journalists can spread that knowledge beyond just a small group of experts. Online education platforms can make these resources available to authorities in low-income countries that can’t afford large in-house training programs. The goal isn’t to turn every supervisor into a data scientist. It is to ensure that enough people in the system understand what an AI bank looks like in practice. Only then can the institutional response be informed, swift, and coordinated.
The window to act is still open. The same global surveys that indicate rapid adoption of AI in banks also show that supervisors’ use of AI remains at an earlier stage. The gap is vast in emerging markets. Today’s digital bank runs, like the surge that caused a mid-sized lender to collapse in 2023, still unfold over hours instead of seconds. However, that margin is decreasing as AI transitions from test projects to essential systems in both finance and everyday life. Authorities can still alter their path. Investments in data infrastructure, shared supervisory models, machine-speed crisis tools, and a serious education agenda can prevent AI bank runs from becoming the major crises of the next decade. If they hesitate, the next systemic event may not begin with a rumor in a line. It may start with a silent cascade of algorithm-driven decisions that no one in charge can detect or understand.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank of England. 2024. Artificial intelligence in UK financial services 2024. London: Bank of England. Boeddu, Gian, Erik Feyen, Sergio Jose de Mesquita Gomes, Serafin Martinez Jaramillo, Arpita Sarkar, Srishti Sinha, Yasemin Palta, and Alexandra Gutiérrez Traverso. 2025. “AI for financial sector supervision: New evidence from emerging market and developing economies.” VoxEU, 18 November. Danielsson, Jon. 2025. “How financial authorities best respond to AI challenges.” VoxEU, 25 November. European Central Bank. 2024. “The rise of artificial intelligence: benefits and risks for financial stability.” Financial Stability Review, May. Federal Deposit Insurance Corporation. 2023. “Recent bank failures and the federal regulatory response.” Speech by Chairman Martin J. Gruenberg, 27 March. Financial Stability Board. 2025. Monitoring adoption of artificial intelligence and related technologies. Basel: FSB. Financial Times. 2024. “Banks’ use of AI could be included in stress tests, says Bank of England deputy governor.” 6 November. Visa Economic Empowerment Institute. 2025. “World Bank Global Findex 2025 insight.” 9 October. World Bank. 2022. The Global Findex Database 2021: Financial inclusion, digital payments, and resilience in the age of COVID-19. Washington, DC: World Bank. World Bank. 2025a. “Mobile-phone technology powers saving surge in developing economies.” Press release, 16 July. World Bank. 2025b. Artificial Intelligence for Financial Sector Supervision: An Emerging Market and Developing Economies Perspective. Washington, DC: World Bank.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Osaka second capital now anchors a fragile coalition
Capital shift could widen or rebalance regional education
Classrooms can use this debate to teach coalition politics