From Dialogue to Directive: How the Xiangshan Forum Became China’s Classroom for Global Governance
Xiangshan Forum is China’s planning room for global governance Beijing fuses hard power and finance to shape rules Education must teach Xiangshan-era governance, standards, and AI/security

T
From Freeze to Flow: Governing Euroclear’s Windfall on Immobilised Russian Assets
EU freezes ~€210bn; windfall profits flow, not principal Route proceeds via EU/G7 loans to steady, education-first support Preserve trust: strict legality, transparency, shared risk

A single number now shapes the conversation: a
Beyond the AGI Hype: Why Schools Must Treat AI as Probability, Not Reasoning
Beyond the AGI Hype: Why Schools Must Treat AI as Probability, Not Reasoning

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
AI today is pattern-matching, not reasoning—resist AGI hype Redesign assessments for explanation, sources, and uncertainty Procure on outcomes and risk logs; keep humans in charge

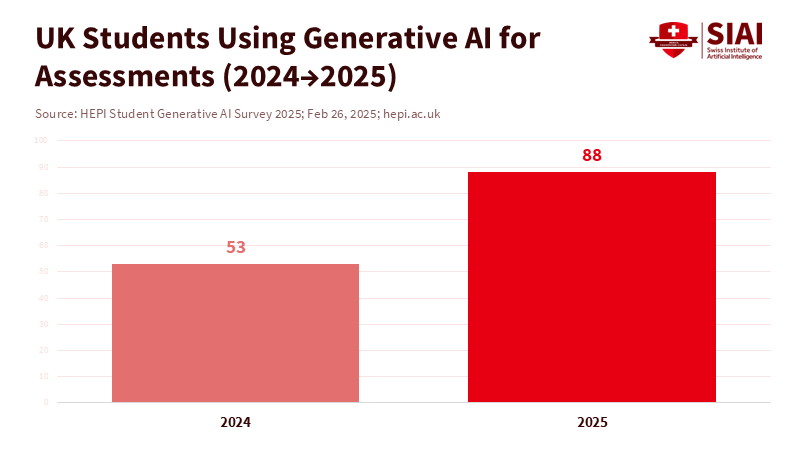
The core challenge facing schools this year is not whether to use AI, but how to understand what it is: an engine of sophisticated pattern prediction, not genuine reasoning. In the United Kingdom, 92 percent of university students now use generative AI for academic work, and 88 percent use it for assessments—evidence of changing day-to-day learning. The real risk is misinterpreting these tools as students do. If education systems treat probability engines as minds, they risk confusing fluency for proper understanding and speed for mastery. Policy should focus on what these systems actually do: they make predictions based on data, not on the way humans reason. By recognizing this, schools can make strategic decisions that enhance productivity and feedback without compromising standards or judgment.
AGI hype and the difference between probability and reasoning
Here is the main point. Today’s leading models mostly connect learned associations. Their outputs seem coherent because the training data are extensive and the patterns are rich. However, the mechanism remains statistical prediction rather than grounded reasoning. Consider two facts. First, training compute has exploded—roughly doubling every six months since 2010—because greater scale enables better pattern matching across many areas. Second, when evaluation is cleaned of leaks and shortcuts, performance declines. These two trends support a clear conclusion: gains come from more data, more compute, and more clever sampling at test time, not from a leap to general intelligence. Education policy should focus on robust probability rather than artificial cognition.
The phrase “reasoning models” adds confusion. Yes, some new systems take more time to think before answering and score much higher on complex math. OpenAI reports that its O1 line improved from 12 percent to 74 percent on the AIME exam with single attempts. That is real progress. However, it is narrow, costly, and sensitive to the choice of prompt design and evaluation. This tells us that staged searches over intermediate steps help with well-defined problems, not that the model has acquired human-like understanding. Schools should not confuse a better solver in contest math with a reliable explainer across complex, interdisciplinary tasks. In classrooms, we need tools that can retrieve sources, expose uncertainty, and withstand checks for contamination and hallucination. “More correct answers on a benchmark” is not the same as “more trustworthy learning support.”
AGI hype in the funding cycle and what it does to classrooms
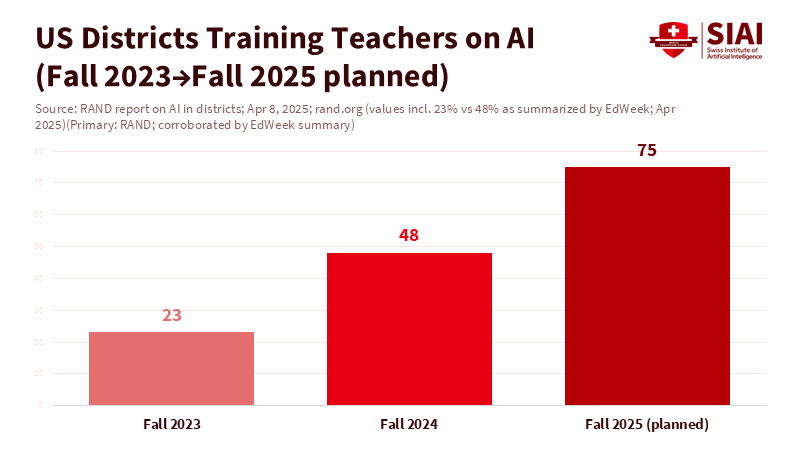
The money flowing into generative AI is significant and increasing. In 2024, private AI investment in the United States reached about $109 billion. Funding for generative AI climbed to around $34 billion worldwide, up from 2023. Districts are reacting: by fall 2024, nearly half of U.S. school districts had trained teachers on AI, a 25-point increase in just one year. Students are moving even faster, as the U.K. figure shows. This is the AGI hype cycle: capital fuels product claims; product claims drive adoption; and adoption creates pressure to buy more and make more promises. The danger is not in adoption itself. It is how hype blurs the line between what AI does well—summarizing, drafting, style transfer, code scaffolding—and what education needs for durable learning—argument, transfer, and critique.
Skepticism has not slowed use. A recent national survey in the U.S. found that about 70 percent of adults have used AI, and around half worry about job losses. In schools, many teachers already report time savings from routine tasks. Gallup estimates that regular users save about 6 hours a week, about 6 weeks over a typical school year. Those are significant benefits. But productivity gains come with risks. NIST’s updated AI risk guidance emphasizes how models can be fragile and overconfident, with hallucinations persisting even in the latest systems. Education leaders should recognize both sides of that equation: significant time savings on one hand, and serious failure modes on the other, amplified by hype.
Design for probability: assessment, curricula, and guardrails
If we acknowledge that current systems are advanced probability matchers, then policy must shape the workflow to leverage probability when helpful and limit it when it causes harm. Start with an assessment. Exams that reward surface fluency invite model-aided answers that look right but lack genuine understanding. The solution is not a ban; it is stress-testing. The U.K. proposal for universities to stress-test assessments is a good example: move complex tasks into live defenses, stage drafts with oral checks, and require portfolios that document the provenance of artifacts. Retrieval-augmented responses with citations should be standard, and students should be able to explain and replicate their steps within time limits. This is not a nostalgic return to pen-and-paper. It aligns with how these tools actually function. They excel at drafting but struggle to provide verifiable chains of reasoning without support. Design accordingly—and name the approach for what it is: a straightforward resistance to AGI hype.
Curricula should make uncertainty visible. Teachers can create activities in which models must show their sources, state confidence ranges, and defend each claim against another model or a curated knowledge base. This is where risk frameworks come in. NIST’s guidance and Stanford’s HELM work suggest evaluation practices that assess robustness, not just accuracy, across tasks and datasets. Dynamic evaluation also counters benchmark contamination. When tasks change, memorized patterns break, revealing what models can and cannot do. Building this habit in classrooms helps students distinguish between plausible and supported answers. It also fosters a culture in which AI is a partner that requires examination. That is the literacy we need far more than prompt tricks.
Managing the next wave of AGI hype in policy and procurement
Education ministries and districts face a procurement challenge. Vendors use the language of “reasoning,” but contracts must focus on risk and value. A practical approach is to write requirements that reflect probability rather than personhood. Demand audit logs of model versions, prompts (the input commands or queries given to AI), and retrieval sources. Require default uncertainty displays (visual markers of answer confidence) and simple toggles that enforce citations in student-facing outputs. Mandate out-of-distribution tests (tests on data different from what the model saw in training) during pilot projects. Tie payment to improvements in verified outcomes—reducing time-to-feedback, gaining in transfer tasks (applying knowledge in new contexts), or fewer grading disputes—not to benchmark headlines. Use public risk frameworks as a foundation, then add domain-specific checks, such as content provenance (a clear record of the source material) for history essays and step-wise explanations (detailed breakdowns of each stage in a solution) for math. This is how we turn AGI hype into measurable classroom value.
Teacher development needs the same clarity. The RAND (Research and Development) findings show rapid growth in training across districts, but the training content often lags behind actual tool use. Teachers need three things: how to use AI to speed up routine work without losing oversight, how to create assignments that require explanation and replication, and how to teach AI literacy in simple terms. That literacy should cover both the social aspects—bias (unfair preferences in outputs) and fairness—and the statistical aspects—what prediction means, how sampling (choosing from possible AI responses) can alter results, and why hallucinations (AI-generated errors) occur. UNESCO’s (United Nations Educational, Scientific, and Cultural Organization) guidance is clear about the need for human-centered use. Make that tangible with lesson plans that encourage students to challenge model claims against primary sources, revise model drafts with counter-arguments, and label unsupported statements. Time saved is real; so must be the structure ensuring learning.
What this means for research, innovation, and the road to real reasoning
Research is moving quickly. Google and OpenAI have announced significant progress in elite math competitions and complex programming tasks, often by increasing test-time compute and exploring more reasoning paths. These accomplishments are impressive. However, they also show the gap between success in contests and everyday reliability. Many of these achievements depend on long, parallel chains of sampled steps and expensive hardware. They do not transfer well to noisy classroom prompts about local history or unclear policy debates. As new benchmarks come out to filter out bias and manipulation, we see a more modest view of progress in broad reasoning. The takeaway for education is not to overlook breakthroughs, but to view them as examples under specific conditions rather than as guarantees for general use. We should use them where they excel—such as in math problem-solving and code generation with tests—while keeping human understanding at the forefront.
We started with the number 92. It highlights the reality that generative AI is already part of the assessment process. The risk is not in the tool itself; it is in the myth that the tool can now “reason” like a student or a teacher. In reality, today’s systems are extraordinary engines of probability. Their scale and intelligent searching have made them fluent, helpful, and often correct, but not reliably aware of their limitations. When refined evaluations eliminate shortcuts and leaks, performance falls in ways that matter for education. That is why policy should resist AGI hype and design for the systems we actually have. Build assessments that value explanation and verification. Procure products that log, cite, and quantify uncertainty by default. Train teachers to use AI for efficiency while teaching students to question it. Keep human judgment—slow, careful, and accountable—at the core. If we accomplish this, we can gain the benefits of productivity and feedback without compromising standards or trust. We can also prepare for the day when reasoning goes beyond a marketing claim—because our systems will be ready to test it, measure it, and prioritize learning first.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Axios. “Americans are using and worrying about AI more than ever, survey finds.” December 10, 2025.
Deng, C. et al. “Investigating Data Contamination in Modern Benchmarks for Large Language Models.” NAACL 2024.
Epoch AI. “The training compute of notable AI models has been doubling roughly every six months.” June 19, 2024.
Gallup. “Three in 10 Teachers Use AI Weekly, Saving Six Weeks per Year.” June 24, 2025.
NIST. Artificial Intelligence Risk Management Framework (AI RMF 1.0 update materials). July 25, 2024.
NIST. “Assessing Risks and Impacts of AI (ARIA) 0.1.” November 2025.
OpenAI. “Learning to reason with LLMs (o1).” September 12, 2024.
RAND Corporation. “More Districts Are Training Teachers on Artificial Intelligence.” April 8, 2025.
Stanford HAI. AI Index Report 2025. 2025.
The Guardian. “UK universities warned to ‘stress-test’ assessments as 92% of students use AI.” February 26, 2025.
UNESCO. “Guidance for generative AI in education and research.” Updated April 14, 2025.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
















The New Curriculum of Power: How a Tariff World Will Reshape Education
Trump 2.0 tariffs: 10% floor, 15% for dealmakers Campus costs climb—labs, AI gear, construction—equity gaps widen Plan for persistence: pool procurement, secure exemptions, fund aid and labs

Beyond the Paycheck: Non-Monetary Compensation Should Reshape Education Labor Policy
Benefits and working conditions make up a third to two-fifths of pay Unions shift value into enforceable rights when cash is tight, boosting retention Measure and fund non-monetary compensation to stabilize schools

Off-Planet Compute, On-Earth Learning: Why "Space Data Centers" Should Begin with Education
Off-Planet Compute, On-Earth Learning: Why "Space Data Centers" Should Begin with Education
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
Use space data centers to ease Earth’s compute and water strain—start with education Run low-latency classroom inference in LEO; keep training and sensitive data on Earth Pilot with strict SLAs, life-cycle audits, and debris plans before scaling

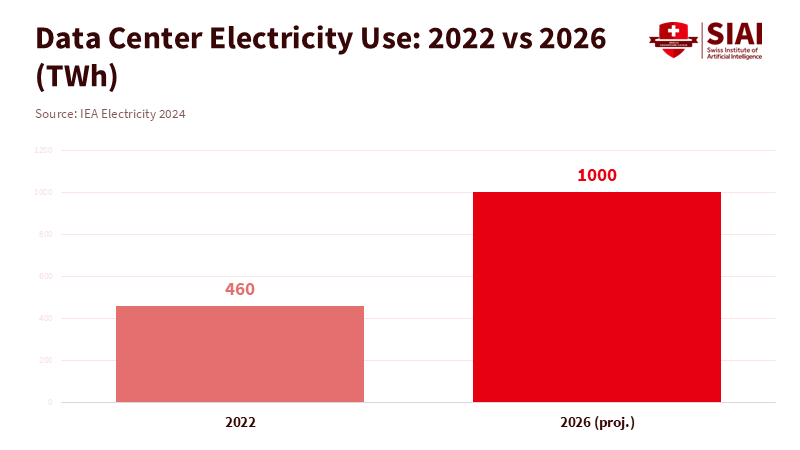
The key figure we should focus on is this: global data centers could use more than 1,000 terawatt-hours of electricity by 2026. This accounts for a significant share of global power consumption and is increasing rapidly as AI transitions from labs to everyday workflows. While this trend offers tangible benefits, it also creates challenges in areas with limited budgets, particularly in schools and universities. Water-scarce towns now face pressure from new server farms. Power grids can delay connections for years. Campuses see rising costs for cloud-based tools or experience slowdowns when many classes move online simultaneously. The concept of space data centers may sound like science fiction. Still, it addresses a pressing, immediate policy goal: expanding computing resources for education without further straining local water, land, and energy supplies. If we want safe, fair AI in classrooms, the real question is no longer whether the idea is exciting. The question is whether education should drive the initial trials, establish guidelines, and define the procurement rules that follow.
Reframing Feasibility: Space Data Centers as Education Infrastructure
Today's debate tends to focus on engineering bravado—can we lift racks into orbit and keep them cool? This overlooks the actual use case. Education needs reliable, fast, and cost-effective processing for millions of small tasks: grading answers, running speech recognition, translating content, and powering after-school AI tutors. These tasks can be spread out, stored, and timed. They do not all require immediate processing, as a Wall Street trader or a gamer does. The reframing is straightforward: view space data centers as a backup and support layer for public-interest computing. Keep training runs and the most sensitive student data on the ground. Offload bursty, repeatable processing jobs to orbital resources during peak times, nights, or exam periods. Education, not advertising or cryptocurrencies, is the best starting point because it offers high social returns, has predictable demand (at the start of terms and during exam periods), and can accept slightly longer processing times—if managed well—in many situations.
This viewpoint is critical now because the pressures on Earth-based resources are real. The International Energy Agency predicts that data center electricity use could surpass 1,000 TWh by 2026 and continue to rise toward 2030, even without a fully AI-driven world. Water resources are equally stretched. A medium-sized data center can consume about 110 million gallons of water per year for cooling. In 2023, Google alone reported over 5 billion gallons used across its sites, with nearly a third drawn from areas facing medium to high water shortages. When a district must choose between building a new school or a new power substation, the trade-off becomes significant. Shifting part of the computing layer to continuous, reliable solar power in orbit does not eliminate these trade-offs, but it can alleviate them if initial efforts prioritize public needs and include strict environmental accounting from the outset.
What the Numbers Say About Space Data Centers
Skeptics are right to ask for data, not just metaphors. Launch costs to put equipment into orbit have dropped, with SpaceX offering standard rates. Several companies are studying ways to make space data centers work and believe it could bring environmental benefits under certain conditions. Technology leaders are also researching prototypes that use solar energy and new communication methods. These projects are at an early stage, but offer an opportunity for policy planning to occur alongside engineering.
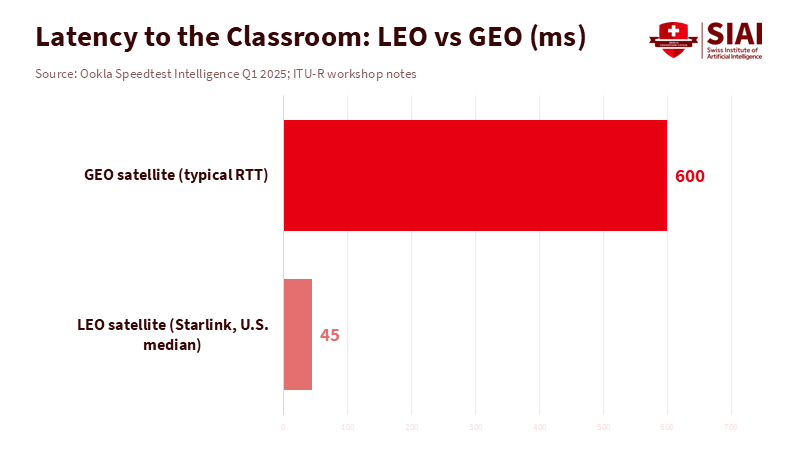
Latency is the second important metric for classrooms. LEO satellite networks already achieve median latencies in the 45-80 ms range, depending on routing and timing, which is comparable to many terrestrial connections. This is insufficient for high-frequency trading but acceptable for most educational technology tasks, such as real-time captioning and adaptive learning, when caching is used effectively. Peer-reviewed tests conducted in 2024-2025 show steady improvements in low-orbit latency and packet loss. The implication is clear: if processing is staged near ground points, and if content is cached at the orbital edge, numerous educational tasks can run without noticeable delays. Training large models will remain on Earth or in a hybrid cloud, where power, maintenance, and compliance are more manageable. However, the inference tier—the part that impacts schools—can be moved. This is where the new capacity offers the most support and causes the least disruption.
Latency, Equity, and the Classroom Edge with Space Data Centers
The case for equity is strong. Rural and small-town schools often have limited access to reliable infrastructure. When storms, fires, or heat waves occur, they are the first to lose service and take the longest to recover. Space data centers could serve as a floating edge, keeping essential learning tools operational even when local fiber connections are down or power is limited. A school district could sync lesson materials and assessments with orbital storage in advance. During outages, student devices can connect via any available satellite link and access the cached materials, while updates wait until connections stabilize. For special education and language access, where speech-to-text and translation are critical during class, this buffer can make a major difference. The goal is to design for processing near content, rather than pursuing flashy claims about space training.
The environmental equity argument is also essential. Communities near large ground data centers bear the burden of water usage, diesel backups, and noise. Moving some processing off-planet does not eliminate launch emissions or the risk of space debris, but it can reduce local stressors on vulnerable watersheds. To be credible, however, initial efforts should provide complete reports on carbon and water use throughout the life cycle: emissions from launches, in-space operations, de-orbiting, debris removal, and the avoided local cooling and water use. Educators can enforce this transparency through their purchasing decisions. They can require independent environmental assessments, mandate end-of-life de-orbiting plans, and tie payments to verified ecological performance rather than mere promises. When approached in this manner, space becomes a practical tool for relieving pressure on Earth as we develop more sustainable grids and regulations.
A Policy Roadmap to Test and Govern Space Data Centers
The main recommendation is to launch three targeted, controlled pilot programs over two school years to shape education technology proactively. The first pilot focuses on content caching, in which national education bodies and open-education providers pre-position high-use resources for reading support in orbit via low-orbit satellites, targeting under 100 ms latency and strict privacy. The second pilot tests AI inference by evaluating speech recognition, captioning, and formative feedback on orbital nodes, ensuring reliable terrestrial backups and maintaining logs for bias and error assessment. The third pilot provides emergency continuity during outages or storms, prioritizing students needing assistive tech. Each pilot includes a ground control group to measure actual educational gains and improvements in access, not just network metrics.
Procurement and governance must go hand in hand—take decisive steps to shape them now. Ministries and agencies should immediately design model RFPs that pay only for actual processing, limit data in orbit to 24 hours unless consent is given, and require end-to-end encryption managed on Earth. Insist that providers map education rules like FERPA/GDPR to orbital processes, enforce latency standards, and fully commit to zero-trust security. Demand signed debris-mitigation and de-orbiting plans in every contract and tie payments to verified environmental outcomes. Do not wait for commercial offers: by setting these requirements now, education can become the leader—and the primary beneficiary—in the responsible, innovative adoption of space data center technology.
The Market Will Come—Education Should Set the Terms
The commercial competition is intensifying. Blue Origin has reportedly been working on orbital AI data centers, while SpaceX and others are investigating upgrades that could support computing loads. Startups are proposing “megawatt-class” orbital nodes. Tech media often portrays this as a battle among large companies, but the initial steady demand may come from the public sector. Education spends money in predictable cycles, values reliability over sheer speed, and can enter multi-year capacity agreements that reduce risks for early deployments. The ASCEND study indicates feasibility; Google’s team has shared plans for a TPU-powered satellite network with optical links; academic research outlines tethered and cache-optimized designs. None of this guarantees costs will be lower than ground systems in the immediate future. Still, it presents a path for specific, limited tasks where the overall cost, including water and land, is less per learning unit. That should be the key measure guiding us.
What about the common objections? Cost is a genuine concern, but declining launch prices and improved packing densities change the game. A tighter focus on processing tasks and caching means less reliance on constant, high-bandwidth data transfers. Latency is manageable with LEO satellites and intelligent routing, as field data now shows median latencies in mature markets of tens of milliseconds. Reliability can be improved through backup systems, graceful degradation of ground systems, and resilience during disasters. Maintenance is a known challenge; small, modular units with planned lifespans and guaranteed de-orbit procedures mitigate that risk. And yes, rocket emissions are significant; this is where complete life-cycle accounting and limits on the number of launches per educational task must be included. The underwater Project Natick initiative offers a helpful analogy: careful design in challenging environments can lead to better reliability than on land. The same discipline should apply to space. If these conditions are met, pilots can advance without greenwashing.
The path to improved learning goes straight through computing. We can continue to argue over permits for substations and water rights, or we can introduce a new layer with different demands and challenges. The opening statistic—more than 1,000 TWh of electricity used by data centers by 2026—is not just a number for a school trying to keep devices charged and cloud tools functioning. It explains rising costs, community pushback, and why outages affect those with the least resources first. Space data centers are not a magic solution. They are a way to increase capacity, reduce local pressures, and strengthen the services students depend on. If education takes the lead in this first round—through small, measurable pilots, strict privacy and debris regulations, and performance-based contracts—we can transform a lofty goal into a grounded policy achievement. The choice is not between dreams in space and crises on Earth. It is about allowing others to dictate the terms or establishing rules that prioritize public education first. Now is the time to draft those rules.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Ascend Horizon. (n.d.). Data centres in space.
EESI. (2025, June 25). Data Centers and Water Consumption.
Google. (2025, Nov. 4). Meet Project Suncatcher (The Keyword blog).
IEA. (2024). Electricity 2024 – Executive summary.
IEA. (2025). Energy and AI – Energy demand from AI.
Lincoln Institute of Land Policy. (2025, Oct. 17). Data Drain: The Land and Water Impacts of the AI Boom.
Microsoft. (2020, Sept. 14). Project Natick underwater datacenter results.
Ookla. (2025, June 10). Starlink’s U.S. performance is on the rise.
Reuters. (2025, Dec. 10). Blue Origin working on orbital data center technology — WSJ.
Scientific American. (2025, Dec.). Space-Based Data Centers Could Power AI with Solar.
SpaceX. (n.d.). Smallsat rideshare program pricing.
Thales Alenia Space. (2024, June 27). ASCEND feasibility study results on space data centers.
The Verge. (2025, Dec. 11). The scramble to launch data centers into space is heating up.
Vaibhav Bajpai et al. (2025). Performance Insights into Starlink’s Latency and Packet Loss (preprint).
Wall Street Journal. (2025, Dec. 11). Bezos and Musk Race to Bring Data Centers to Space.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
The Omnibus Isn’t Neutral: Why Europe’s Shortcut to “Simplification” Could Lock In Big Tech—and How Others Should Respond
Omnibus simplification risks deepening Big Tech lock-in Bind it to portability, open APIs, and switching If others copy, copy the guardrails—not consolidation

Europe spent roughly €61 b
Make It Real: Why Europe Must Finish the Job on a European Safe Asset
EU-Bonds cost more than Bunds due to design and index rules Make them sovereign: permanent issuance, one agency, hedging tools, clear own resources Tighter spreads free billions for education and investment

In mid-2025, the European Comm
Names, Signals, and Fairness: Designing Blindness That Actually Works
Treat blind hiring policy as a targeted tool, not a cure-all Recent pilots show anonymity widens access while quality holds steady Use a tiered process—Stage-1 blind scoring, controlled unblinding, and outcome audits—to balance equity and excellence

Counting the Japan-China Business Costs of Nationalist Politics
Nationalist politics inflates Japan–China business costs, risking $292.6B in trade Controls and bans snarl inputs, travel, and seafood, squeezing factories and SMEs The fix: de-risk, don’t decouple—transparent dashboards, precise licenses, targeted insurance
