Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
SB 53 is AI safety policy that also shapes U.S. competitiveness
If it slows California labs, China’s open-weight ecosystem gains ground
Make it work by pairing clear safety templates with fast evaluation and public compute
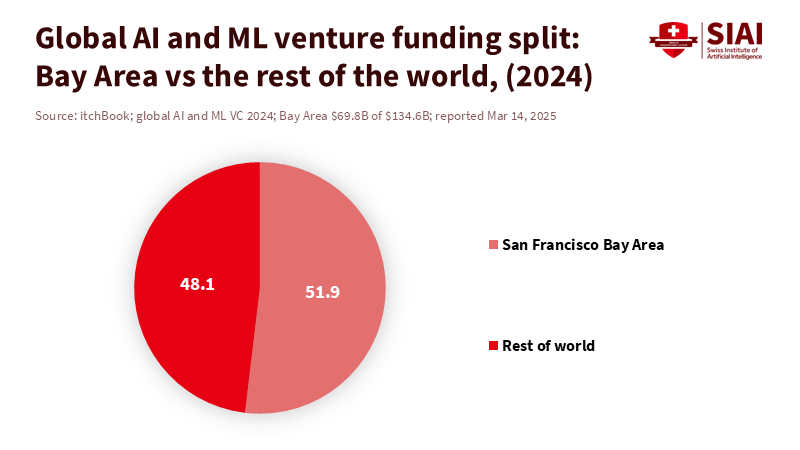
In 2024, over 50% of global venture capital for AI and machine-learning startups went to Bay Area companies. This figure shows a dependency: a small area now shapes tools for tutoring bots, writing helpers, learning analytics, and campus support. When rules in California change, the effects quickly spread through supply chains. These changes impact labs that train advanced models, startups that build on them, public schools that depend on vendor plans, and universities that design curricula around rapidly changing tools. The California AI safety law is both a safety measure and a competition decision, made in a place that still sets the global standard.
Senate Bill 53, the California AI safety law, signed on September 29, 2025, aims to reduce catastrophic risks posed by advanced foundation models through transparency, reporting, and protections for workers who raise concerns. The goal is serious, but the situation has changed. The U.S. now competes on speed, cost, and spread, as well as model quality. China is pushing open-source models that can be downloaded, fine-tuned, and used by many people at once. If California creates a complex process that mainly affects U.S. labs, the U.S. may pay for compliance while competitors profit. For education, this risk is real. Slower model cycles can mean slower safety improvements, fewer features, and higher prices for school tools.
What SB 53 does, in plain terms
SB 53, the Transparency in Frontier Artificial Intelligence Act, focuses on “large frontier developers”. A “frontier model” is defined by training compute: over 10^26 floating-point operations. A “large” developer must also have over $500 million in revenue in the prior year. These criteria target a small group of firms with many resources, not the typical edtech vendor. The compute threshold looks ahead. This matters because policy affects investment plans early on. The California AI safety law also prevents local AI rules that clash with the state framework. It centralizes expectations. SB 53 also authorizes CalCompute, a public computing resource, to broaden access and support safe innovation. Its development depends on later state action.
Figure 1: The Bay Area captured about 52% of global AI and machine-learning venture funding in 2024. When the hub tightens rules, the cost and speed effects spread down the stack, including education tools.
The law's main requirement is a published “frontier AI framework.” Firms must explain how they identify, test, and reduce catastrophic risk during development and use, and how they apply standards and best practices. It also establishes confidential reporting to the California Office of Emergency Services, as well as a way for employees and the public to report “critical safety incidents”. The law defines catastrophic risk using thresholds, such as incidents that could cause over 50 deaths or $1 billion in damage, not everyday errors. The California Attorney General handles enforcement, with penalties up to $1 million per violation. Reporting is confidential, to encourage disclosure without creating a misuse guide. This is good for safety, but it raises a tradeoff that education buyers will notice.
How the California AI safety law can tilt competitiveness
The first competitive issue is indirect. Most education startups will not train a 10²⁶ -FLOP model. They rent model access and build tools on top of it: tutoring, lesson planning, language support, grading help, and student services. If providers add review steps or slow releases to lower legal risk, products are delayed. The Stanford AI Index says that U.S. job postings needing generative-AI skills rose from 15,741 in 2023 to 66,635 in 2024. Also, large user bases quickly adopt defaults; Reuters says that OpenAI reached 400 million weekly active users in early 2025. Even minor slowdowns in release cycles can change which tools become standard in classrooms.
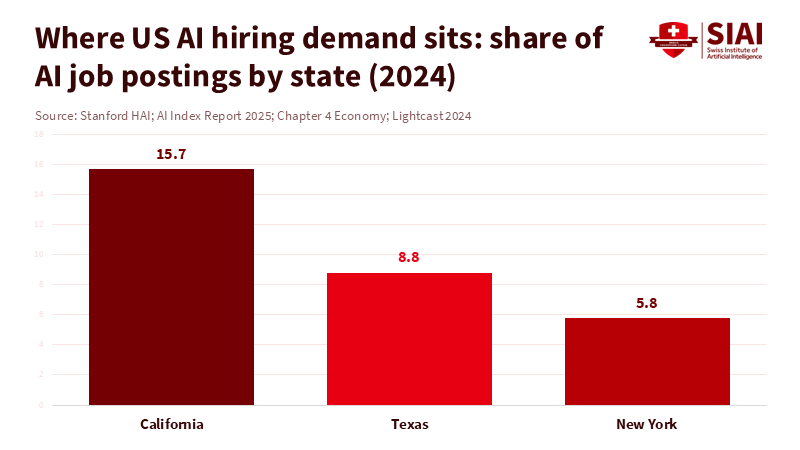
The second issue is geographic. California has the highest AI demand, accounting for 15.7% of U.S. AI job postings in 2024, ahead of Texas at 8.8% and New York at 5.8%. This does not prove that firms will leave. SB 53 targets large developers, and many startups will not be directly affected. However, ecosystems shift. The question is where the next training team is, where the next compliance staff is hired, and where the next capital is invested. If the California AI safety law introduces legal uncertainty into model development, and other states are more relaxed, the easiest path can shift. Over time, this can make “relocation” seem like a steady move.
Figure 2: California alone accounts for nearly twice Texas’s share of AI job postings. That concentration is why the California AI safety law can ripple through the national AI pipeline.
The third issue is the market structure that schools experience. Districts and universities rarely have the staff to check model safety. They depend on vendor promises and shared standards. A good law can improve the market by making safety claims verifiable. A bad one can do the reverse, reducing competition and choice, while everyday harms continue. Those harms include student data leaks, biased feedback that reflects race or disability, incorrect citations in assignments, and risks of manipulation. Critics say SB 53 concerns catastrophic risk, not daily failures. Yet, the same governance choices shape both. If major providers limit features or change terms for education buyers, districts will have fewer options as demand rises.
China’s open-source push changes the baseline
China’s open-source strategy changes what “disadvantage” means. Stanford HAI says that Chinese open-source language models have caught up and may have surpassed others in capability and adoption. The pattern is breadth. Many people are building efficient models for flexible use rather than relying on a single platform. These models travel well, enabling local fine-tuning, private use, and quick adaptation to specific areas, such as education tools that must be private. The ecosystem is not just “one model,” but a system of reuse in which weights and tools spread quickly across firms. A state law that mainly slows a few U.S. labs can still reshape the global field.
Market signals support this, affecting education. Reuters reports that DeepSeek became China’s top chatbot, with 22.2 million daily active users, and expanded its open-source reach by releasing code. Reuters also says that Chinese universities launched DeepSeek-based courses in early 2025 to build AI skills. Governance is changing to keep things moving. East Asia Forum says that China removed an AI law from its 2025 agenda, leaning more on pilots. In late December 2025, Reuters reported that rules targeted AI services that mimic human traits, demonstrating quick oversight. California uses a single compliance method, while China can adjust controls as adoption changes.
Make safety a strength, not a speed bump
The solution is not to drop the California AI safety law, but to make safety a competitive advantage. Start with transparency for buyers. Districts need disclosures about testing that can be checked. California should advance its “frontier AI framework” toward a template that aligns with risk guidance, such as the NIST AI Risk Management Framework. It should also create a safe space for education pilots that follow privacy rules, so providers are not punished for sharing proof with schools. The federal tone also matters. In January 2025, the White House issued an order to lower barriers to American AI leadership. If Washington signals speed and Sacramento signals difficulty, firms will exploit the split. A template and alignment with norms can lower overlap without lowering standards.
California should also treat computer access as part of safety. SB 53 establishes CalCompute to expand access and support innovation. But much of this depends on a report due by January 1, 2027, and funding. If the state wants to keep research local, speed is essential. Public cloud can help universities run checks and stress-test models without relying on vendors. It can also support sharing findings without exposing student data. This shared proof bridges “catastrophic risk” and the risks that harm learners.
The opening statistic is a warning, not a boast. When AI startup capital is in one region, that region’s rules become policy. California can lead on safety and speed, but only if the California AI safety law rewards practice and lowers uncertainty for users. Education shows this tradeoff. Schools will adopt what works, at a price they can afford. If U.S. providers slow, costs rise, and open-source options will spread. The task is to make SB 53 a system for trusted adoption: templates, tests, incident learning, and compute access. That is how a safety law becomes a strategy, not a handicap.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
California State Legislature. (2025). Senate Bill No. 53: Artificial intelligence models: large developers (Chapter 138, Transparency in Frontier Artificial Intelligence Act). Sacramento, CA. Hu, B., & Au, A. (2025, December 25). China resets the path to comprehensive AI governance. East Asia Forum. Meinhardt, C., Nong, S., Webster, G., Hashimoto, T., & Manning, C. D. (2025, December 16). Beyond DeepSeek: China’s diverse open-weight AI ecosystem and its policy implications. Stanford Institute for Human-Centered Artificial Intelligence. National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0) (NIST AI 100-1). U.S. Department of Commerce. Reuters. (2025a, September 29). California governor signs bill on AI safety. Reuters. (2025b, February 21). DeepSeek to share some AI model code, doubling down on open source. Reuters. (2025c, February 21). Chinese universities launch DeepSeek courses to capitalise on AI boom. Reuters. (2025d, December 27). China issues draft rules to regulate AI with human-like interaction. Reuters. (2025e, February 20). OpenAI’s weekly active users surpass 400 million. Stanford Institute for Human-Centered Artificial Intelligence. (2025). AI Index Report 2025: Work and employment (chapter). Stanford University. State of California, Office of Governor Gavin Newsom. (2025, September 29). Governor Newsom signs SB 53, advancing California’s world-leading artificial intelligence industry. Sacramento, CA. White House. (2025, January 23). Removing barriers to American leadership in artificial intelligence. Washington, DC.
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Security industrial policy now shapes what schools can access and teach
Education must build resilience without shutting down openness
Strategy will fail without skills pipelines and smart campus rules
The Central Asia green transition will follow the fastest, cheapest supply chains
The EU can lead on standards, skills, and grid readiness, even if China supplies hardware
Central Asia keeps control by demanding open data and local capacity in every deal
Stories outlast statistics, and feeds reward that
Viral politics runs on heroes, villains, and anger
Teach narrative literacy, and push for cleaner platform data
A study found that the impact of a statistic on belief decreased by 73% after just
Korea’s AI PhD Fast Track Won’t Fix the Talent Gap Unless It Fixes the PhD
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
Fast AI PhDs won’t fix hiring if training stays shallow
Firms need proof of real research skills, not faster diplomas
Rigor and outcomes must drive funding and standards
Available data indicate that Korea's artificial intelligence workforce is bigger than people think. The Bank of Korea estimates that about 57,000 AI specialists were employed in Korea in 2024. Yet, companies still say they struggle to find qualified people. This gap shows the real test for the AI PhD fast-track program. If more people graduate, but hiring remains hard, the issue extends beyond the number of graduates. It relates to the suitability, knowledge, and credibility of potential employees. AI work needs a solid education. Systems can fail if the info changes. When those in charge of hiring see an AI PhD fast-track, they want proof that a person can do cutting-edge work, not just a degree earned quickly. The thinking behind the fast-track policy is that shortening the time to get a degree will attract more students. It seems simple, and the number of spots can be easily counted. But AI expertise takes time to grow in labs through coding and learning from mistakes. A PhD involves education, skill development, learning to deal with unforeseen issues, and time spent in a research setting. If the policy views the PhD as just longer schooling, the AI PhD fast track risks valuing speed over good research. The result might look good on paper, but it does not meet companies' needs.
The AI PhD fast track focuses on time, but companies want quality
In November 2025, Korea’s Education Ministry announced a nationwide plan to foster AI talent. A key part allows students to finish bachelor’s, master’s, and doctoral studies in 5.5 years. The plan also aims to increase the number of AI-focused schools from 730 to 2,000 by 2028 and to increase the number of science and special schools offering specialized courses from 14 to 27. The Korea Herald reported that about 1.4 trillion won is being invested. These numbers show the urgency and highlight what’s easiest to measure: time, numbers, and funding. Yet, employers care more about skills, judgment, and good research habits.
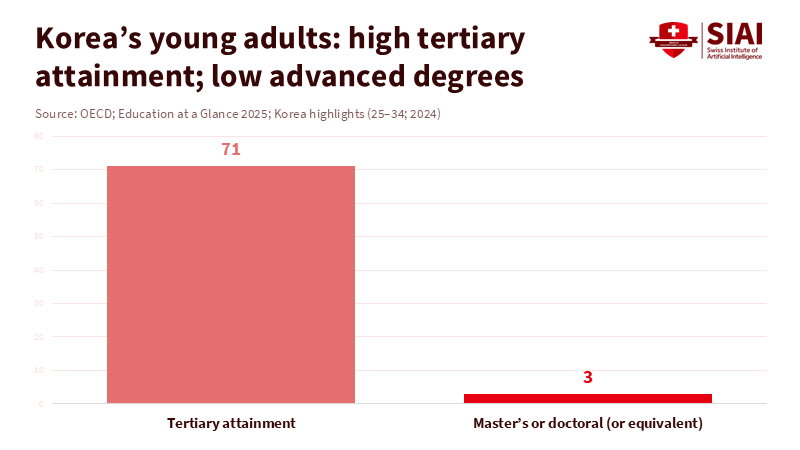
It is worth asking what the system seeks. Korea has strong educational results but relies on credentials. OECD data shows 71% of Koreans aged 25 to 34 have completed college, the highest rate among OECD countries. Only 3% of that group have a master’s or doctorate, well below the OECD average. This suggests degrees may be social symbols, while advanced study is just an addition. For the AI PhD fast-track program, that matters. It could raise the wrong question: "How fast can a student graduate?" Research should ask: "What did the student figure out, and how do we know it is correct?" If time is the primary measure, courses may cut the most challenging material, such as advanced math, statistics, and system iteration.
Figure 1: High degree completion does not automatically mean deep research training—this gap helps explain why speed-based PhD reforms can miss what employers screen for.
Public money also adds to what is at stake. Korea spends heavily on new ideas, allocating about 4.96% of its GDP to domestic R&D in 2023. With so much public support, inadequate training is more than a personal mistake; it is a loss for the country. Taxpayers pay for labs, grants, and programs to develop talent. If the AI PhD fast track leads to shallow research, companies will pay twice: first through taxes and then to fix failed systems, while graduates see their degrees mean less. Universities may also face reputational issues that are hard to fix. Speed can be helpful when it is earned through real competence and good guidance; otherwise, the program might just help people finish quickly rather than prepare them for meaningful work.
What the AI PhD fast track should provide for jobs
What companies want in AI is becoming clearer, not easier. The OECD says that in Korea, 56.5% of companies using AI have seen it replace parts of some jobs. Many also say AI has increased the types and level of skills needed for current jobs. For small to mid-size Korean businesses, the need for data examination skills is on the rise. The next need is computer skills. This tells universities designing the AI PhD fast-track that a quicker path only helps if graduates can handle complex data, create tests, and explain their decisions. This skill comes from repeatedly doing research, getting feedback, and creating tested and fixed systems. It does not come from taking courses alone.
The Bank of Korea’s research on the job market explains why more graduates do not necessarily lead to more hiring. They estimate that about 11,000 Korean AI experts worked outside Korea in 2024, about 16% of the AI workforce.
Their findings also show that AI workers' pay in Korea was only about 6% higher in 2024 than in the U.S. and other countries. When income is low, people tend to look for work elsewhere. It can also change how employers act at home. Companies raise the bar for hiring because it costs them a lot to employ someone who is not ready. They look for proof of ability, focusing on past work and solid modeling skills. In that environment, the AI PhD fast track will be tested by its results. If the degree does not point to someone who will do well on the job, it will lose value.
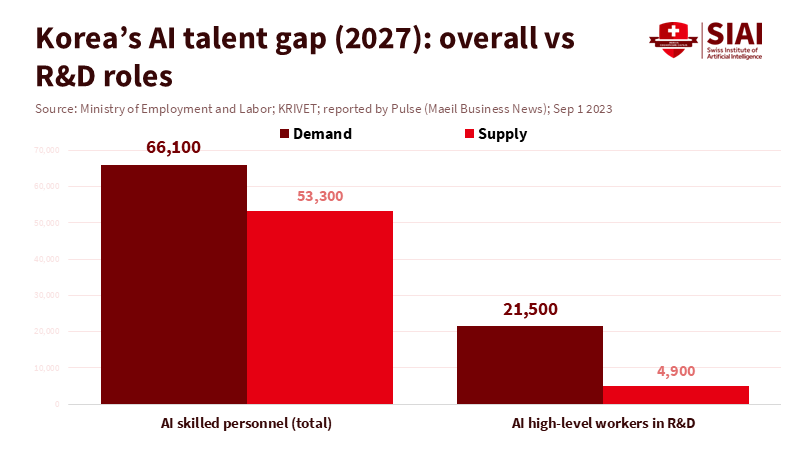
Estimates of job shortages show why fundamental skills matter. A 2023 forecast projected demand for AI staff to reach about 66,100 by 2027, while only about 53,300 are available, leaving a gap of roughly 12,800. SPRi stated that 81.9% of 2,354 AI firms in Korea had trouble finding enough workers. These numbers support investment but show the risk involved. Companies do not want just anyone with an AI title; they want people who can create and defend their work. One poorly skilled worker can slow a team and create hidden risks. So, the AI PhD fast track needs to raise the percentage of graduates who can contribute to research and new products from the start.
Figure 2: The headline shortage is serious, but the bigger problem is at the R&D level—exactly where a credible PhD signal should reduce risk for employers.
When speed turns into a meaningless degree
No one wants to create a worthless degree. The risk is that standards drop over time. Across the world, low-quality schools often have something in common: they promise a degree very quickly. The Council for Higher Education Accreditation warns that these schools might promise degrees in a very short period, making quick completion a main selling point. The Department of Education warns that these places may look real but fail basic quality checks, and encourages students and companies to verify claims.
Korea’s AI PhD fast track is not one of these degree mills. But local discussion already calls programs that award degrees without real training "degree mills." If 5.5 years is what it is known for and the rules are not consistent, the thinking can become flawed: students pay to save time, institutions sell degrees, and companies and taxpayers suffer when the degree does not indicate that someone is capable.
AI makes it harder to hide a poor education. A bad report might go unnoticed in some subjects, but in AI, it shows up quickly. Teams that do not comprehend testing find it hard to tell what is essential. Teams that do not understand statistics struggle with skewed results. Teams that do not understand modeling struggle to think about failures. That is why companies ask about portfolios and programs, not just grades. An AI PhD fast track can be sound, but it has to rely on proof of skill rather than time. If it takes less time and has no challenging requirements, it trains students to avoid risk, since difficult questions take longer and are more likely to be answered incorrectly. That is the reverse of how research training should be.
There is also a real cost to reputation. AI recruitment is global, and word spreads fast. Companies still judge degrees by what graduates can do, even if they never visit the school. Korea is already seeing skilled AI workers leave the country. With that said, a weak sign hurts everyone, even the best graduates. The market impacts everything, not just some departments. If the AI PhD fast track is seen as a waste of time, it can limit the chances for those it is meant to help. Therefore, consistency across institutions is essential. A few weak programs can ruin the signal for the good ones. It takes time to build a good reputation, but it can be lost quickly.
How to make the AI PhD fast track valuable for hiring
Instead of selling speed, the AI PhD fast-track should be about demonstrating skill with clear proof. Students who already have skills can move faster, but those who do should not be hurried. That requires a solid foundation in math, statistics, and modeling, which many AI research labs consider important. It also needs results that are hard to fake: tested experiments, well-documented programs, and a report that passes outside review. Schools can help by testing problem-solving skills instead of memorization. If a school cannot achieve these conditions, it should not promote itself as an AI PhD fast track.
Rules should match goals. OECD research on quality suggests that outside policies can encourage improvement inside higher education. Some might say the AI PhD fast track is only for great students so that quality will take care of itself. This will not occur when money and reputation boost productivity across departments. So, officials need rules that reward research, not just numbers. School leaders need to assign reasonable workloads that allow time for mentoring and feedback. Departments need external examiners who are not aligned with career interests. Precise results, like published work, matter too. These steps protect good students and stop companies from paying for credentials that are not credible.
The job market cannot be ignored. The Bank of Korea’s low pay rate means Korea is not valuing AI skills like other countries do. Some might argue that companies can teach what programs cannot, but fixing this is expensive. If great skill is not valued, it will be lost. Consequently, the AI PhD fast track needs a matching job plan. That could include stronger partnerships with companies, research standards, guidelines on ownership, and early job tracks that do not require talent to move abroad for good pay. Otherwise, Korea might train people quickly, pay for it publicly, and then see companies in other countries benefit. A quick degree is only one part of the plan; incentives and research also affect productivity.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank of Korea. (2025). Mismatches in Korea’s AI labor market (AI workforce estimate; overseas share; wage premium discussion). Council for Higher Education Accreditation. (n.d.-a). Degree mills: An old problem and a new threat. KBS World. (2025, November 10). Gov’t unveils AI education plan to nurture new talent. Korea Herald. (2025, November 10). S. Korea to foster AI talent across all stages of life. Korea.net. (2024, December 30). Domestic R&D spending as % of GDP ranked No. 2 in 2023. Lee, K. (2025a, November 12). AI시대, 고급 교육을 포기한 대학의 미래는 없다. 디 이코노미. Lee, K. (2025b, November 12). 한국 AI 연구 인력의 실상과 그 배경 (analysis of math/stat training and AI research labor markets). 디 이코노미. MK Pulse. (2023, September 1). S. Korea faces shortage of skilled workforce in key technology fields. OECD. (2025a). Artificial intelligence and the labour market in Korea. OECD. (2025b). Education at a glance 2025: Korea country note. OECD. (2025c). Ensuring quality in VET and higher education: Getting quality assurance right. SPRi (Software Policy & Research Institute). (2024). Media page entry citing results of the 2023 AI industry survey. The Korea Times. (2025, December 5). Korea sees brain drain of AI talent amid low wage premium: BOK (Yonhap). U.S. Department of Education. (2025, April 24). Diploma mills and accreditation. WIPO. (2025). Global Innovation Index 2025: Republic of Korea indicator notes.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
2022 proved the nonlinear Phillips curve under tight labor
Use two-speed budgets: inflation >4% and v/u >1 trigger
Teach regime-switching to keep small misses small
When Speed Becomes Contagion: How AI Turns Local Shocks into Systemic Risk
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI turns rumors into instant, system-wide stress
Shared models and platforms cause herding and correlated errors
Use timed frictions, model diversity, and critical-hub oversight
The most important number in finance right now is 42 billion. That's how much money one US bank saw disappear in a single day in March 2023. Another $100 billion was lined up to leave the next morning. This wasn't an old-school bank run with people lining up outside. It happened through phones, online feeds, and electronic transfers. This is how fast things can go wrong now. And it's super important to keep this in mind when we think about the risks AI creates for the financial system. AI speeds up the creation, sharing, and action on information. It can turn a rumor into a decision and a decision into a cash flow really fast. This speed is what turns normal little problems into system-wide panic. If we keep thinking of AI as just something individual companies use, rather than a connected system, we're going to get the risk wrong.
AI Risk in Finance: What Now Moves Together
The old way of thinking assumed that things slowed down between a bad story and its reaction. AI gets rid of that slowdown. It makes finding patterns, automating decisions, and coordinating actions faster because everyone's using the same information, models, and platforms. This means everything is really tightly linked together. Depositors and traders see the same stuff at the same time and use similar tools to react. Back in March 2023, that bank lost $42 billion in eight hours, and $100 billion was waiting to get out the next day. Regulators later realized that social media and online channels made the problem much worse. That speed isn't unusual anymore; it's just how things are with AI risk in finance when things go bad.
It's not just about speed; it's that everyone's doing the same thing. Lots of companies now use similar AI services, cloud services, data providers, and model designs. Regulators are warning that this can cause everyone to act the same way and make the same mistakes, especially if the models are hard to understand or poorly managed. If you add AI-powered news feeds and ad targeting, a random social media post can cause people to pull their money out of a bank, or a bad risk score can cause everyone to sell at once. The way modern finance is set up – with all these connections – turns acting alike into acting fast. That's why we need to manage AI risk in finance like a network issue, not just an issue with individual models.
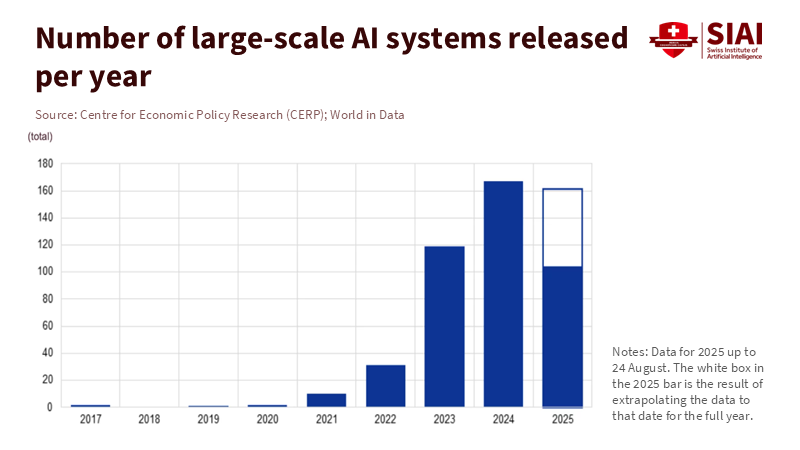
Figure 1: Model releases exploded after 2022, pushing common exposure and synchronous behavior across firms—an upstream driver of AI systemic risk.
Five Things That Cause AI Risk in Finance
First, AI-driven fake news can now actually hurt a company's bottom line. The bank runs in 2023 showed how social media and online banking accelerated the process. Banks with high Twitter activity lost more money when SVB failed, revealing their stress in real time. Payment data show that at least 22 US banks saw people withdraw a large amount of money that month. New tests show AI-generated false claims about a bank's safety, spread through cheap ads, can really make people want to move their money. Almost 60% of people surveyed said they'd think about moving their money after seeing something like that. Deepfakes make it even easier to trick companies. Earlier this year, a finance employee was tricked into sending about $25 million to scammers by a deepfake video call. The main point is: AI in finance means bad news doesn't just scare the markets; it moves money.
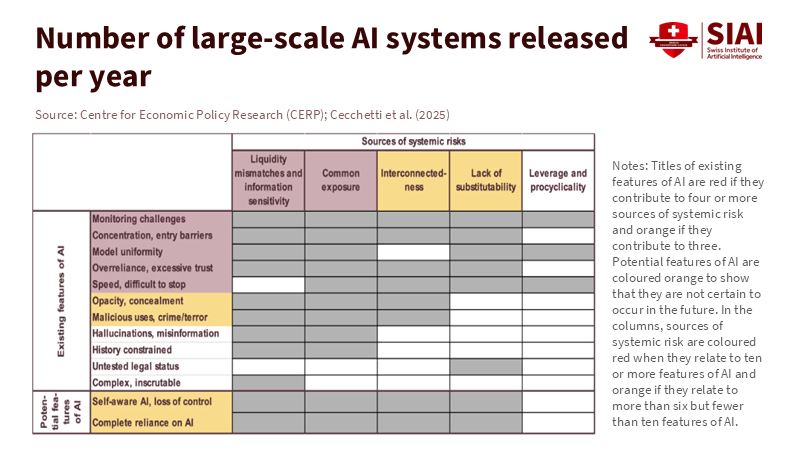
Figure 2: Speed, opacity, and model uniformity hit multiple risk channels at once (liquidity, common exposure, interconnectedness, substitutability, leverage), explaining why rumor-driven shocks scale so fast.
Second, if everyone uses the same models, they're more likely to make the same mistakes. The idea is simple: if everyone's connected and getting the same information, it can cause a domino effect. What's new is that everyone may be using the same kinds of models, data, and tech companies. Regulators are warning that AI can make everyone act the same way, making things more fragile, especially if the models are hard to understand and use data that is similar. As AI systems shape news and even internal memos, the same explanations pop up everywhere. Credit, risk, and trading teams then react in unison. This can cause the whole market to swing in one direction. When things change, money can disappear fast. This isn't theoretical. This is how AI risk in finance is most likely to show up – quietly at first and then exploding when things get stressful.
Third, if a few companies have a lot of control and everyone relies on their stuff, it creates single points of failure. AI runs on a small number of giant cloud and model platforms, often owned by the same companies. Authorities are starting to regulate these companies. The UK's rules for these companies went into effect this year. The EU is now directly monitoring essential tech providers and has designated central cloud and data firms as critical to the financial sector. This is because if a major vendor has a problem, it can spread to lots of institutions at once. If everyone's using the same AI tools, a simple failure or cyberattack can cause market-wide issues even if the banks themselves do everything right.
Fourth, if the data and models are weak, it can cause widespread errors. AI systems are only as good as the data and security they have. National standards groups are warning about hacking techniques that can secretly change results or steal information. Explainability remains limited for many advanced models. This leads to mistakes, especially when things change. Earlier this year, the UK warned that hacking risks might never be fully fixed in current AI models. This means the risk has to be managed. If several institutions use similar models and data and face the same hacking attempts, they'll make the same mistakes. AI risk then goes from being small to being huge – thousands of small, fast errors that all point in the same direction.
Fifth, speed and money are colliding. AI shrinks the time between getting a signal and settling a transaction. This is helpful when things are calm, but risky when things are stressful. What happened in March 2023 is now the example: one bank lost about a quarter of its deposits in a day. Also, deposit amounts and market values fluctuated throughout the day in response to what people were saying online. European authorities are learning the same thing: instant payments and mobile banking mean bank runs happen in hours, not days. In the markets, AI tools can cause everyone to sell at once, leading to low prices. The reason is simple: when everyone acts fast and in the same way, there isn't enough money to go around. This is the core of AI risk in finance.
What to Do About AI Risk in Finance
The first thing we need is a rule for handling transactions when rumors are spreading. Faster isn't always safer. The goal isn't to stop speed but to control it. A memo suggested common-sense rules: slow down big withdrawals when regulators are about to make an announcement, pause automated selling programs when there are information circuit-breaker alerts, and require banks, platforms, and authorities to track down rumors in real time. The same idea should apply to both regular customers and businesses. If AI risk grows when everyone uses the same fast tools at once, the solution is to slow things down for a bit so authorities have time to determine what's true and keep things stable.
The second thing is to strengthen the systems that make AI common. Watch critical third-party companies and ensure they're resilient, secure, and able to recover from problems. Run exercises that involve the entire sector, assuming that models have been compromised or that cloud services are down. Map out the shared connections, not just who uses which vendor. Require institutions to have multiple models for critical functions, with distinct data and decision-making processes, to reduce the risk of everyone doing the same thing. Update stress tests to include AI-driven fake-news scenarios with short deadlines and deposit losses, based on events in 2023. Regulators should also require official statements to be verified with digital signatures so that platforms and media can stop fake news in real time.
What Teachers and Leaders Should Do Next
Courses need to keep up with how AI changes risk in finance. Teach the new math of bank runs. Show how things like uninsured deposits, social media, and instant payments combine to cause money to flow out of banks. Assign readings that cover finance, cybersecurity, and communications. Students should look at the 2023 events to see the speed and how stress is spread. They should simulate rumor-driven panics and then see how slowing down transactions and sending explicit messages from regulators changes the outcome. The goal isn't to scare people; it's to prepare them.
Within institutions, leaders should develop joint plans across teams such as treasury, risk, communications, legal, and security. These teams need to quickly spot fake media, send verified statements across channels, and work with platforms to remove harmful phony news. They should also check their own AI systems for shared weaknesses, such as identical models, data vendors, or setups. Test AI agents against hacking. Maintain break-glass manual options for essential flows. This doesn't slow down innovation. It keeps it going by making sure that one clever hack or one lie can't bring the whole system down.
The $42 billion day isn't just a number to remember. It's a constraint. We have a financial system where information moves at model speed, and money follows right behind. That's not going to change. What can change is how we handle the stress. AI risk in finance is a network problem: standard tools, data, vendors, and stories. The solutions need to be network-aware: slowing money flows when rumors spread, supervising key infrastructure, using different models for important decisions, and sending fast, verified messages to fight fake news. Teachers should train for these situations. Policymakers should create rules and test them. Bank leaders should practice them. We don't have to accept that every rumor turns into a bank run. If we build safeguards that work at the speed of AI, then the next $42 billion day can be something we've moved past.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Banque de France. (2024). Digitalisation—A potential factor in accelerating bank runs? Bloc-notes Éco. Bank of England; Prudential Regulation Authority; Financial Conduct Authority. (2024). Operational resilience: Critical third parties to the UK financial sector (PS16/24). Bank for International Settlements. (2024). Annual Economic Report 2024, Chapter III: Artificial intelligence and the economy: Implications for central banks. Bank for International Settlements—Financial Stability Institute. (2023). Managing cloud risk (FSI Insights No. 53). California Department of Financial Protection and Innovation. (2023). Order taking possession of property and business of Silicon Valley Bank. Cipriani, M., La Spada, G., Kovner, A., & Plesset, A. (2024). Tracing bank runs in real time (Federal Reserve Bank of New York Staff Report No. 1104). Cookson, J. A., Fox, C., Gil-Bazo, J., Imbet, J.-F., & Schiller, C. (2023). Social media as a bank run catalyst (working paper). European Systemic Risk Board—Advisory Scientific Committee. (2025). AI and systemic risk. Financial Stability Board. (2024). The financial stability implications of artificial intelligence. Fenimore Harper & Say No to Disinfo. (2025). AI-generated content and bank-run risk: Evidence from UK consumer tests. Federal Reserve Board Office of Inspector General. (2023). Material loss review: Silicon Valley Bank. National Institute of Standards and Technology. (2023). AI Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology. (2024). Generative AI: Risk considerations (NIST AI 600-1). National Cyber Security Centre (UK). (2025). Prompt injection is not SQL injection (it may be worse). Reuters. (2024). Yellen warns of significant risks from AI in finance. Reuters. (2025). EU designates major tech providers as critical third parties under DORA. Swiss Institute of Artificial Intelligence. (2025). Digital bank runs and loss-absorbing capacity: Why mid-sized banks need bigger buffers. VoxEU/CEPR Press. (2025). AI and systemic risk. World Economic Forum. (2025). Cybercrime lessons from a $25 million deepfake attack.
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.