Getting Rid of Coordination Headaches: How LLMs are Changing How We Work Together
Getting Rid of Coordination Headaches: How LLMs are Changing How We Work Together

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
LLMs slash coordination costs in teams Design- and model-minded co-create, instantly Protect diversity with drafts, provenance, human review

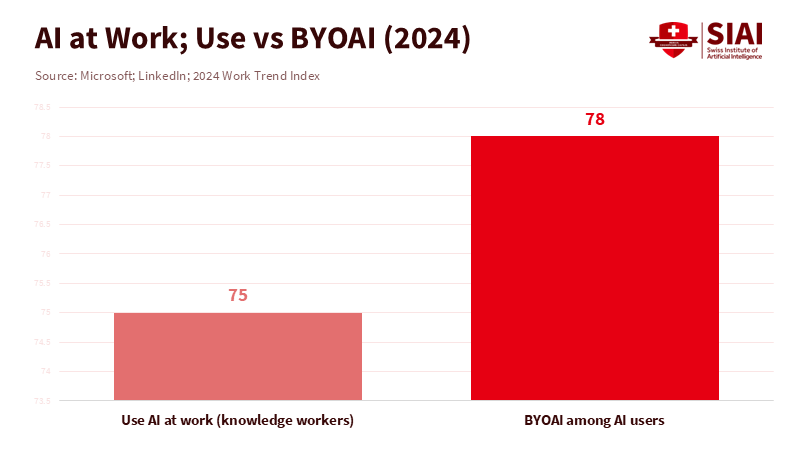
Every second, a new developer is signing up for GitHub. Back in 2025, over 36 million folks joined, and almost 80% of the newbies gave Copilot a shot during their first week. This isn't just a fad; it's a real shift in how we team up. Plus, about 75% of people who work with info say they're now using AI on the job. When you look at these facts together, it's easy to see that teaming up with LLMs has made coordinating things cheaper than creating them from scratch. Things that used to take hours of back-and-forth email—like renaming a variable or ensuring a style guide is followed—now take minutes. The amount of work in one go has gotten smaller. The time it takes to turn an idea into something a team can use has shrunk. This isn't just about being faster. It's about who gets to pitch in, how their ideas spread, and how we keep different ways of thinking alive so teamwork stays creative.
How LLMs are Changing What One Person Can Do
We used to see teaming up as a scheduling mess. People had to find time, combine versions, and argue about style in comment sections. LLMs turn those problems into perks. Now, a teammate can share a function, have the AI write test examples, and start a review—all at once. Another teammate can ask for a simple explanation of the code, then have the AI make a simple demo. The platform itself is like another teammate: it writes basic code, suggests changes, speeds up reviews, and keeps naming consistent. You end up with a different way of working. We hand in more than hand off, with many small changes happening at once without needing a ton of coordination. In schools, this means students can go from idea to a simple version in a day, then clean it up before class. In a writing class, a document can evolve through rewrites and merging ideas, with the AI maintaining a consistent style.
This change isn't just about coding. It's happening with presentations, documents, and data, too. A teaching assistant can write summaries, draft notes for speakers, and make sure citations are the same across a shared plan. In a lab, AI can make sure notations are consistent across a paper, turn a method section into a checklist, and translate an abstract for someone in another country. Translations are now so good that AIs can compete with experts, mostly for everyday text. The result is easy: you can focus on what matters, not just the small stuff. Teachers can grade for understanding, not grammar. And because AI makes cleanup cheap, teams can try things more often, which helps people learn.
Two Brains, One Place: Design and Code Working Together
A good team needs two kinds of thinkers. The design-minded ones shape the story, the interface, and how people will use the project. The code-minded ones build the structure—the functions—that make the system strong. LLMs let both types work without getting in each other's way. The design-minded can see the AI as a quick editor: translating a draft into simple English, shrinking a huge review, or testing an argument. They can ask for three styles of explanation—story, outline, and step-by-step—and use whichever is best. Because changes happen instantly, they can change the tone across the whole file in one go. This keeps the team's work clean while preserving individual voices.
The code-minded get a different advantage. They can rename variables, move settings into a config file, and keep the code consistent in a single step. When people want different notation, the AI can make a version in the style they prefer—like Greek—without messing things up. In data, the AI can turn a plan into code, write test code, and explain each step. These are big wins. They save hours of boring coordination and lower the chance of problems. Now, the design-minded and code-minded can meet in the middle. One group makes things clear; the other makes things work right. The AI makes sure its changes fit together so the system runs and reads as one.
Keeping Things Diverse
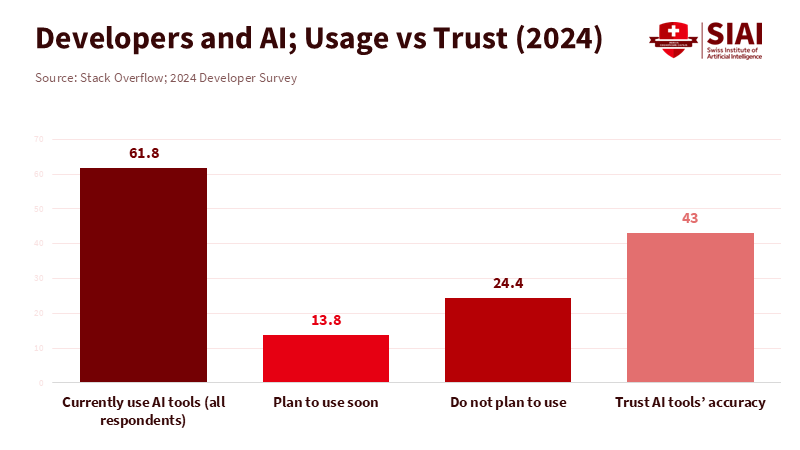
Here's the thing. Quick agreement can turn into everyone thinking the same. When teams use the same AI, the style can get too similar. Word choices get closer. Examples repeat. Even code starts to look the same. Studies show how AI makes things look average. Surveys show people use these tools a lot but don't always trust them, especially for tough stuff. That's good. LLMs are great for first drafts, but they can erase other perspectives if we let them. In schools, essays might sound the same. In labs, the same code might shape every experiment. The problem isn't that students stop thinking. It's that they stop thinking differently.
To fight this, we need to make sure there's room for different ideas. First, ask for two or three drafts before deciding. Make sure one draft uses sources the class hasn't already used. For code, have a wild branch where weird code styles are okay and only get merged back later. Second, keep track of where changes come from. When the AI suggests something, show that it's from the AI and link to the request. This makes reviews easier and teaches students to think for themselves. Third, use different AIs. A lab that switches between systems reduces the likelihood that everyone will sound the same. This isn't about making things hard; it's about keeping creative ideas alive while still being fast.
How to Do This on Campus and on Teams
The goal is simple: be fast without making everyone think alike. For teachers, set clear rules. Allow AI for editing, rewriting, and explaining, but require students to state when they use it. Grade the thinking, not just the writing, and have students defend their work in person. This reduces reliance on AI too much. Give templates that turn the AI into a tutor, not a ghostwriter: explain-then-rewrite for essays; comment-then-refactor for code; compare-two-ways for methods. Teachers can add tests to projects so that AI suggestions must meet standards. In group work, make sure each person has one unique idea that the AI only improves later.
Schools can make things better, too. Offer licenses for approved tools so students don't use accounts with bad privacy settings. Set up a system for course materials so AI pulls from the school's info, not random web pages. Make an AI syllabus that says what's allowed, how to use AI, and what happens if you misuse it. For research groups, ensure results are easily repeatable: use containers, write READMEs, and run style and security checks. This doesn't have to cost a lot. It's mostly about design—making the right thing easy.
Leaders can do the same. See the AI as a teammate that needs review. Track how often AI-suggested code is used; track errors on AI-made summaries; track how long it takes to merge AI changes. Share these numbers with teams so they use AI based on facts, not hype. When working with people in other countries, use AI to level the playing field: translate comments, summarize long discussions, and maintain consistent terminology. But make sure people make the final calls on security, fairness, and legal stuff. The idea isn't to slow down; it's to make speed match good judgment so AI helps with quality, not just quantity.
The good thing about this is that teaming up won't be a pain. When people can join a platform every second and use AI from day one, it's easier for everyone to contribute. When most people use AI at work, the line between solo and group work blurs. We should use this, but carefully. LLMs should make us more diverse, not less. That means multiple drafts, clear sources, different tools, and reviews by real people. If we set these rules now, we can keep the speed and still protect the good stuff: clarity, accuracy, and the freedom to be different. The next ten years will be better for teams that try many things fast—and know how to combine them.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Brookings Institution. “AI is Changing the Physics of Collective Intelligence—How Do We Respond?” (2025).
Carnegie Mellon University (Tepper School). “New Paper Articulates How Large Language Models Are Changing Collective Intelligence Forever.” (2024).
Computerworld. “Dropbox to offer its genAI service Dash for download.” (2025).
GitHub. “Octoverse 2025: A new developer joins GitHub every second; AI adoption and productivity signals.” (2025).
Max Planck Institute for Human Development. “Opportunities and Risks of LLMs for Collective Intelligence.” (2024).
Microsoft & LinkedIn. 2024 Work Trend Index Annual Report: AI at Work Is Here. Now Comes the Hard Part. (2024).
Stack Overflow. 2024 Developer Survey—AI Section. (2024).
WMT (Conference on Machine Translation). “Findings of the WMT24 General Machine Translation Task.” (2024).
Z. Sourati et al. “The Homogenizing Effect of Large Language Models on Cognitive Diversity.” (2025).
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.