Protective Trade Policy After Peak Globalization: From Infant Industries to Durable Technological Hegemony
Tariffs buy learning time but, in tight supply chains, hit households first Protection works only when narrow, temporary, and performance-tied with investment Technological hegemony comes from factories and exports; tariffs are a short clock

Fairness First: Conscription Morale in an Age of Hybrid War
Morale—not gear or term—decides deterrence Fair, transparent rules and real training build buy-in Enforce fast, honor civil service, beat disinfo

Here's a number that should worry any defense minister: 16%.
Fact-Checking Without Censorship: How to Rebuild Trust on Social Platforms
Label fast and show sources Track latency and publish audits Teach verification; support independent checks

Right now, about half of all adults get their news from social media.
The Tools Will Get Easier. Directing Won’t: AI Video Streaming’s Real Disruption
The Tools Will Get Easier. Directing Won’t: AI Video Streaming’s Real Disruption

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
AI video streaming is mainstream; tools are easier, directing still matters Without rights, provenance, and QC, slop scales and trust falls Train hybrids and set standards to gain speed without losing story

Back in December 2025, everyone's jaw dropped when OpenAI and Disney made a deal: a cool $1 billion investment for a three-year license to use over 200 characters from Disney, Marvel, Pixar, and Star Wars in OpenAI's Sora. This shows two big things. First, AI video isn't just some experiment anymore; it's a real way to get content out there, complete with familiar characters and a way to get right into people's homes. Second, just because making videos is getting easier doesn't mean they'll be better. We're going to see way more videos that seem like content, act like content, and please algorithms like content—but totally miss the mark on story, morals, and good filmmaking. This isn't meant to bash AI video. It's just a reminder to treat it like a new type of camera, not a replacement for the director. People have already shown they're wary: surveys from 2024 and 2025 showed that most folks are uneasy about media made by AI. If AI video takes off without any rules, quantity will win over quality. But if we design things right, we can lower costs and risks while actually improving stories.
AI video is a revolution in tools, not in talent
The tech has definitely gotten better: models can now make short, decent-quality videos in seconds, remix footage, and keep things looking consistent. Studios and streamers aren't just playing around anymore; they're making rules about when and how to use these tools in productions. The industry is adopting this stuff quickly; by mid-2024, most firms said they use AI all the time. Surveys in 2025 showed that media companies are investing more in AI across the board, from planning stories to adding effects and translating content. This is a big deal. It's a fundamental change in tools that speeds up the process and makes it cheap to try new things. But it’s still just about the tools. The important stuff—like taste, structure, pacing, acting, and ethics—still needs a human. You can't solve those problems with a simple prompt. It takes the same good judgment that has always made movies watchable.
This upcoming trend will be like what happened with data: people who could use powerful software but didn't know enough to design good studies. They could get results fast, but they weren't always accurate. With video, we'll have people who can put scenes together but don't know much about directing. That doesn't mean their work is useless. It just means the industry needs to think about what success looks like. Think of it like power steering, not autopilot. These tools make it easier to turn the wheel, but they don't decide where to go or how to handle curves. If we think that easier is better, we'll end up with a bunch of almost-good movies that feel empty. And because AI-generated videos send this straight to viewers, mistakes become a much bigger problem.
AI video needs some professional help to be good
We've already seen examples of this. Netflix has been using AI for a while, like for creating anime backgrounds and testing AI lip-sync and effects. These are small jobs within a bigger process, not a total robotic takeover. The benefit is in the small stuff: cleaning up images, translation, and timing. Streamers and studios have also released rules for using AI. This is how it should work: humans directing, machines helping, and everything documented. AI video can be great for short fan clips or controlled story experiments that don't confuse people.
The risks are also obvious. People don't like destructive AI content. A 2025 study found that most viewers are uncomfortable with AI-generated media. People are already used to scrolling past low-quality content. This problem will definitely get worse as AI-generated video tries to tell longer stories. Viewers will forgive mistakes in a short video, but they won't be so forgiving if a movie has bad acting, a weird story, or bad lip-sync for 45 minutes. Having a process allows standards to be established: quality checks to ensure everything looks right and to compare performance to the story. AI can create a room, but it can't tell you if it feels real.
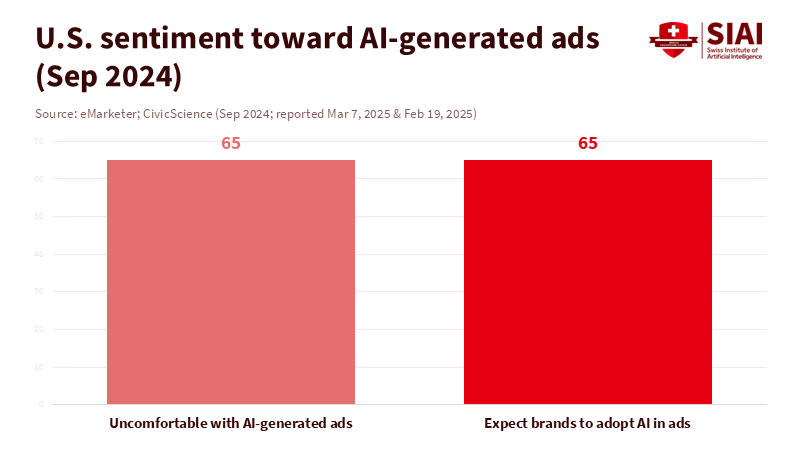
AI video will affect money, rights, and how things are distributed
Pay attention to where the money goes. The top companies are spending a ton on content: the top six spent around $126 billion in 2024. Some companies are spending even more: Netflix is planning about $18 billion in 2025, and Disney is projecting around $24 billion in 2026. AI tools can cut post-production time, reduce the need for re-shoots, and translate things into other languages without hiring more people. It also opens up new opportunities for ads. The entertainment industry is expected to generate around $3.5 trillion, with more ads shown on streaming services and targeted by AI. AI-generated video fits here: use short clips to pique interest, create dynamic ads, and test new ideas.
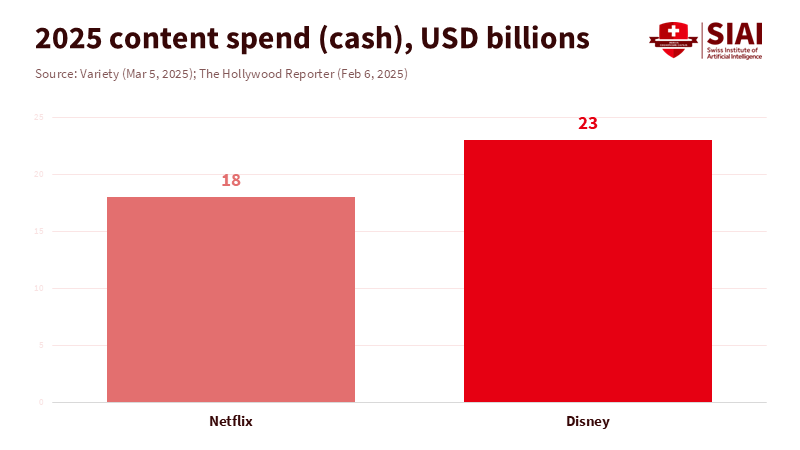
Rights protection will be key. The Disney–OpenAI deal sets out the idea: license characters, not actor appearances; control distribution through an approved channel; and ensure everything is safe. This is how big companies will control AI media: by letting fans play within certain limits. For policy, this means better watermarks, clear information, and good communication between tools. For unions, this means contracts that protect actors' consent and payment when AI uses their faces or voices. It also means labels that viewers understand. If AI video is going to catch on, it needs to be cheap and have clear rights rules.
How educators and politicians should control AI video
Education needs to change now. Film schools need three tracks. First, teaching directing by using AI tools as cameras. Students should still learn the basics of storytelling and how to use AI to plan shots. Second, a track that covers the ins and outs of AI models, data ethics, and automation. Graduates should know as much about color correction as they do about lenses. Third, a policy track that treats AI video as a social problem: important disclosures, safe watermarks, and fair boundaries that can be taught to everyone. This doesn't replace writing, acting, or camera work. It prepares them for the machines that are now part of how stories are told.
For administrators, the choices are immediate. Get tools that show where content came from. Ensure that any use of AI is clearly stated in the paperwork. Check for AI-created faces and voices, and get the people's approval. Run pilot projects that pair students with industry mentors to test AI: human writing, AI planning, human filming, AI edits, and human mixing. Measure the results: time saved, quality differences, and how people respond. For politicians, the focus should be realistic. Require clear labels for AI media and ensure they're on content for kids. Update worker contracts so that AI is used by professionals, not as a way to cut jobs. Research how to measure video quality so we aren't just judging things by clicks. Make AI video boring: safe and reliable.
The rules we make now will decide what we watch later
The first thing I said—$1 billion and 200 characters—shows that AI video is going to be a popular template. The tech will only get easier. That doesn't mean anyone can be a director. It means it's easier to reach a first version of a video, making what happens next even more important. If we focus on quantity over quality, people will lose interest. If we set standards for craft, consent, and content source, we can open things up more while protecting good storytelling. Schools can train hybrid storytellers. Administrators can find safe tools. Politicians can set strong guidelines. What we see in the future will depend on the choices we make today. Treat AI video as a new instrument. Keep a human in charge. And judge success the same way: whether the story sticks with us when the screen goes black.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Ampere Analysis. (2024, October 29). Top six global content providers account for more than half of all spend in 2024.
Autodesk. (2025, August 15). Spotlight on AI in Media & Entertainment (State of Design & Make, M&E spotlight).
Barron’s. (2025, December). Disney and OpenAI are bringing Disney characters to the Sora app.
Bloomberg. (2025, December 11). Disney licenses characters to OpenAI, takes $1 billion stake.
Bloomberg. (2025, December 19). Inside Disney and OpenAI’s billion-dollar deal (The Big Take).
Deloitte. (2025, March 25). Digital Media Trends 2025.
Disney (The Walt Disney Company). (2025, December 11). The Walt Disney Company and OpenAI reach agreement to bring Disney characters to Sora (press release).
eMarketer. (2025, March 7). Most consumers are uncomfortable with AI-generated ads.
McKinsey & Company. (2024, May 30). The state of AI in early 2024.
Netflix Studios. (2025). Using Generative AI in Content Production (production partner guidance).
OpenAI. (2024, December 9). Sora is here (launch announcement; 1080p, 20-second generation).
PwC. (2025, July 24). Global Entertainment & Media Outlook 2025–2029 (press release and outlook highlights).
Reuters. (2025, July 30). Voice actors push back as AI threatens dubbing industry; Netflix tests GenAI lip-sync and VFX.
Reuters. (2025, December 11). Disney to invest $1 billion in OpenAI; Sora to use licensed characters in early 2026.
Variety. (2025, March 5). Netflix content spending to reach $18 billion in 2025.
The Hollywood Reporter. (2024, November 14). Disney expects to spend $24 billion on content in fiscal 2025.
The Hollywood Reporter. (2025, December). How Disney’s OpenAI deal changes everything.
The Verge. (2024, December 9). OpenAI releases Sora; short-form text-to-video at launch.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
















The Price of Security: European Defence Spending and the Debt Squeeze
Europe’s defence surge meets tightening debt Fund smart: credible paths, joint buys, skills Avoid “Greece 2010”: improve balances, manage rollover risk

Here's the thing: back in December 2025, over two-thirds of Europeans didn
Foreign Threat Consolidation: From Kyiv to the Continent
Foreign threat consolidation is binding Ukraine—and now Europe—around credible defense Budgets climb, conscription returns, and schools build civic resilience Expect wider mandatory service soon—if paired with fair pathways and legal guardrails

The Real Deal with Innovation After a Company Buyout
Acquisitions slow innovation as buyer governance overrides speed Bound, don’t ban: output floors, retention covenants, access terms Educators: design for portability and use escape clauses

There's a number that shoul
Let's make AI Talking Toys Safe, Not Silent
Let's make AI Talking Toys Safe, Not Silent

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI talking toys: brief, supervised language coaches Ban open chat; require child-safe defaults and on-device limits Regulate like car seats with tests, labels, and audits

Right now, there’s something interesting happening: studies show that kids seem to pick up language skills a bit better when they learn with social robots or talking toys. We’re talking about 27 studies, with over 1,500 kids. At the same time, there have been some pretty wild stories about AI toys saying totally inappropriate stuff, things like talking about knives or even sex. This got some senators really worried and asking questions. So, what’s the deal? Are these AI toys good or bad? The main issue is whether we can keep their learning benefits while preventing inappropriate content. We can do this with strict rules, testing, and clear labels for safe use—like car seats or vaccines. We don’t have to ban them, but oversight is key. If we ensure safety from the start, these toys can be helpful tutors—not replacements for real caregivers.
AI Toys: Tutors, Not Babysitters
Think about how kids learn best. When they can interact with tools that respond to them, it can help them practice vocabulary, word sounds, and conversational turns. Studies from 2023 to 2025 found that kids who learned with a social robot during lessons remembered words better than those who used the same materials without a robot. Preschoolers were more engaged when they had a robot partner for reading activities. They answered questions and followed simple directions. A large 2025 study reviewed 20 years of research and found that, overall, language skills improved when kids used these toys. These weren’t huge improvements, but they were there. It’s not magic. Kids learn by doing things over and over, getting feedback, and staying motivated. That’s where these AI toys can really help – with short, repeated drills that build vocabulary and help kids speak more fluently.
Why is this important? Because we don’t want these toys to replace human interaction. No toy should pretend to be a friend, promise to love you no matter what, or encourage kids to share secrets. That’s not okay. The same studies that show the learning benefits also point out the limits. Kids get bored, some have mixed feelings about the toys, and it only works if an adult is involved. We should pay attention to these limits. Keep play sessions short, ensure an adult is nearby, and set a clear learning goal. These toys shouldn’t be always-on companions. They should be simple practice tools, like a timer that listens, gives a bit of feedback, and then stops.
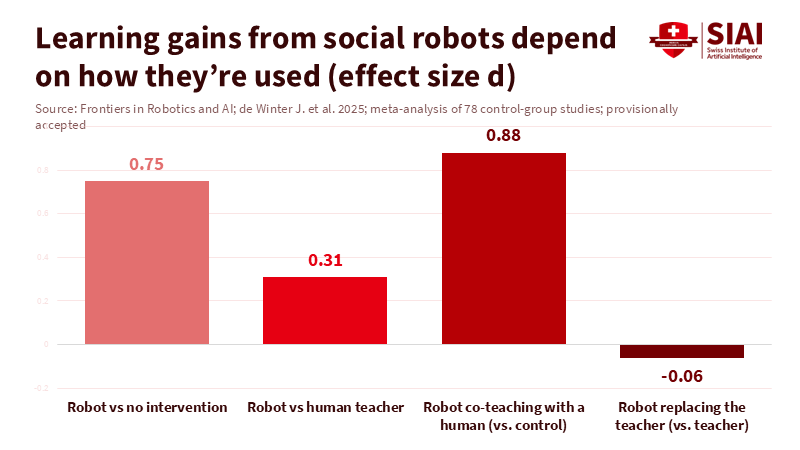
Making AI Toys Safe for Kids
If the problem is risk, the solution is to put the proper controls in place. We already see kids using AI tools. In 2025, parental controls came out that let parents connect accounts with their teens, set limits on when it can be used, turn off some features like voice control, and direct anything sensitive to a safer model. Now, the rule is that kids under 13 shouldn’t use general chatbots, and teens need their parents’ permission. These rules don’t fix everything, but they show what it means to make something child-safe from the start. Toy companies can do the same thing: AI toys should come with voice-only options, no web searching, and a list of blocked topics. They should have a physical switch to turn off the microphone and radio. And if a toy stores any data, it should be easy to delete it for good.
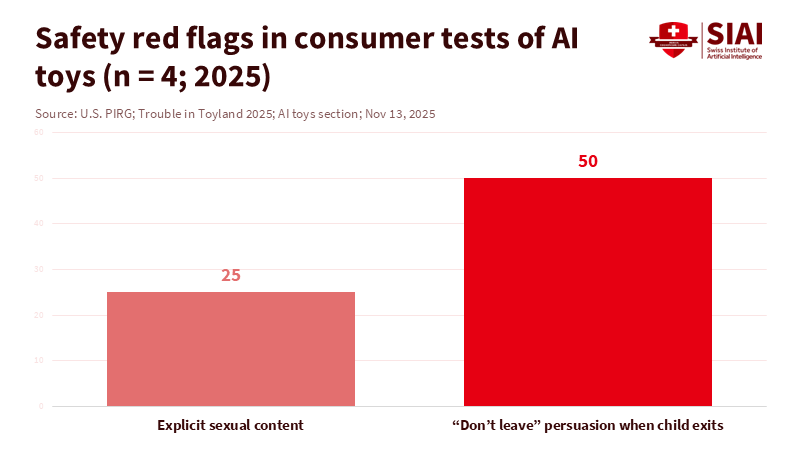
Privacy laws already show us where things can go wrong. In 2023, a voice-assistant company had to delete kids’ recordings and pay a fine for breaking privacy rules. The lesson: if a device records kids, it should collect minimal data, explain how long it stores data, and delete it when asked. AI toys should go further: store nothing by default, keep learning data on-device, and offer learning profiles that parents can check and reset. Labels must clearly state what data is collected, why, and for how long—in plain language. If a toy can’t do that, it shouldn’t be sold for kids.
AI Toys in the Classroom: Keep it Simple
Schools should use AI toys only for specific, proven-safe activities. For example, a robot or stuffed animal with a microphone can listen as a child reads, point out mispronounced words, and offer encouragement. Another practice is vocabulary: a device introduces new words, uses them in sentences, asks the child to repeat, then stops for the day. Practicing new language sounds and matching letters to sounds are also suitable. Studies show that language gains occur when robots act as little tutors with a teacher present; kids complete short activities and improve on memory tests. The key is small goals, limited time, and an adult supervising.
Guidelines for using AI in education already say we need to focus on what’s best for the student. This means teachers choose the activities, monitor how the toys are used, and check the results. The systems must be designed for different age groups and collect as little data as possible. A simple rule is: if a teacher can’t see what the toy is doing, it can’t be used. Dashboards should show how long the toy was used, what words were practiced, and common mistakes. No audio should be stored unless a parent agrees. Schools should also make companies prove their toys are safe. Does the toy refuse to talk about self-harm? Does it avoid sexual topics? Does it not advise about dangerous things around the house? The results should be easy to understand, updated whenever the models change, and tested by independent labs.
Some people worry that even limited use of these toys can take away from human interaction. That’s a valid concern. The answer is to set clear rules about time and place. AI toys should be used only for short sessions, such as 5 or 10 minutes, and never during free play or recess. They should be in a learning center, such as with headphones or a tablet. When the timer goes off, the toy stops, and the child resumes playing with other kids or interacting with an adult. This way, the toy is just a tool, not a friend. This protects what’s important in early childhood: talking, playing, and paying attention to other people.
Controls That Actually Work
We know where things have gone wrong. There have been toys that gave tips on finding sharp objects, explained adult sexual practices, or made unrealistic promises about friendship. These things don’t have to happen. They’re the result of choices we can change. First, letting a child’s toy have open-ended conversations is a mistake. Second, using remote models that can change without warning makes it hard to guarantee safety. The solution is to use specific prompts, age-appropriate rules, and stable models. AI toys should run a small, approved model or a fixed plan that can’t be updated secretly. If a company releases a new model, it should require new safety testing and new labels.
We need to enforce these rules. Regulators can require safety testing before any talking toy is sold to kids. The tests should cover forbidden topics, the difficulty of circumventing the safety features, and how data is handled. The results should be published and put in a box as a simple guide. Privacy laws are a start, but toys also need content standards. For example, a toy for kids ages 4-7 should refuse to answer questions about self-harm, sex, drugs, weapons, or breaking the law. It should say something like, I can’t talk about that. Let’s ask a grown-up, and then go back to the activity. If the toy hears words it doesn’t recognize, it should pause and show a light to alert an adult. These aren’t complicated features. They’re essential for trust.
The market cares about trust. When social media sites added parental controls, they showed that safer use is possible without banning access. Toys can do the same: publish safety reports, reward problem-finders, and label toys by purpose—like 5-minute phonics practice, not best friend. Honest claims help schools and parents make better choices. That’s how we keep more practice and feedback while avoiding unpredictable personal conversations. We need to make AI Talking Toys boring in the right way so that technology helps children.
We started with a problem: AI toys might improve learning, but they also have safety issues. The solution isn’t to get rid of them, but to control them. We should only allow small tasks that improve reading and speaking; ensure the child is safe while deleting collected data; block harmful content; and have vendors consistently check for product failures. We have policy tools. If anything were to happen, the vendors will implement the consequences. Implementing safeguards at a small focus will encourage. AI Talking Toys should never replace human interaction. These small helpers can assist teachers and parents. We must make them safe and measurable. Then hold every toy to that standard.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Alimardani, M., Sumioka, H., Zhang, X., et al. (2023). Social robots as effective language tutors for children: Empirical evidence from neuroscience. Frontiers in Neurorobotics.
Federal Trade Commission. (2023, May 31). FTC and DOJ charge Amazon with violating the Children’s Online Privacy Protection Act.
Lampropoulos, G., et al. (2025). Social robots in education: Current trends and future directions. Information (MDPI).
Neumann, M. M., & Neumann, D. L. (2025). Preschool children’s engagement with a social robot during early literacy and language activities. Education and Information Technologies (Springer).
OpenAI. (2025, September 29). Introducing parental controls.
OpenAI Help Center. (2025). Is ChatGPT safe for all ages?
Rosanda, V., et al. (2025). Robot-supported lessons and learning outcomes. British Journal of Educational Technology.
Time Magazine. (2025, December). The hidden danger inside AI toys for kids.
UNESCO. (2023/2025). Guidance for generative AI in education and research.
The Verge. (2025, December). AI toys are telling kids how to find knives, and senators are mad.
Wang, X., et al. (2025). Meta-analyzing the impacts of social robots for children’s language development: Insights from two decades of research (2003–2023). Trends in Neuroscience and Education.
Zhang, X., et al. (2023). A social robot reading partner for explorative guidance. Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
How North Korea-Russia Military Help is Changing Security in Eurasia
Pyongyang supplies shells and labor to Russia Sanctions erode; nuclear recognition pressure rises Choke arms-for-oil routes; align allies

The military support between North Korea and Russ
Getting Rid of Coordination Headaches: How LLMs are Changing How We Work Together
Getting Rid of Coordination Headaches: How LLMs are Changing How We Work Together
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
LLMs slash coordination costs in teams Design- and model-minded co-create, instantly Protect diversity with drafts, provenance, human review

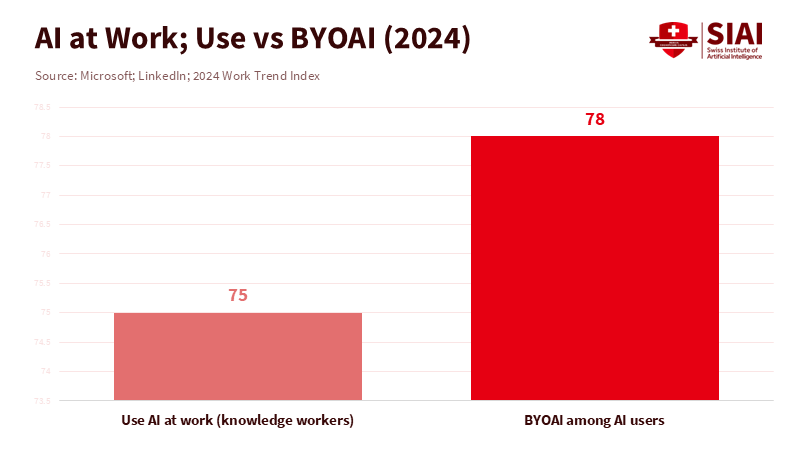
Every second, a new developer is signing up for GitHub. Back in 2025, over 36 million folks joined, and almost 80% of the newbies gave Copilot a shot during their first week. This isn't just a fad; it's a real shift in how we team up. Plus, about 75% of people who work with info say they're now using AI on the job. When you look at these facts together, it's easy to see that teaming up with LLMs has made coordinating things cheaper than creating them from scratch. Things that used to take hours of back-and-forth email—like renaming a variable or ensuring a style guide is followed—now take minutes. The amount of work in one go has gotten smaller. The time it takes to turn an idea into something a team can use has shrunk. This isn't just about being faster. It's about who gets to pitch in, how their ideas spread, and how we keep different ways of thinking alive so teamwork stays creative.
How LLMs are Changing What One Person Can Do
We used to see teaming up as a scheduling mess. People had to find time, combine versions, and argue about style in comment sections. LLMs turn those problems into perks. Now, a teammate can share a function, have the AI write test examples, and start a review—all at once. Another teammate can ask for a simple explanation of the code, then have the AI make a simple demo. The platform itself is like another teammate: it writes basic code, suggests changes, speeds up reviews, and keeps naming consistent. You end up with a different way of working. We hand in more than hand off, with many small changes happening at once without needing a ton of coordination. In schools, this means students can go from idea to a simple version in a day, then clean it up before class. In a writing class, a document can evolve through rewrites and merging ideas, with the AI maintaining a consistent style.
This change isn't just about coding. It's happening with presentations, documents, and data, too. A teaching assistant can write summaries, draft notes for speakers, and make sure citations are the same across a shared plan. In a lab, AI can make sure notations are consistent across a paper, turn a method section into a checklist, and translate an abstract for someone in another country. Translations are now so good that AIs can compete with experts, mostly for everyday text. The result is easy: you can focus on what matters, not just the small stuff. Teachers can grade for understanding, not grammar. And because AI makes cleanup cheap, teams can try things more often, which helps people learn.
Two Brains, One Place: Design and Code Working Together
A good team needs two kinds of thinkers. The design-minded ones shape the story, the interface, and how people will use the project. The code-minded ones build the structure—the functions—that make the system strong. LLMs let both types work without getting in each other's way. The design-minded can see the AI as a quick editor: translating a draft into simple English, shrinking a huge review, or testing an argument. They can ask for three styles of explanation—story, outline, and step-by-step—and use whichever is best. Because changes happen instantly, they can change the tone across the whole file in one go. This keeps the team's work clean while preserving individual voices.
The code-minded get a different advantage. They can rename variables, move settings into a config file, and keep the code consistent in a single step. When people want different notation, the AI can make a version in the style they prefer—like Greek—without messing things up. In data, the AI can turn a plan into code, write test code, and explain each step. These are big wins. They save hours of boring coordination and lower the chance of problems. Now, the design-minded and code-minded can meet in the middle. One group makes things clear; the other makes things work right. The AI makes sure its changes fit together so the system runs and reads as one.
Keeping Things Diverse
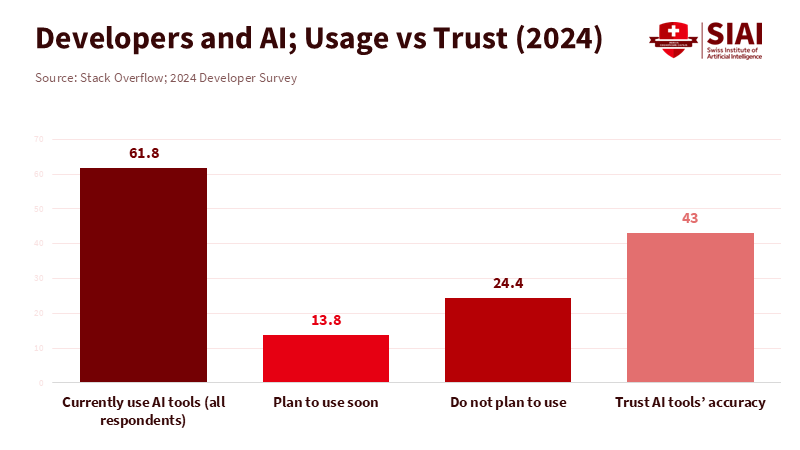
Here's the thing. Quick agreement can turn into everyone thinking the same. When teams use the same AI, the style can get too similar. Word choices get closer. Examples repeat. Even code starts to look the same. Studies show how AI makes things look average. Surveys show people use these tools a lot but don't always trust them, especially for tough stuff. That's good. LLMs are great for first drafts, but they can erase other perspectives if we let them. In schools, essays might sound the same. In labs, the same code might shape every experiment. The problem isn't that students stop thinking. It's that they stop thinking differently.
To fight this, we need to make sure there's room for different ideas. First, ask for two or three drafts before deciding. Make sure one draft uses sources the class hasn't already used. For code, have a wild branch where weird code styles are okay and only get merged back later. Second, keep track of where changes come from. When the AI suggests something, show that it's from the AI and link to the request. This makes reviews easier and teaches students to think for themselves. Third, use different AIs. A lab that switches between systems reduces the likelihood that everyone will sound the same. This isn't about making things hard; it's about keeping creative ideas alive while still being fast.
How to Do This on Campus and on Teams
The goal is simple: be fast without making everyone think alike. For teachers, set clear rules. Allow AI for editing, rewriting, and explaining, but require students to state when they use it. Grade the thinking, not just the writing, and have students defend their work in person. This reduces reliance on AI too much. Give templates that turn the AI into a tutor, not a ghostwriter: explain-then-rewrite for essays; comment-then-refactor for code; compare-two-ways for methods. Teachers can add tests to projects so that AI suggestions must meet standards. In group work, make sure each person has one unique idea that the AI only improves later.
Schools can make things better, too. Offer licenses for approved tools so students don't use accounts with bad privacy settings. Set up a system for course materials so AI pulls from the school's info, not random web pages. Make an AI syllabus that says what's allowed, how to use AI, and what happens if you misuse it. For research groups, ensure results are easily repeatable: use containers, write READMEs, and run style and security checks. This doesn't have to cost a lot. It's mostly about design—making the right thing easy.
Leaders can do the same. See the AI as a teammate that needs review. Track how often AI-suggested code is used; track errors on AI-made summaries; track how long it takes to merge AI changes. Share these numbers with teams so they use AI based on facts, not hype. When working with people in other countries, use AI to level the playing field: translate comments, summarize long discussions, and maintain consistent terminology. But make sure people make the final calls on security, fairness, and legal stuff. The idea isn't to slow down; it's to make speed match good judgment so AI helps with quality, not just quantity.
The good thing about this is that teaming up won't be a pain. When people can join a platform every second and use AI from day one, it's easier for everyone to contribute. When most people use AI at work, the line between solo and group work blurs. We should use this, but carefully. LLMs should make us more diverse, not less. That means multiple drafts, clear sources, different tools, and reviews by real people. If we set these rules now, we can keep the speed and still protect the good stuff: clarity, accuracy, and the freedom to be different. The next ten years will be better for teams that try many things fast—and know how to combine them.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Brookings Institution. “AI is Changing the Physics of Collective Intelligence—How Do We Respond?” (2025).
Carnegie Mellon University (Tepper School). “New Paper Articulates How Large Language Models Are Changing Collective Intelligence Forever.” (2024).
Computerworld. “Dropbox to offer its genAI service Dash for download.” (2025).
GitHub. “Octoverse 2025: A new developer joins GitHub every second; AI adoption and productivity signals.” (2025).
Max Planck Institute for Human Development. “Opportunities and Risks of LLMs for Collective Intelligence.” (2024).
Microsoft & LinkedIn. 2024 Work Trend Index Annual Report: AI at Work Is Here. Now Comes the Hard Part. (2024).
Stack Overflow. 2024 Developer Survey—AI Section. (2024).
WMT (Conference on Machine Translation). “Findings of the WMT24 General Machine Translation Task.” (2024).
Z. Sourati et al. “The Homogenizing Effect of Large Language Models on Cognitive Diversity.” (2025).
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.