Dual-Use Defense R&D: Why Markets Are Really Paying for Immediate Demand
Rearmament budgets and backlogs—not civilian optionality—drove the valuation surge Dual-use R&D earns its premium by de-risking delivery and scaling deployable systems Policy should fund deployability, embed compliance, and protect targeted spillovers

The New Tripod? Why a Germany-Japan Security Alliance Won’t Repeat the 1930s
Military spending is surging, and the Russia–China axis tightens A Germany–Japan security alliance is lawful, networked, and unlike the 1930s Link logistics, energy, and industry to turn budgets into credible deterrence
Rethinking the Green Bond Premium in Sovereign Debt
The sovereign green bond premium is tiny and unstable Real value comes from standards, disclosure, and crowding-in private capital Treat the greenium as a signal; cut project risk with credible frameworks and predictable pipelines

AI Industrial Policy Is National Security
AI Industrial Policy Is National Security

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Treat compute and clean power as strategic infrastructure for national security. Crowd in private capital with compute purchase agreements, capacity credits, and loan guarantees Tie support to open access, safety standards, and allied coordination as China accelerates

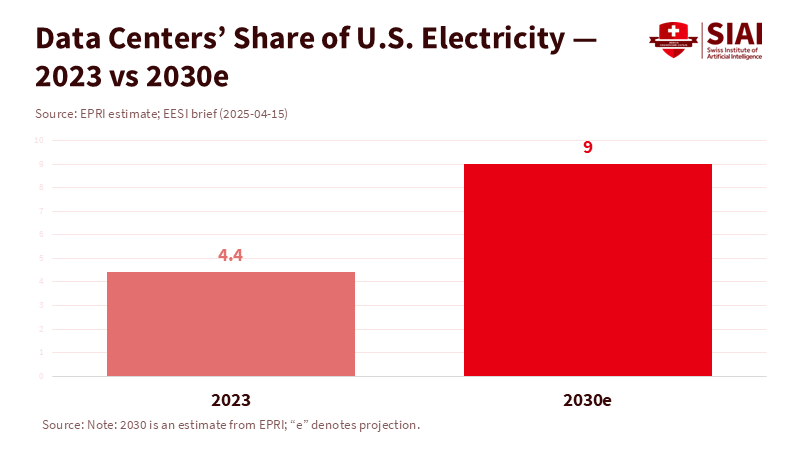
The number to pay attention to is nine. By 2030, U.S. data centers might use up to 9% of all U.S. electricity, mainly due to AI workloads. This estimate from the Electric Power Research Institute reshapes the current discussion. It’s not just about private companies securing enough funding for chips and clusters anymore. This challenge affects energy, manufacturing, and national defense. An AI industrial policy that overlooks power supply, production capacity, and fair access will not succeed. Meanwhile, China’s AI stack is advancing rapidly, from local accelerators to chatbots reaching a global audience. Although markets are thriving now, skeptical headlines could deter investment tomorrow. If we view computing as a private luxury, we invite instability. If we see it as strategic infrastructure, we can build capacity, maintain predictable prices, and set standards that benefit the public and the technological advantage of free nations.
AI industrial policy as a national security initiative
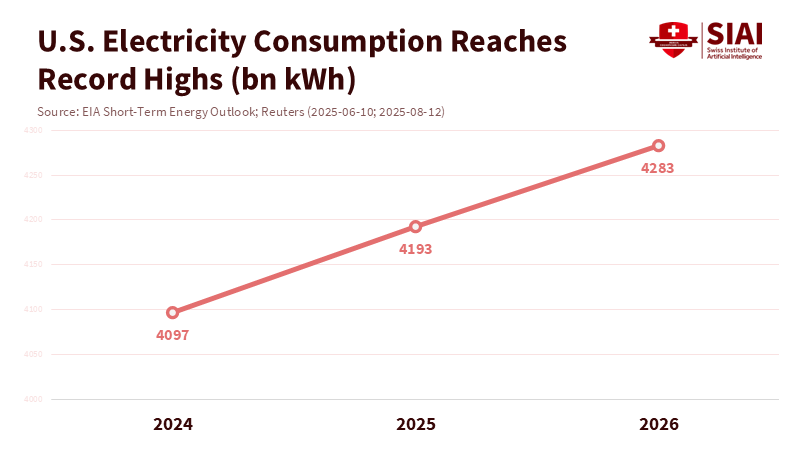
The United States must view advanced computing and its power supply as strategic resources essential for national security. The analogy is not glamorous, but it is relevant: in the 19th century, railroads determined great-power contests; in the 21st century, computing and energy will do the same. Recent policies hint at this change. Washington imposed stricter export controls on high-end AI chips and tools in 2024 and 2025 to limit military transfers and safeguard its lead in training-class semiconductors. At the same time, federal energy forecasts predict record-high electricity demand in 2025 and 2026, with AI-heavy data centers as a significant driver. These signs indicate national security is at stake. The competition is not only about model performance; it’s about supply chains, price stability, and access during crises. In this environment, AI industrial policy becomes the backbone that coordinates interests across computing, energy, and financial markets.
The next step is to ensure that security and openness work together through large-scale planning. Public funding should come with public responsibilities: fair access to critical computing resources, reasonable prices, and resilience. This idea is already reflected in the National AI Research Resource pilot, which provides researchers with computing power and data that they would not otherwise have access to. It also supports industrial grants to restore advanced chip production capacity. However, the current approach lacks the necessary scale and scope. A few grants and a research pilot will not be sufficient as workloads and energy requirements increase. AI industrial policy needs to function at the level of a comprehensive industrial expansion. This requires planning for gigawatts of stable, clean power, petaflops to exaflops of easily accessible computing, and financing that can withstand market fluctuations.
China’s rapid progress makes delay a costly option. Huawei is sending out new Ascend accelerators that domestic buyers consider credible alternatives. At the same time, DeepSeek has demonstrated how an affordable, rapidly evolving model can disrupt markets and perceptions. Western officials have raised alarms about national security threats posed by model use and the risk of chips slipping through control measures. The goal is not to incite panic but to strive for parity. Without a careful, security-focused AI industrial policy, the U.S. risks losing ground as competitors quickly integrate models across government and industry.
AI industrial policy must fund power and computing together
Policy cannot separate computing from the power that supports it. The International Energy Agency predicts global electricity demand from data centers could more than double, reaching around 945 TWh by 2030, with AI being the key factor. In the U.S., federal analysis indicates that total power consumption will hit new highs in 2025 and 2026, with data centers as a major contributor. Suppose computing power expands, but energy supply does not. In that case, prices will rise, installations will slow, and projects will become concentrated in a few locations with weak transmission capabilities. This presents a national risk. A serious AI industrial policy must connect three key elements: grid capacity, long-term procurement of clean power, and the placement of computing resources close to reliable transmission lines.
A financing model is already visible. The Loan Programs Office has used federal credit to restart large-scale, emission-free energy generation, such as the Palisades nuclear plant, through an infrastructure reinvestment program. That same approach can support grid-improving investments, nuclear restarts, upgrades, and long-gestation clean energy projects that can help AI facilities. By combining this with standardized, government-backed power purchase agreements for “AI-capable” megawatts, developers can secure lower-cost financing. On the computing side, we should increase open-access resources through a Strategic Compute Reserve that buys training-class time the same way the government purchases satellite bandwidth. This reserved capacity would be allocated to defense-critical, safety-critical, and open-research needs through clear, competitive rules. The U.S. does not need to own the clusters. Still, it requires reliable, reasonably priced access to them, especially in emergencies.
The numbers support this approach. McKinsey estimates that AI-ready data centers will require around $5.2 trillion in global investment by 2030, with over 40% of that likely to occur in the U.S. The government cannot and should not cover that entire amount. However, it can encourage private investment and address coordination challenges that markets struggle with, like long transmission timelines, uneven connection queues, and volatile power prices. Some federal guarantees, standardized contracts, and risk-sharing strategies will lower borrowing costs, stabilize construction cycles, and keep capacity operational when credit tightens.
AI industrial policy that encourages private investment—even amidst bubble fears
Today, the markets are enthusiastic. Hyperscalers plan to invest tens of billions annually, and chip manufacturers are facing multi-year backlogs. Yet, the forward trend is not guaranteed. Prominent warnings about an “AI bubble” highlight a simple reality: while the long-term narrative may hold, short-term funding cycles can create issues. A few setbacks or economic shocks could slow equity issuance and prompt lenders to withdraw. AI industrial policy must account for this potential. The solution isn’t to issue blank checks; it is to create smart, conditional, counter-cyclical safeguards that prevent key projects from stalling at critical moments.
Three strategies could help. First, compute purchase agreements: long-term federal contracts for training hours and inference capacity with qualified suppliers that meet strict security, privacy, and openness standards. These agreements would secure revenue, reduce financing costs, and prevent favoritism by focusing on delivered capacity and compliance instead of company identities. Second, capacity credits for reliable, clean energy serving certified data centers could be modeled after clean-energy tax credits but linked to reliability and location value. Third, loss-sharing loan guarantees for infrastructure near the grid—such as substations, transmission lines, and high-voltage connections—that private companies under-invest in due to the broad benefits they provide to many users.
We can see how public financing can stimulate private investment without complete nationalization. When Washington provided Intel with a mix of grants and loans through the CHIPS and Science Act, it didn’t acquire equity. It reduced the risks associated with U.S. manufacturing. Following the earnings reports, the company showcased expedited U.S. funding alongside private contributions from global partners. That’s the model: public investment for public benefit, executed by the private sector under enforceable terms. If equity markets fluctuate, the policy cushion keeps progress steady. If they rise, federal exposure remains minimal. In every scenario, AI industrial policy maintains strategic momentum.
Concerns about market excesses must be weighed against real demand. The IEA forecasts that AI-optimized data center energy consumption could quadruple by 2030. U.S. electricity usage is already nearing record highs. Microsoft alone anticipates around $80 billion in AI-driven data center investments for fiscal 2025, with other companies indicating similar trends. Bubble discussions will come and go, but the underlying forces—shifting workflows towards AI assistants, code generation, scientific simulations, and AI-intensive services—are persistent. Policy should lean into this reality by facilitating financing and linking support to openness and security.
AI industrial policy for open access, collaborative deterrence, and standards
Security goes beyond just keeping adversaries away from our technology. It also involves ensuring that crucial computing resources are accessible to innovators, universities, and small businesses that drive the ecosystem. The NAIRR pilot has validated the concept at a research level; now we should expand this idea into a long-term, well-supported facility. An enhanced NAIRR could serve as the public access point to the Strategic Compute Reserve, with strict eligibility criteria, audit processes, and privacy guidelines. Access would come with responsibilities: publishing safety findings, supporting red-team evaluations, and contributing to guidelines for responsible use.
International policy should follow that approach. The U.S. has tightened export restrictions on training-class accelerators and tools, while also rallying allies to close loopholes. Simultaneously, China’s rapid development highlights how quickly cost-effective models can proliferate and how difficult it is to regulate their downstream applications. Concerns have been raised about censorship, data management, and possible military associations. The best response isn’t isolation; it’s forming a trusted-compute network among allies that establishes shared procurement standards, security benchmarks, and auditing requirements for technology and models. If standards are met, access to allied markets, interconnections, and public contracts is granted. If not, it is denied. This strategy turns openness into an asset and positions standards as a form of deterrence.
Finally, openness must encompass markets, not just research labs. Public funding should ensure fair access to essential infrastructure. Contracts for publicly funded technology and its energy should contain favorable access conditions, set aside capacity for research and startups, and include clear rules against self-preferencing. History shows us that when public funds create private infrastructure, the public must receive more than just ceremonial gestures. It must have access that fosters competition.
Returning to the number nine. Suppose data centers expect to account for 9% of U.S. electricity by 2030. In that case, computing is already a national infrastructure, not a niche sector. We cannot support this infrastructure based on short-term trends or leave it at the mercy of energy constraints and inconsistent standards. A clear AI industrial policy offers a balanced solution. It supports robust, clean power and accessible computing together. It encourages private investment through purchase agreements, credits, and guarantees that might be modest in budget size but significant in impact. It links support to openness, security, and cooperation among allies. Finally, it prepares for funding shifts without interrupting strategic growth. China’s swift advances will not wait. Markets will not always be favorable. The grid will not self-correct. The United States needs to act now—before shortages define the conditions—to ensure computing is reliable, affordable, and accessible. Because in this competition, capacity shapes policy, and policy ensures security.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Associated Press. (2024, May 27 May 27). Elon Musk’s xAI says it has raised $6 billion to develop artificial intelligence.
Biden White House. (2024, March 20 March 20). Fact sheet: President Biden announces up to $8.5 billion preliminary agreement with Intel under the CHIPS & Science Act.
Brookings Institution — Wheeler, T. (2025, November 18 November 18). OpenAI floats federal support for AI infrastructure—what should the public expect?
Energy.gov (U.S. Department of Energy, Grid Deployment Office). Clean energy resources to meet data center electricity demand. (n.d.).
Energy.gov (U.S. Department of Energy, Loan Programs Office). Holtec Palisades. (n.d.).
Holtec International. (2024, September 30 September 30). Holtec closes $1.52B DOE loan to restart Palisades.
International Energy Agency. (2025, April 10 April 10). AI is set to drive surging electricity demand from data centres…
International Energy Agency. (2024). Energy & AI: Energy demand from AI.
Investing.com. (2025, October 23 October 23). Earnings call transcript: Intel Q3 2025 beats expectations.
Le Monde. (2025, February 24 February 24). Artificial intelligence: China’s ‘DeepSeek moment’.
McKinsey & Company. (2025, April 28 April 28). The cost of computing: A $7 trillion race to scale data centers.
McKinsey & Company. (2025, October 7 October 7). The data center dividend.
National Science Foundation. (2024). National AI Research Resource (NAIRR) pilot overview.
National Science Foundation / White House OSTP. (2024, May 6 May 6). Readout: OSTP-NSF event on opportunities at the AI research frontier.
Reuters. (2024, March 29 March 29). U.S. updates export curbs on AI chips and tools to China.
Reuters. (2025, January 13 January 13). U.S. tightens its grip on global AI chip flows.
Reuters. (2025, April 22 April 22). Huawei readies new AI chip for mass shipment as China seeks Nvidia alternatives.
Reuters. (2025, June 10 June 10). Data center demand to push U.S. power use to record highs in 2025, ’26, EIA says.
Reuters. (2025, September 9September 9). U.S. power use is expected to reach record highs in 2025 and 2026, EIA says.
Reuters. (2025, November 18 November 18). No firm is immune if the AI bubble bursts, Google CEO tells BBC.
TIME. (2024, January 26 January 26). The U.S. just took a crucial step toward democratizing AI access (NAIRR pilot).
U.S. Department of Energy (press release). (2025, September 16 September 16). DOE approves sixth loan disbursement to restart Palisades nuclear plant.
Utility Dive. (2024, March 27 March 27). DOE makes $1.5 conditional loan commitment to help Holtec restart Palisades.
Yahoo Finance. (2025, October 24 October 24). Intel’s Q3 earnings surge following U.S. government investment.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
















Digital Mercantilism in Education Markets: What the U.S.-Korea Platform Clash Teaches Schools
Digital mercantilism drives the U.S.–Korea platform fight in schools Make access reciprocal, data portable, and impact proven Treat ed-tech buying as trade policy to protect learning and competition

CBDC Privacy and Monetary Sovereignty: Why Rules, Not Code, Will Decide Adoption
CBDC privacy decides whether people will use digital cash Most countries want CBDCs for sovereignty; the U.S.
Europe's New Defence Bill Can't Come Out of the Classroom
Europe may move to 5% defence Use EU bonds, cut weak subsidies, and buy jointly Ring-fence education and expand skills
Europe is being asked to plan defence spending at 5% of GDP.
SEC-CFTC Harmonization Now, Merger Later: A Risk-Tiered Path for Digital
SEC–CFTC harmonization now; no immediate merger Use a risk-tiered model while stablecoin rules cover payment risks Merge only if regulated payment stablecoins dominate activity and definitions converge

Stop Chasing Followers: Social Network Bridging Is the Real Power in Education
Social network bridging beats raw reach for lasting influence in education Bridges and weak ties move jobs, ideas, and credible signals across clusters faster than hubs Name brokers, track cross-cluster reach, and build routines that link communities

AI Readiness in Financial Supervision: Why Central Banks Move at Different Speeds
AI Readiness in Financial Supervision: Why Central Banks Move at Different Speeds
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI readiness in financial supervision decides who adopts fast and who falls behind In 2024, only 19% used generative tools, with advanced economies far ahea Fund data and governance, scale proven pilots, and measure real outcomes

Only one number frames the debate: nineteen. In 2024, about 19% of countries were using generative AI tools in financial supervision, up from 8% the previous year. The trend is clear. Jurisdictions with better skills, data, and governance frameworks move faster and further; those without these resources fall behind. The result is not just a technology gap; it is a readiness gap linked to income levels and government capacity. In advanced economies, supervisory AI relies on robust data pipelines and model risk rules. In many other parts of the world, limited computing power, weak data, and small talent pools delay adoption and increase risk. If we want AI to improve oversight everywhere—not just where the infrastructure is already in place—we need to treat “AI readiness in financial supervision” as a public good, measure it, and fund it with the same focus we give to capital and liquidity rules.
AI readiness in financial supervision is the new capacity constraint
The global picture is inconsistent. By 2024, three out of four financial authorities in advanced economies had deployed some form of supervisory technology. In emerging and developing economies, that figure was 58%. Most authorities still depend on descriptive analytics and manual processes, but interest in more advanced tools is growing rapidly. A recent survey found that 32 of 42 authorities are using, testing, or developing generative AI; around 60% are exploring how to incorporate AI into key supervisory workflows. Still, the proportion of countries using generative tools in supervision stood at just 19% in 2024. Adoption is happening, but readiness remains the primary constraint.
Broader government capability metrics tell the same story. The 2024 Government AI Readiness Index puts the global average at 47.59. Western Europe averages 69.56, while Sub-Saharan Africa averages 32.70. The United States leads overall, yet Singapore excels in the “Government” and “Data & Infrastructure” pillars—the essential foundations supervisors need. These rankings are not just for show; they indicate whether supervisory teams can build data pipelines, manage third-party risk, and validate models effectively. Where these pillars are weak, projects stall, and regulators stick to manual reviews. Where they are strong, supervisors can adopt safer and more understandable systems and use them in daily practice.
What the data say in 2023–2025
Recent findings from regulators in emerging and developing economies confirm the existence of a readiness gap. Most authorities are still in the early stages of using AI for core tasks like data collection, off-site inspections, and anomaly detection. Basic generative tools are standard for drafting and summarizing, but structured uses for supervision are rare. Only about a quarter of surveyed authorities report having a formal internal AI policy today; in Africa, this share is closer to one-fifth, though many plan to implement policies within a year. The main barriers are clear: data privacy and security, gaps in internal skills, concerns about model risk and explainability, and the challenge of integrating AI into old systems. These are the same issues that readiness indices highlight.
Complementary BIS survey work shows how processes and culture widen the divide. In 2023, 50 authorities from 45 jurisdictions shared insights on their “suptech” activities. Only three had no initiatives at all, but the types of activities varied greatly by income level. Authorities in advanced economies were about twice as likely to host hackathons and collaborate across agencies. Most authorities still develop tools in-house, but the use of open-source environments is low, especially in emerging markets. This matters. Collaboration and open tools reduce costs and speed up learning; their absence forces each authority to start from scratch. The issue is not a lack of ambition in emerging markets. It’s that readiness—skills, processes, and governance—determines the pace.
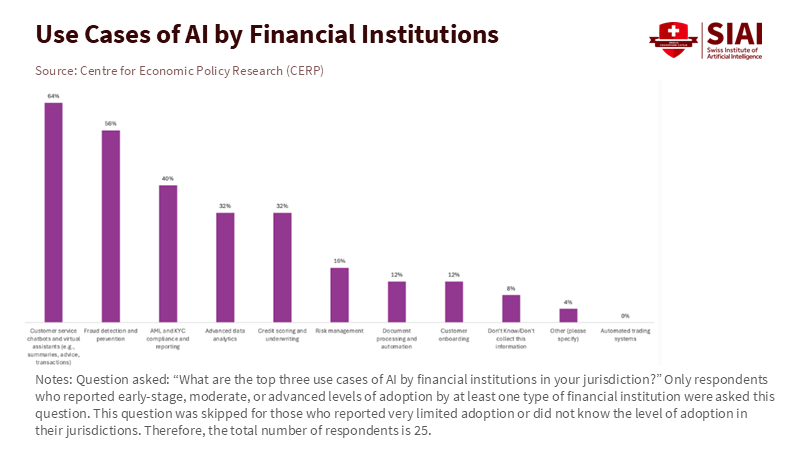
Risk is another important factor. Supervisors are right to be cautious. The Financial Stability Board warns that generative AI introduces new vulnerabilities: model hallucinations, which are instances where the AI model generates incorrect or misleading data; third-party concentration, cyber risk, and pro-cyclical trends if many firms use similar models. The report’s message is cautious but significant: many vulnerabilities fall within existing policy frameworks, but authorities need better data, stronger model risk governance, and international coordination to keep up. Supervisory adoption cannot overlook these constraints; it must incorporate them from the beginning.
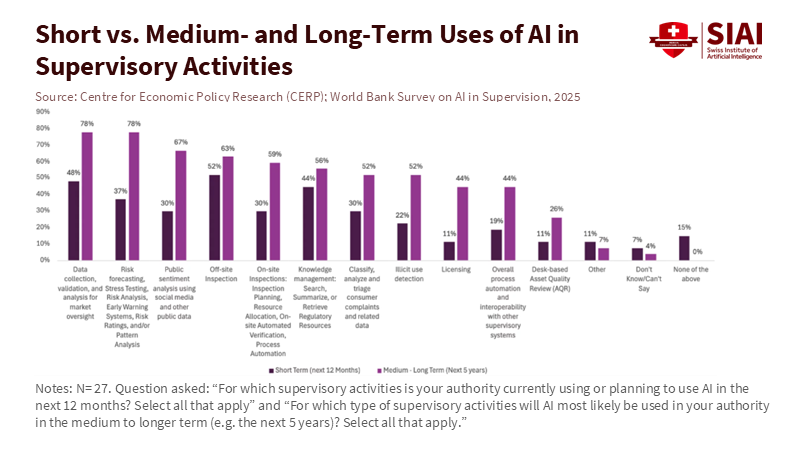
Closing the gap: from pilots to platforms
The first task for authorities with low readiness is not to launch many AI projects. It is to turn one or two valuable pilots into shared platforms. Start with problems where AI truly helps, not just impresses. Fraud detection in payment data, complaint triage, and entity resolution across fragmented registries are good areas to focus on. They utilize data the authority already collects, deliver clear benefits, and strengthen core capabilities—data governance, MLOps, and model validation—that future projects can also use. This is how the most successful supervisors transition from manual spreadsheets to reliable pipelines. It is also how they build trust. Users prefer tools that reduce tedious work and provide results they can easily explain.
Financing and procurement must support this approach. Smaller authorities cannot cover the fixed costs of computing and tools on their own. Regional cloud services with strong data controls, pooled purchases for red-teaming and bias testing, and code-sharing among peers lower entry costs and improve quality. The BIS survey shows strong demand for knowledge sharing and co-development; we should respond with practical solutions. For example, we can standardize data formats for supervisory reports and publish reference implementations for data ingestion and validation. Another approach is to fund open, audited libraries for risk scoring that smaller authorities can build on. These are public goods that maximize limited budgets and enhance safety.
Standards, safeguards, and measuring what matters
Rules and metrics determine whether AI is beneficial or harmful. Authorities need three safeguards before any model impacts supervisory decisions. First, a clear model-risk policy that aligns materiality with explainability. Low-impact tools can utilize opaque methods with strong oversight; high-impact tools must offer understandable results or be paired with robust challenger models. Second, strict third-party risk controls should be in place from procurement to decommissioning. Many jurisdictions will depend on external models and systems; contracts must address data rights, incident reporting, and exit strategies. Third, disciplined deployment: maintain an active inventory of models, log decisions, and monitor changes with documented re-training. The goal is simple: keep human judgment involved and ensure the technology is auditable.
Measurement should go beyond counting pilots. We should track the time to inspection, reporting backlogs, and the proportion of alerts that lead to supervisory action. Where possible, measure the false-positive and true-positive rates, as well as the differences between the challenger and production models. Connect these operational metrics to readiness scores, such as the IMF’s AI Preparedness Index and the Oxford Insights Index. If an authority’s “data and infrastructure” pillar improves, backlogs and errors should decrease. If they do not, the issue lies in the design, not the capability. The benefits of getting this right are significant. The IMF estimates that spending on AI by financial firms could more than double from $166 billion in 2023 to around $400 billion by 2027; without capable supervisors, that investment could pose new risks faster than oversight can adapt.
We started with nineteen—the proportion of countries using generative AI in supervision last year. That number is likely to increase. The question is who will benefit from this growth. If adoption follows readiness, and readiness correlates with income, the gap will widen unless policies change. The way forward is clear and practical. Treat AI readiness in financial supervision the way you treat regulatory capital. Invest in data and model governance before pursuing new use cases. Share code, data formats, and testing methods internationally. Use readiness indices to set baselines and targets, and hold ourselves accountable for meaningful outcome metrics for citizens and markets. AI is not a replacement for supervisory judgment; used correctly, it enhances it. The next wave of adoption should demonstrate this by moving faster where the foundations are strongest and building those foundations where they are weakest.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank for International Settlements (BIS) (2024). Building a more diverse suptech ecosystem: findings from surveys of financial authorities and suptech vendors. BIS FSI Briefs No. 23.
Financial Stability Board (FSB) (2024). The Financial Stability Implications of Artificial Intelligence. 14 November.
International Monetary Fund (IMF) (2024). “Mapping the world’s readiness for artificial intelligence shows prospects diverge.” IMF Blog, 25 June. (AI Preparedness Index Dashboard).
International Monetary Fund (IMF) (2025). Bains, P., Conde, G., Ravikumar, R., & Sonbul Iskender, E. AI Projects in Financial Supervisory Authorities: A Toolkit for Successful Implementation. Working Paper WP/25/199, October.
Oxford Insights (2024). Government AI Readiness Index 2024. December.
World Bank / CEPR VoxEU (2025). Boeddu, G., Feyen, E., de Mesquita Gomes, S. J., Martinez Jaramillo, S., et al. “AI for financial sector supervision: New evidence from emerging market and developing economies.” 18 November.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.