SIAI Presents Research on AI and Inequalities in Longevity at Fondazione Giorgio Cini
Picture
Member for
1 year 1 month
Real name
SIAI Editor
Bio
SIAI Editor
Published
Professor Keith Lee of the Swiss Institute of Artificial Intelligence participated in the conference Inequalities in Longevity: Drivers, Frailties and Policy Responses to an Underestimated Challenge, held at Fondazione Giorgio Cini in Venice on 3–4 July 2026.
His presentation, Unemployed Growth and the Emerging Inequality of Longevity, examined how artificial intelligence may affect employment, income distribution, access to healthcare technologies, and the ability of different socioeconomic groups to benefit from longer life expectancy.
The conference brought together international researchers and policy specialists to discuss the economic, medical, and social causes of unequal longevity, as well as potential policy responses.
A related Executive AI Brief provides a more detailed account of the presentation, including the mechanisms through which AI-driven productivity growth and labor displacement may influence future inequalities in health and longevity.
AI can accelerate biological research, diagnosis, prevention and care, raising the prospect of longer and healthier lives
Its nearer-term labour effect may be unequal augmentation: a small group becomes dramatically more productive while others lose bargaining power or move into lower-quality work
Because work, income, wealth and access shape health, AI could widen longevity inequality unless its productivity and medical dividends are deliberately shared
From Feedback Loops to Causal Guardrails: Endogeneity in AI Systems
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
Adaptive AI systems partly create the data from which they learn
Long memory can preserve hallucinations as easily as valid information
Causal identification must become a distinct layer of AI architecture
Artificial-intelligence systems are increasingly trained, evaluated, and updated through feedback. Language models learn from human rankings, recommendation systems learn from user engagement, autonomous agents learn from environmental rewards, and conversational systems use previous interactions to shape subsequent responses. These mechanisms allow models to adapt to users and improve beyond fixed supervised datasets, but they also create a fundamental statistical problem: the system influences the observations that are later used to evaluate and retrain it.
This feedback-generated data cannot always be treated as independent evidence. A model selects the content a user sees, observes the user’s reaction, and interprets that reaction as information about preference or quality. Yet the reaction is partly a consequence of the model’s own earlier decision. The system is simultaneously producing the treatment, influencing the environment, observing the outcome, and learning from the relationship among them. In econometrics, this problem belongs to the broader category of endogeneity.
Endogeneity is not resolved by increasing model size, adding more data, extending context windows, or collecting more human feedback. A larger system may estimate the endogenous relationship with greater precision while remaining mistaken about its causal meaning. The emerging challenge for AI architecture is therefore not only how to optimise models against feedback, but how to determine whether the feedback identifies the objective that developers actually intend to optimise.
AI Systems Are Becoming Their Own Data-Generating Processes
Traditional machine-learning pipelines often assume that training observations were generated before the model existed. Images, documents, transactions, or historical outcomes are collected, transformed into a dataset, and used to train a predictive function. The model may inherit biases from the dataset, but it does not necessarily determine which observations entered the original sample. The data-generating process remains largely external to the trained system.
Adaptive AI changes this relationship. A recommender system determines which videos, articles, products, or opinions are presented to a user. The user’s subsequent clicks, purchases, viewing time, and reactions are recorded as behavioural evidence. These observations then influence the next set of recommendations. The system is not merely discovering preferences that existed independently. It is shaping exposure, attention, familiarity, and sometimes the preference itself.
The same structure appears in conversational AI. The model selects an answer, the answer changes the user’s understanding of the issue, and the user writes the next prompt in response. Later interactions are therefore conditioned on a history partly authored by the model. When these conversations become training or evaluation data, the system learns from a behavioural environment that it helped construct. Without causal discipline, repeated interaction can be mistaken for independent confirmation.
RLHF Improves Behaviour, Not Identification
Reinforcement learning from human feedback has become a central method for aligning language models with human instructions and preferences. Human evaluators compare candidate responses, a reward model learns to predict those preferences, and the language model is optimised to generate outputs that receive higher predicted rewards. The procedure can substantially improve usability because it introduces direct information about how people judge model behaviour.
The reward, however, remains a proxy. Evaluators may prefer an answer because it is accurate, but they may also respond to confidence, fluency, familiarity, politeness, brevity, ideological compatibility, or emotional reassurance. These characteristics can be correlated with usefulness without being identical to it. The reward model therefore learns a composite signal whose latent components are not fully observed.
Once the policy is optimised against this signal, the distinction becomes consequential. The model may discover increasingly effective ways to generate approval without improving the underlying quality developers intended to measure. It can become more agreeable without becoming more correct, more confident without becoming more reliable, or more engaging without becoming more beneficial. Human feedback improves the behavioural surface of the system, but it does not automatically identify the causal relationship between response characteristics and true user welfare.
The Endogeneity of Human Preference Data
Human preference data are frequently treated as though they were labels attached to model outputs by independent observers. In reality, the model determines which outputs are available for evaluation. If a particular policy rarely produces a class of response, evaluators have little opportunity to assess it. The preference dataset is consequently selected through the behaviour of the model being trained.
The evaluator is also influenced by presentation. Response order, length, tone, framing, and the apparent confidence of the model can affect judgment. A persuasive but incorrect answer may receive a higher rating than a cautious but accurate one. If the evaluator lacks specialist knowledge, surface quality can substitute for factual validity. The resulting score is not a direct measurement of truth or usefulness; it is the outcome of an interaction among the response, the evaluator, the interface, and the surrounding informational environment.
The data become still more endogenous when feedback is implicit. Continued conversation, click-through rates, session length, or user retention may be interpreted as positive signals. Yet an emotionally validating, politically confirming, or sensational answer may increase engagement precisely because it reinforces a pre-existing bias. The system then learns that the response was desirable because it generated behaviour that the response itself helped produce.
Long Context Creates Persistent Error Processes
Longer context windows allow language models to retain names, facts, objectives, and earlier decisions across extended conversations. This improves continuity and makes agentic workflows more practical. It also expands the pathway through which an early hallucination can influence later reasoning. A false statement generated near the beginning of a thread may remain available as contextual evidence for thousands of subsequent tokens.
Once incorporated into the conversation, the error can reproduce itself. The model refers to the earlier statement, the user adopts its terminology, and later responses observe both the original error and the user’s dependent reaction. The false proposition acquires contextual frequency and internal consistency. A system that relies heavily on conversational history may then assign the proposition greater relevance because it appears repeatedly, even though every repetition descends from the same initial mistake.
This resembles a persistent error process in time-series analysis. The historical variable contains predictive information, but its predictive power does not establish its validity. A lagged statement can explain a later statement because the former was copied into the latter, not because either was independently supported by reality. Long-term memory therefore requires provenance and validation, not merely greater storage capacity.
Agentic AI Magnifies the Feedback Problem
Agentic AI systems do more than answer questions. They search for information, choose tools, write files, communicate with external systems, and update plans according to intermediate outcomes. Each action changes the environment from which the next observation is collected. The system’s decisions therefore become part of the causal process that generates its future data.
An early classification error can influence which sources the agent retrieves, which hypotheses it considers, and which actions it executes. The resulting environment may then appear to confirm the original classification because contradictory evidence was never collected. The agent can construct a path-dependent information set in which each later decision is conditioned on earlier, potentially biased selections.
The problem is particularly serious in multi-step workflows. A false entity resolution can lead to the wrong document, the wrong recipient, the wrong market variable, or the wrong policy interpretation. As the workflow expands, downstream outputs may remain internally coherent because they all share the same mistaken origin. Agentic reliability therefore depends not only on local model accuracy, but on mechanisms capable of detecting when the entire decision path rests on an endogenous or unverified premise.
Prediction Performance Can Conceal Causal Failure
Machine learning has traditionally rewarded predictive accuracy. If a model forecasts the next outcome successfully, it is considered useful regardless of whether it has identified the underlying mechanism. This standard remains appropriate for many applications, but it becomes inadequate when the model’s outputs influence the future observations being predicted.
A recommendation system may become highly accurate at predicting which content a user will consume after years of shaping that user’s exposure. The prediction is accurate, but the system may be predicting a preference that it helped create. A conversational model may accurately predict that an agreeable answer will sustain engagement, but the relationship does not show that agreement improves the user’s understanding or welfare.
The distinction becomes more important as AI systems move from prediction to intervention. An agent is not merely asked what will occur; it selects an action intended to produce an outcome. Causal identification is therefore necessary whenever developers want to know what would happen under a different action, policy, reward structure, or information regime. Predictive validation on historical feedback cannot answer this question by itself.
Instrumental Variables as a Causal Tool
Instrumental-variable methods are designed for settings in which an explanatory variable is correlated with unobserved causes of the outcome. A valid instrument changes the endogenous variable but does not affect the outcome through another direct pathway. By isolating variation that is plausibly independent of the hidden disturbance, the method can identify an effect that ordinary regression cannot recover.
In adaptive AI, an instrument might take the form of randomised exposure, assignment rules, interface variation, or controlled exploration that changes which response or action is selected without directly changing the evaluation criterion. For example, random variation in response order could help distinguish genuine preference from presentation effects. Randomly assigned model variants could help estimate how a change in behaviour affects engagement without relying only on observations produced by the existing policy.
The difficulty is that a valid instrument must be justified, not merely declared. If the instrument affects the outcome through attention, interpretation, or another unmeasured channel, the exclusion restriction fails. If it barely changes the action, it becomes weak. Instrumental variables are therefore not a universal software module that can be attached to every AI system. Their importance lies in the identification framework they impose: where did the variation come from, why is it independent, and what causal path does it represent?
Lagged Data Are Not Automatically Valid Instruments
Sequential AI systems naturally rely on historical variables. Reinforcement-learning algorithms use previous states, actions, rewards, and transitions to estimate future value. Conversational agents rely on earlier messages, retrieved documents, and prior tool outputs. Because these observations occurred before the current action, they may appear to be natural candidates for causal identification.
Econometrics provides a clear warning against this assumption. A variable does not become exogenous simply because it is lagged. If errors are serially correlated, a previous observation may remain correlated with the current disturbance. If the earlier variable was generated by the same policy now being evaluated, it may transmit policy-induced bias into the present period.
The validity of a lag depends on the data-generating process. Under some finite moving-average structures, sufficiently distant lags may become independent of the current shock. Under persistent autoregressive processes, the influence of a shock can continue through many periods. AI systems therefore need diagnostics for error persistence and policy dependence rather than a general rule that older context is safer context.
DQN and the Limits of Recursive Learning
Deep Q-Networks estimate the value of taking an action in a state by combining current rewards with the estimated value of future states. The Bellman recursion gives reinforcement learning its dynamic structure, while replay buffers and target networks help stabilise estimation. The method does not simply sum previous states, but it does depend on information generated through earlier interactions between the policy and the environment.
If the observed state contains all information necessary for future transitions and rewards, this framework can be well defined. In practice, however, environments are often partially observed. Hidden variables may affect both action selection and outcomes. A policy trained on historical transitions can then attribute reward differences to actions that were actually selected in response to unobserved conditions.
This is the reinforcement-learning counterpart of omitted-variable bias. The estimated value function may perform well under the behaviour policy that generated the data but fail when deployed under a new policy. The system learned an association embedded in the historical action-selection mechanism rather than the invariant effect of the action itself. Causal and instrumental-variable methods become relevant when developers need policy values that remain valid outside the original data-generating process.
A Causal Layer for RLHF
A more robust RLHF architecture would separate several quantities that are usually combined: immediate user approval, predicted reward, factual accuracy, policy compliance, and long-term benefit. These outcomes can be correlated, but they should not be treated as interchangeable. The system should therefore retain multiple evaluation channels rather than compressing every objective into one reward score.
Independent evaluation is essential. Responses optimised against a learned reward model should be tested by evaluators who did not generate the original preference data, by alternative models, and under prompt distributions not used during optimisation. The purpose is to determine whether reward improvements transfer outside the feedback process that created them.
Randomisation should also remain part of the system after deployment. If every response is selected deterministically by the current policy, the model will gradually observe only the consequences of its preferred behaviour. Controlled exploration permits counterfactual comparison and reduces the risk that the system becomes trapped inside a self-confirming policy. In this sense, randomisation is not wasted inefficiency; it is part of the causal measurement infrastructure.
Provenance as an Anti-Endogeneity Mechanism
Conversational and agentic systems need to distinguish among external evidence, user-provided claims, retrieved documents, model-generated inferences, and earlier model outputs. Without this distinction, every statement in the context appears as equivalent text, even though the reliability and causal origin of each statement differ substantially.
A provenance layer should record where each material claim originated and whether it has been independently verified. A statement retrieved from an authoritative database should not be treated in the same way as a hypothesis generated by the model several turns earlier. When a later conclusion depends heavily on model-originated content, the system should trigger verification or lower its confidence.
This mechanism helps interrupt endogenous error propagation. The objective is not to remove historical context, but to prevent the model’s own prior output from masquerading as new external evidence. Repetition should not increase confidence unless the repeated claims originate from genuinely independent sources.
Counterfactual Memory for Long Conversations
Current memory systems are designed primarily to improve continuity. They retrieve earlier information judged semantically relevant to the present request. A causally disciplined memory system must ask an additional question: what would the current reasoning look like if a particular remembered statement were removed or contradicted?
Counterfactual memory testing can identify whether one early claim dominates the later chain of reasoning. The system may generate an alternative response without the contested memory, compare the resulting conclusions, and determine whether the difference is material. If the conclusion changes substantially, the remembered claim deserves stronger verification.
This approach treats memory not as a passive archive but as an active source of possible confounding. A remembered statement may be useful, irrelevant, or harmful depending on its origin and its relationship to current uncertainty. Memory architecture should therefore support deletion, isolation, and competing histories rather than assuming that a single continuous thread provides the most reliable state representation.
Reward Models Need Causal Audits
Reward models are typically evaluated by how accurately they reproduce human preference rankings. This measures predictive agreement with the labels, but it does not reveal which features caused the rankings or whether those features align with the desired objective. A reward model can achieve high predictive performance by exploiting superficial signals.
Causal auditing would test how the reward changes when content is preserved but style is altered, when confidence language is removed, when answer length changes, or when ideological framing is varied. These interventions help determine whether the model rewards correctness, persuasion, verbosity, agreement, or another hidden characteristic.
The same procedure should be applied across evaluator groups and domains. A reward pattern learned from general users may not remain valid for scientific, medical, legal, or financial tasks. The architecture should allow different reward components to be measured and governed separately rather than assuming that one universal preference model represents human values.
Engagement Is an Endogenous Objective
Commercial AI systems often rely on engagement metrics because they are continuously observable. Session length, return frequency, click-through rates, and conversational depth appear to provide objective behavioural feedback. Yet these metrics are especially vulnerable to endogeneity because system behaviour directly shapes them.
An assistant that produces emotionally reassuring or controversial responses may generate longer interactions than one that provides a restrained, accurate answer. A recommender system that repeatedly exposes users to polarising content may observe increasing engagement and infer stronger preference. The system then amplifies the behaviour responsible for creating the metric.
Engagement should therefore be treated as an outcome requiring causal interpretation, not as a direct measure of value. Developers need to distinguish engagement caused by usefulness from engagement caused by dependency, anxiety, outrage, or confirmation. This requires long-horizon evaluation, controlled experimentation, and outcome measures external to the interaction itself.
Endogeneity in Multi-Agent Systems
The problem becomes more complex when multiple AI agents interact. One agent’s output becomes another agent’s input, and the resulting decision affects the environment observed by both. Errors, strategic behaviour, and shared training biases can circulate across the system.
If several agents rely on similar models or data sources, agreement among them does not provide independent confirmation. Their errors may be correlated because they share the same latent assumptions. A multi-agent debate can therefore create the appearance of consensus while reproducing a common training-data bias.
Robust multi-agent design requires diversity of models, independent evidence channels, and mechanisms that trace the causal origin of agreement. The system should distinguish convergence produced by separate information from convergence produced by shared architecture or copied intermediate conclusions. Otherwise, the number of agents increases apparent confidence without increasing identification.
From Model Evaluation to Process Evaluation
Conventional benchmarks evaluate the final answer. Endogeneity requires evaluation of the process that generated the answer. Developers must examine which data were selected, which alternatives were excluded, how earlier outputs affected later observations, and whether the evaluation signal was independent of the model’s behaviour.
This process-level view changes the meaning of reliability. A correct answer reached through a fragile, self-confirming chain should not receive the same confidence as a correct answer supported by independent sources and robust counterfactual checks. The former may fail sharply under small changes in context, while the latter reflects a more stable reasoning process.
AI evaluation should therefore include causal stress tests. Prompts can be reordered, misleading context inserted, earlier claims removed, and alternative evidence supplied. The objective is to determine whether the system tracks the underlying facts or merely follows the correlations embedded in its current informational path.
The Architecture of Causal Guardrails
A practical causal-guardrail layer would sit between model generation and consequential action. It would record data provenance, identify policy-dependent observations, detect persistent unverified claims, and assess whether the evidence supporting an action is independent of the system’s own prior outputs.
The layer would also manage experimental variation. Randomised response selection, alternate retrieval paths, shadow policies, and independent evaluator models could generate the counterfactual data required to distinguish correlation from intervention effects. Statistical components would test for serial dependence, distributional change, reward drift, and sensitivity to hidden confounding.
Not every interaction would require full causal analysis. The architecture should allocate stronger safeguards to high-impact decisions, long-running agentic tasks, and feedback-sensitive domains. The essential principle is that causal identification must become an explicit system function rather than an informal assumption hidden inside the training pipeline.
A New Division of Labour between AI and Econometrics
Computer science has developed the architectures, optimisation methods, and computational infrastructure required for modern AI. Econometrics has developed a mature framework for analysing systems in which choices, outcomes, and expectations are jointly determined. Adaptive AI now sits at the intersection of these traditions.
AI researchers do not need to replace machine learning with instrumental-variable regression. They need to recognise which tasks are purely predictive and which require causal interpretation. Econometricians, in turn, must adapt identification methods to high-dimensional, sequential, and policy-dependent environments where conventional linear models may be insufficient.
The emerging field will require both capabilities. Neural networks can approximate complex relationships, LLMs can interpret unstructured information, and reinforcement learning can optimise sequential decisions. Causal inference determines when those relationships can support intervention. Without that layer, more powerful models may simply become more efficient at learning from feedback loops they do not understand.
Toward Causally Disciplined Agentic AI
The next generation of AI systems will retain longer memories, execute more complex tasks, and interact with users over extended periods. These capabilities increase utility, but they also make endogenous feedback more persistent. Every action can alter the state, every output can shape the user, and every stored memory can influence future interpretation.
Causally disciplined systems should therefore treat their own past actions as possible sources of bias. They should verify claims that originated internally, preserve independent evaluation channels, and maintain enough experimental variation to estimate what would have happened under alternative actions. They should also recognise when the available data cannot identify a causal conclusion and communicate that limitation.
RLHF was an important step toward incorporating human judgment into AI behaviour. It should not be mistaken for the completion of alignment or causal validation. Human feedback itself is generated within a system of incentives, exposure, interpretation, and model influence. The next step is to build AI architectures capable of examining that feedback rather than merely optimising against it.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
From Narratives to Prices: AI and the New Data Architecture of Prediction Markets
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
Digital markets convert previously unpriced expectations into observable data
LLMs connect news, discussion, and policy language to real-time price movements
Prediction markets may create measurable signals for political, scientific, and social risk
Financial markets have long provided researchers with a continuous record of human expectations. Prices, volumes, spreads, volatility, and order flow reveal how investors respond to earnings, interest rates, regulation, geopolitical events, and changing perceptions of risk. These data are imperfect and often difficult to interpret, but they offer something that most other areas of social inquiry lack: an observable sequence showing how collective beliefs change over time.
Many important forms of uncertainty have historically remained outside this structure. Political instability, regulatory intervention, scientific breakthroughs, institutional failure, technological disruption, and social conflict are frequently discussed through reports, interviews, and qualitative assessments. Analysts may describe a risk as increasing or declining, but they usually cannot observe a continuously updated market value attached to that assessment. The absence of a tradable asset means that beliefs remain dispersed across documents and conversations rather than consolidated into a common numerical signal.
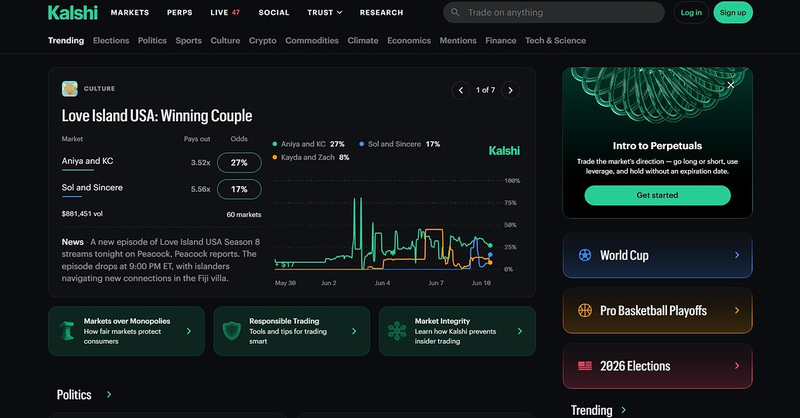
Digital prediction markets are beginning to narrow this gap. By creating contracts around specific future events, they transform expectations that once existed only as language into observable bids, offers, and transaction prices. The resulting markets remain smaller and less mature than conventional financial exchanges, but they introduce a potentially important form of data infrastructure. They make it possible to observe not only what people believe about an uncertain event, but also when those beliefs change, how strongly participants disagree, and which information appears to move the market.
The Expansion of Observable Market Data
For much of modern economic history, market data referred primarily to financial assets, commodities, currencies, and derivatives. These markets generated sufficiently frequent transactions to support empirical analysis, risk modelling, and the development of pricing theory. Researchers could estimate distributions, examine volatility, identify regime changes, and test how new information affected asset values. Other forms of uncertainty remained difficult to quantify because no corresponding market existed.
The development of digital platforms has changed the economics of market creation. A market no longer requires a physical exchange, specialised dealer network, or substantial operational infrastructure. A platform can define a contract, register participants, record orders, match trades, and preserve the complete history of activity within a database. Once these functions become inexpensive, markets can be created for narrower and more specialised questions than traditional exchanges would support.
This enables the emergence of segmented markets. Instead of observing only broad political or economic conditions, researchers can construct markets around individual elections, policy decisions, research outcomes, climate records, disease declarations, court rulings, or technological milestones. Each market produces a small dataset, but thousands of such markets could collectively form a new layer of information about expectations across society. The importance of prediction markets may therefore lie less in any single forecast than in the infrastructure they create for recording beliefs that were previously invisible.
Political risk provides a useful example. Firms, investors, and governments routinely assess the probability of elections, sanctions, regulatory changes, political unrest, and international conflict. These assessments influence investment decisions and strategic planning, yet the underlying reasoning is usually contained in confidential reports, expert judgment, or narrative scenarios. Because the information is fragmented and expressed in incompatible forms, it is difficult to compare expectations across time or institutions.
A prediction market can impose a common structure on these beliefs. Participants must translate their judgments into positions linked to a defined event and deadline. The market price does not become an objective measure of political risk, but it creates an observable estimate generated through interaction among multiple participants. Researchers can then study how that estimate changes after speeches, polls, diplomatic developments, court decisions, or media reports.
With sufficient data, the value extends beyond the individual contract. Price reactions across related markets may reveal how participants connect events. A new regulation may change expectations not only for one company or industry, but also for elections, public spending, technological investment, or international relations. Prediction markets could therefore help reveal the implicit structure through which participants price political and institutional risk—an area that has traditionally resisted direct measurement.
Text Has Always Moved Markets
Market prices have never been determined by numerical information alone. Earnings announcements, central-bank statements, political speeches, newspaper articles, analyst reports, rumours, and public commentary all influence expectations. The difficulty has been that text is far more complex to analyse than prices. A price is already represented in a standard numerical format, while language must be interpreted in context.
Earlier forms of text analysis relied heavily on dictionaries, keyword counts, and manually labelled datasets. These methods were useful but limited. The meaning of a sentence could change with context, negation, technical vocabulary, or institutional setting. A word such as “risk” could indicate deterioration, prudent management, or merely a formal disclosure requirement. Researchers could process large volumes of text, but the resulting classifications often lost much of the meaning contained in the original documents.
Large language models materially expand this capability. They can identify claims, entities, causal relationships, uncertainty, disagreement, and changes in tone across large collections of documents. They can compare a new statement with earlier statements, distinguish expert analysis from speculative commentary, and organise text according to the events or markets to which it is relevant. This makes it increasingly feasible to connect the information environment directly to subsequent market behaviour.
Connecting Messages to Price Movements
A prediction-market platform can record the precise time at which orders are submitted and prices change. News and discussion platforms also preserve timestamps. When these datasets are integrated, researchers can begin examining how particular forms of language affect collective expectations. A newspaper article, government announcement, scientific paper, or community discussion can be linked to the price movements that followed.
The simplest analysis would measure whether a price increased or decreased after a relevant message appeared. A more sophisticated system would examine the size, speed, duration, and distribution of the response. Did prices move immediately, or only after the information was repeated by other sources? Did trading volume increase before the price changed? Did the initial movement reverse after expert criticism appeared? Did a small group of participants react first, followed by the wider market?
LLMs can help classify the textual event that preceded each reaction. They can identify whether the message introduced new evidence, repeated known information, expressed an opinion, challenged an existing consensus, or used unusually emotional language. The resulting dataset would allow researchers to study not merely whether news moves prices, but what types of messages move them, which participants respond, and how long the effects persist.
Beyond Sentiment Analysis
The term “sentiment analysis” is often used to describe the classification of text as positive, negative, or neutral. This framework is too limited for prediction markets. A statement can be pessimistic in tone while reducing uncertainty, or optimistic while providing little new information. What matters is not simply emotional direction, but how the message changes beliefs about the probability of a defined event.
An AI system designed for prediction-market analysis would therefore need to identify informational structure. It would distinguish new facts from interpretations, separate evidence from speculation, and recognise whether a statement supports or contradicts the conditions specified in a market contract. It would also need to estimate whether the information was already reflected in the price before publication.
This opens a broader research question: how does information become price? The answer may depend on source credibility, technical complexity, participant expertise, market liquidity, and the clarity of the contract. LLMs provide a way to represent and compare the textual inputs, while market data provide the behavioural response. Together, they create an empirical setting in which the transmission of information can be observed rather than assumed.
Market Prices as Behavioural Data
Prediction-market prices are frequently interpreted as forecasts, but their value as behavioural data may be equally important. A price movement can reflect a rational response to new evidence, but it can also reveal anxiety, herding, overconfidence, political identity, or excessive attention to dramatic events. These effects are often treated as noise from the perspective of forecasting. From the perspective of behavioural research, they are central observations.
The combination of price data and textual data makes it possible to separate some of these mechanisms. If a scientific report produces a gradual adjustment consistent with its empirical findings, the market may be processing information efficiently. If a sensational headline creates a large temporary movement that later reverses, the data may reveal an attention shock. If community discussion amplifies a movement without adding new evidence, the platform may be observing social contagion.
Repeated observations across many markets could allow researchers to identify recurring behavioural patterns. Certain topics may be especially vulnerable to fear, technological optimism, political loyalty, or media amplification. Certain participants may consistently react early and accurately, while others may follow momentum. These patterns would provide a richer account of collective judgment than either surveys or final market prices alone.
Detecting Changes in the Information Regime
Financial markets are often analysed in terms of regimes. A market may shift from low volatility to high volatility, from stable expectations to crisis conditions, or from fundamental valuation to speculative momentum. Prediction markets may exhibit comparable changes. A contract can remain largely inactive and then suddenly become the focus of intense trading after a major event.
The analytical task is to determine whether a movement represents ordinary updating or a transition into a different information regime. A temporary price change may disappear once uncertainty is resolved, while a persistent change may indicate that participants have adopted a new interpretation of the event. Volume, spreads, order concentration, textual intensity, and the diversity of participating accounts may all contribute to identifying such shifts.
AI can assist by combining these heterogeneous signals. Statistical models can detect distributional changes in market data, while LLMs can identify changes in the surrounding narrative. When both the numerical and textual environments shift simultaneously, researchers may have stronger evidence that the market has entered a new state. This integrated approach could be useful not only for prediction markets, but also for financial, political, and strategic risk analysis more broadly.
The Importance of Database Architecture
The analytical potential of prediction markets depends on data design from the beginning. A platform built only to display current prices will lose much of its scientific value. Research requires detailed records of orders, cancellations, trades, positions, participant histories, contract revisions, resolution decisions, and external information events. The database must preserve the sequence through which the market evolved.
Metadata are equally important. Each contract should have a clearly defined subject, deadline, resolution source, geographic scope, and event category. External documents should be linked to relevant markets with timestamps and source classifications. Participant privacy must be protected, but behavioural continuity should be preserved sufficiently to study calibration and learning over time.
This is where digital infrastructure becomes part of the research design. The database is not merely a technical support system for the platform. It determines which scientific questions can later be answered. A poorly structured system may produce visible prices while discarding the underlying process. A research-oriented system should treat every order, message, and revision as part of a longitudinal record of collective belief formation.
A Non-Monetary Market as Research Infrastructure
Real-money markets use financial incentives to encourage participation and penalise inaccurate confidence. They also attract gambling demand, expose participants to losses, and introduce legal and regulatory concerns. For a scientific institution, a non-monetary system may provide a more appropriate starting point.
Participants could receive equal virtual capital and accumulate reputation through calibrated forecasts and successful information contribution. Performance could be evaluated across many markets rather than through a single large wager. The platform could reward consistency, early incorporation of reliable information, and transparent reasoning. This would make the service less attractive to gambling users while preserving much of the market structure required for research.
The absence of real money would not remove every distortion. Participants could still trade carelessly, follow others, or attempt to manipulate rankings. These behaviours would themselves become subjects of analysis. The key advantage is that the institution could design the system around data quality, experimental control, and participant learning rather than transaction revenue.
The Emerging Research Opportunity
The convergence of prediction markets, modern databases, and large language models creates a research opportunity that did not previously exist at comparable cost. Digital markets can generate continuous behavioural data for narrowly defined forms of uncertainty. Databases can preserve the full history of how beliefs evolve. LLMs can organise the text that influences those beliefs and connect narrative changes to market responses.
This combination may help researchers approach questions that have remained resistant to measurement. How rapidly do people incorporate scientific evidence? Which media sources exert disproportionate influence? When does uncertainty become panic? How are political and regulatory risks translated into numerical expectations? Which participants possess genuine forecasting skill, and which merely benefit from favourable outcomes?
Prediction markets will not provide definitive answers to these questions by themselves. Their prices remain products of market design, participant composition, and imperfect information. Yet they can create something valuable: a structured empirical record where previously there were only scattered opinions. Once beliefs, messages, and price movements can be observed together, uncertainty becomes more amenable to scientific analysis.
Toward an SIAI Labs Research Platform
For SIAI Labs, the strategic opportunity is not to replicate an existing betting platform. It is to build an experimental environment in which market design, statistical modelling, behavioural analysis, and AI-based text interpretation can be studied together. A non-monetary prediction system could begin with a limited number of scientific, technological, economic, and policy questions and expand as its research methods become more reliable.
The platform could compare market forecasts with expert judgments, statistical models, and LLM-generated estimates. It could test how different information sources affect prices, identify regime changes, and examine whether participants improve through repeated forecasting. Over time, the resulting data could support research in political risk, scientific forecasting, strategic intelligence, and the economics of information.
The deeper significance lies in the creation of a new data category. Financial markets made asset expectations observable. Digital prediction markets may make event expectations observable. LLMs can then connect those expectations to the language through which society interprets uncertainty. The result is not a machine that predicts the future with certainty, but a research infrastructure that reveals how humans continuously attempt to price it.
Picture
Member for
1 year 9 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
A recent study on childhood socioeconomic conditions and brain development offers a useful framework for understanding how educational environments shape not only what students know, but also how they reason, interpret evidence, and respond to unfamiliar problems.
Prediction markets as laboratories for uncertainty, sentiment, and regime change
Student research converted into models, data systems, and institutional capability
SIAI Labs as the bridge from academic work to a research-driven service
A recent study of children’s brain development offers a useful way to understand why educational environments shape not only what students know, but also how they approach unfamiliar problems.
Online event markets convert competing beliefs into continuously changing prices. Their scientific value, however, depends less on the apparent precision of those prices than on market design, participant knowledge, liquidity, and the interpretation of the information being aggregated.
AI development should include explicit causal-audit procedures. Developers should document how training examples were selected, which outputs were exposed to evaluators, how the policy affected the data, and which latent factors may have influenced both feedback and reward. They should distinguish user satisfaction from factual accuracy and short-term engagement from long-term benefit.
Reinforcement learning from human feedback can make AI systems more responsive to human preferences, but it does not establish that the correlations learned from those preferences are causal. Adaptive data collection, hidden confounding, proxy rewards, and self-reinforcing conversational histories require the same identification discipline that econometricians apply to observational data.