Families insure children’s income shocks—cash for short hits, saving for long ones
In ageing, low-growth countries, this scales nationally: Japan’s seniors work longer to steady households
Policy fix: public “reinsurance” via income-linked tuition, midlife upskilling, and flexible senior roles in education
From Model Risk to Market Design: Why AI Financial Stability Needs Systemic Guardrails
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI adoption is concentrated on a few cloud and model providers, creating systemic fragility
Correlated behavior and shared updates can amplify shocks across markets
Regulators should stress-test correlation, mandate redundant rails, and map dependencies to safeguard AI financial stability
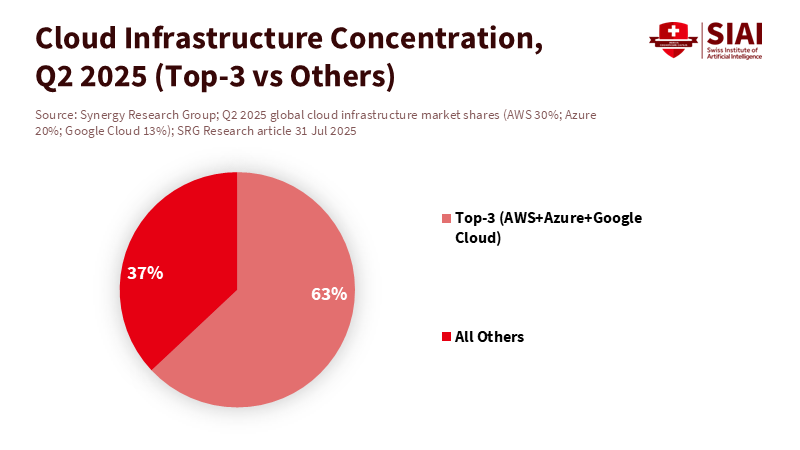
Three vendors now support most of finance’s machine learning systems. By the second quarter of 2025, AWS, Microsoft Azure, and Google Cloud together held about two-thirds of the global cloud infrastructure market. Banks, brokers, insurers, and market utilities increasingly use AI on the same infrastructure, with identical toolchains, often trained on similar data. This is not just about operational ease; it is a market design choice with broader implications. When systems learn from the same patterns and operate on shared frameworks, errors and feedback loops can escalate quickly. Central banks are starting to take notice. The Bank of England has highlighted the need to stress-test AI. The Financial Stability Board points to a lack of visibility into usage and new vulnerabilities. The BIS urges supervisors to balance rapid adoption with strong governance. The challenge for policymakers is straightforward: can we move from fixing models individually to implementing system-level safeguards that support AI financial stability before the next crisis hits?
AI Financial Stability: Reframing the Risk Map
The old perspective views “AI risk” as a series of technical glitches: bias in scorecards, chatbots that misinterpret data, or models that stray from their intended use. The new perspective takes a broader view. Suppose the financial system shifts price discovery, risk transfer, and customer flows onto uniform, centralized AI pipelines. In that case, rare events will change as well. System outages, update failures, or parameter changes at one provider can affect several firms simultaneously. Similar models can respond to the same signals simultaneously, leading to herding. The IMF warns that this can amplify price changes and push leverage and margining frameworks beyond the levels anticipated by older standards. In essence, AI financial stability is not just about better models. It's about shared infrastructures, correlated behaviors, and the speed of collective responses, intended or unintended.
This new perspective is essential now because AI adoption is widespread. Supervisors report significant AI use in credit, surveillance, fraud detection, and trading. ESMA has informed EU firms that boards are accountable for AI-driven decisions, even when tools are sourced from third parties. The FSB’s 2024 assessment highlights monitoring gaps and vendor concentration as structural issues. Meanwhile, the BIS outlines how authorities are adopting AI for policy tasks. A system that runs on AI while being governed by AI offers opportunities for better coordination but also poses risks of correlated failures when inputs are unreliable or stressed. This is a question of stability, not just compliance.
Figure 1: The “compute rail” for finance is already concentrated: the top three clouds host nearly two-thirds of global infrastructure, setting the stage for correlated failure modes.
AI Financial Stability: Evidence on Pressure Points (2023–2025)
First, consider concentration. By mid-2025, the top three cloud providers controlled about two-thirds of the global infrastructure market. While this doesn’t specifically reflect finance, it highlights systemic exposure, as many regulated firms are moving their analytics and data operations to these providers—both the FSB and Bank of England flag third-party and vendor risks in AI. Additionally, IMF discussions prioritize herding and concentration as key concerns. When you combine these factors, the takeaway is straightforward: upstream concentration and downstream uniformity increase risk during stress events. Method note: We use the share of global infrastructure as a proxy for potential concentration in financial AI hosting, following FSB guidance on proxy indicators when direct metrics are unavailable.
Second, focus on speed and amplification. The IMF has warned that AI can accelerate and amplify price movements. Bank of England officials have suggested including AI in stress tests, as widespread use in risk and trading could increase volatility during stressful conditions. The FSB adds that limited data on AI adoption hampers oversight. These concerns are not just theoretical; they relate to familiar situations: one-sided order flow from similarly trained agents, sudden deleveraging when risk limits are hit simultaneously, and operational correlations when many firms patch to the same model update. Method note: these insights come from official speeches and reports from 2024–2025 and align with established surveillance tools. They don’t assume unnoticed failures; they interpret current policy signals as early warnings that need to be incorporated into macroprudential design.
AI Financial Stability: What to Do Now—Design, Not Band-Aids
The first policy shift should move supervision from model risk to market structure. Today’s guidelines focus on validation, documentation, and local explainability. Those are important, but macroprudential policy must also address three design questions: How many independent compute infrastructures support key market functions? How varied are the training data and objectives across major dealers and funds? Can critical services function properly during a failure of a provider or model? These answers will guide the use of known tools: sector-wide scenario analysis that includes correlated AI shocks, system-level concentration limits when feasible, and redundancy requirements for essential infrastructure. The Bank of England’s interest in stress testing AI is a start. The goal is to scale this into a shared, international standard that aligns with FSB monitoring. This will make AI financial stability part of a cohesive macroprudential program, promising a more secure and stable financial future.
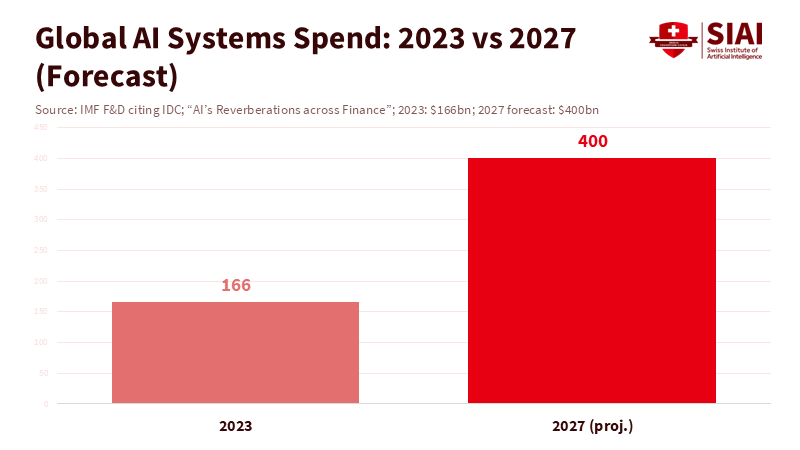
Figure 2: AI spend more than doubles in four years; scale alone can turn local model errors into system features without guardrails.
The second move is to close the data gap without over-collecting proprietary information. Authorities should establish a minimum observatory for AI use: identifying hosting locations by importance, model categories tied to critical functions, change-management schedules, and dependency maps for key datasets and vendors. The FSB has suggested monitoring indicators; these could serve as a standard regulatory return. ESMA has clarified board accountability under MiFID. Following that logic, firms should be able to confirm their AI dependency maps just as they do for cyber and cloud risks. The BIS’s work cataloging supervisory AI can help measure improvements in regulatory technology and identify where shared models might create supervisory blind spots. We don’t need every parameter—we need a clear map —and closing the data gap is a crucial step toward achieving it.
AI Financial Stability: Anticipating the Pushback
One critique suggests that the benefits outweigh the risks. AI is already reducing fraud, speeding up compliance, and enhancing service. Surveys indicate that banks expect significant profit increases in the coming years. While that’s true and positive, benefits don’t eliminate tail risk; they change it. Fraud detection systems that rely on shared models can create single points of failure in payments. Faster client onboarding across the sector can synchronize risk appetites near the peak. In trading, even a slight alignment of objectives can lead to larger price movements more quickly. As Yellen pointed out, scenario analysis must account for opacity and vendor concentration as critical aspects. The goal of a stability regime is not to hinder productivity; it is to protect it.
Another critique argues that existing regulations already cover this area: model risk, outsourcing, and cyber concerns. To some extent, that’s correct. But fragmentation is the issue. Outsourcing rules do not require industry-level redundancy for AI compute used in critical market functions. Model risk regulations do not confront herding among multiple firms, even if each model is sound individually. Cyber frameworks focus on malicious threats, not benign failures that follow a shared update. Policy can adapt quickly. ESMA’s 2024 statement assigns ultimate accountability to the board. The Bank of England is advocating for stress tests. The FSB has defined indicators for adoption. We should integrate these into a macroprudential standard that addresses current market dynamics—one in which AI financial stability hinges on effective correlation management.
The statistic that is introduced in this essay is not just an interesting fact. It forms the core of today’s risk landscape. When a few providers host most of the industry’s AI, when many firms adjust similar models using overlapping data, and when policy itself operates on machine systems, fragility becomes a systemic issue. We do not need to fear AI to address this; we need to view AI financial stability as an essential design task. The steps are straightforward: stress-test correlations, not just capital; require redundant systems where concentration exists; map dependencies as a standard return; and ensure board accountability aligns with industry outcomes. Benefits will expand, not contract, when the market trusts these systems. The next crisis will not wait for perfect data. It will test whether our safeguards match the structure we have chosen. If we act now, we can secure AI’s advantages and mitigate its risks. Delaying may lead to the subsequent surge in speed and herding, catching us off guard even more quickly.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank of England. (2025, April 9). Financial Stability in Focus: Artificial intelligence in the financial system. Breeden, S. (2024). Banks’ use of AI could be included in stress tests [Interview/coverage]. Financial Times. BIS. (2025, October 8). Artificial intelligence and central banks: monetary and financial stability. BIS FSI. (2025, June 26). Financial stability implications of artificial intelligence — Executive summary. ESMA. (2024, May 30). EU watchdog says banks must take full responsibility when using AI [Guidance coverage]. Reuters. FSB. (2024, November 14). The financial stability implications of artificial intelligence (Report and PDF). FSB. (2025, October 10). Monitoring adoption of AI and related vulnerabilities (Indicators paper). IMF. (2024, September 6). Artificial intelligence and its impact on financial markets and financial stability (Remarks). IMF. (2024, Oct.). GFSR, Chapter 3: Advances in AI — Implications for capital markets (Outreach findings on concentration risk). Statista. (2025, August 21). Worldwide market share of leading cloud infrastructure providers, Q2 2025.
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Reciprocal tariffs face a Supreme Court test over presidential authority
They raise import prices, squeezing school budgets and families
Targeted trade tools and smarter procurement beat blanket tariffs
Stablecoin yields mimic Ponzi dynamics and amplify run risk
Ban interest on payment tokens; regulate platforms that bolt on returns
Educators and institutions should teach risks and keep payments separate from investments
Southeast Asia AI Productivity: Why the Payoff Rises or Falls with Learning, Not Just Spend
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
AI investment pays off in Southeast Asia only when paired with real workforce learning
Training, workflow redesign, and governance turn tools into measurable productivity and wage gains
Shift budgets from hardware to people so diffusion is broad, fast, and inclusive
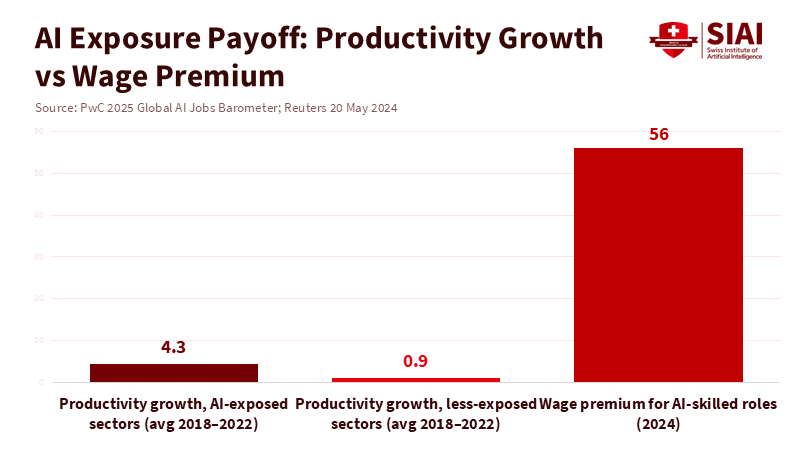
The most revealing number in today’s AI conversation isn’t a billion-dollar investment or a flashy compute benchmark. It’s the fourfold difference in productivity growth between sectors most exposed to AI and those least exposed. This is coupled with a 56% wage premium for workers in AI-skilled roles. These indicators are based on PwC’s analysis of nearly a billion job ads and firm outcomes. They highlight a clear point: where AI is used effectively, output per worker increases quickly, and wages rise. Where it isn’t applied well, the opposite happens. In Southeast Asia, the investment narrative is significant, with tens of billions of dollars poured into data centers and cloud regions, leading the region's digital economy back to double-digit growth. However, the returns depend on people, processes, and time. The main argument of this essay is straightforward: Southeast Asia's AI productivity will depend on how quickly schools, companies, and government bodies can transform AI from mere tools into daily habits.
Southeast Asia AI productivity starts with human learning
We know AI can boost output within firms. An extensive study of customer support agents found that access to a generative AI assistant increased average productivity by about 14%, with the most significant gains—about a third—among the least experienced workers. This scenario is common in many Southeast Asian service jobs, which often have high turnover, steep learning curves, and significant skill gaps. Studies of software illustrate the same point. In a controlled task, developers using GitHub Copilot completed coding nearly 56% faster than the control group. This efficiency increase adds up over a year of sprints and fixes. The mechanism isn’t magical. AI captures practical know-how from skilled workers and offers it to novices during their work, shortening the learning curve and spreading best practices. In short, Southeast Asia's AI productivity improves when learning speeds up.
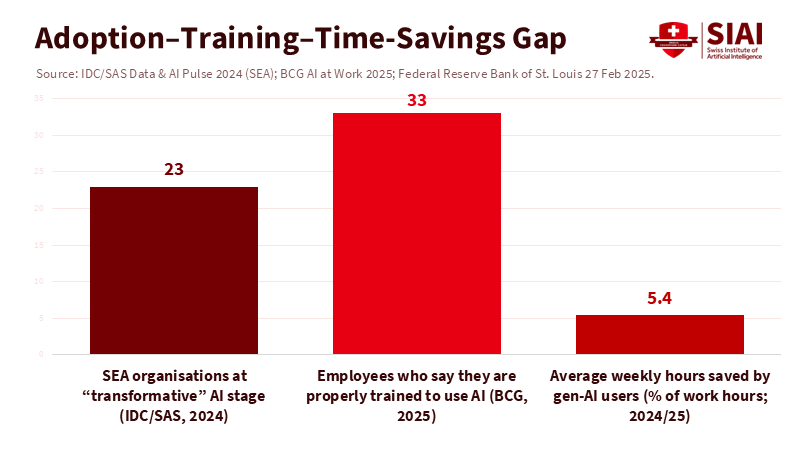
The challenge is that learning never happens for free. Surveys show many employees save significant time using AI, but only a small percentage receive formal training on how to apply it. A global workplace poll found that users save about an hour per day on average, but only 1 in 4 had received training. Another study from the St. Louis Fed measured time savings of 5.4% of weekly hours for users—about 2 hours per week for a standard 40-hour schedule. Training older or less tech-savvy workers requires intentional effort. In a UK pilot, simple permissions and a few hours of coaching significantly increased AI usage among late-career women in lower-income jobs—a lesson with clear implications for Southeast Asia's diverse labor markets. Unless leaders allocate time and money for this human ramp-up, AI tools will remain unused, and productivity will stagnate. Improving Southeast Asia's AI productivity is primarily a management challenge rather than a hardware race.
Southeast Asia AI productivity depends on uneven adoption
Adoption across the region is occurring but remains uneven. According to Google, Temasek, and Bain, over $30 billion was invested in AI infrastructure in Southeast Asia during the first half of 2024, while the broader internet economy returned to double-digit growth. Governments and tech giants are acting quickly: Thailand approved $2.7 billion in funding for data center and cloud investments, while Microsoft committed $1.7 billion to Indonesia, aiming to train 840,000 Indonesians in AI skills as part of a regional goal of 2.5 million. Yet, enterprise readiness lags. An IDC/SAS survey revealed that only 23% of Southeast Asian organizations are at a “transformative” stage of AI use. A separate Deloitte survey shows that executives identify the most significant barriers as talent shortages, risk, and a shaky understanding of the technology. In simple terms, capital is arriving faster than the necessary skills.
Figure 2: Sectors most exposed to AI grew productivity ~5× faster than less-exposed sectors; labor markets also price a 56% wage premium for AI skills—evidence that capability, not hype, drives returns.
There are encouraging signs. Agentic AI—software that connects tasks—might expand quickly as companies turn pilot programs into standard operations. Multiple regional surveys indicate that about two in five firms already use such agents, with most others planning rollouts within the following year. However, relying on averages obscures significant national differences in skills, infrastructure, and digital trust. The World Bank warns that when adoption depends on task structures and complementary skills, the benefits will flow to workers and firms that can adapt to the technology, leaving others behind. The OECD reaches a similar conclusion: AI can boost productivity, but long-term benefits rely on widespread usage, regulations, and inclusivity. This leads to a clear policy implication: to enhance Southeast Asia's AI productivity, leaders must close the “last-mile” gap between large capital expenditures and frontline workers.
Financing Southeast Asia AI productivity: from capex to opex
Much of the AI budget in the region focuses on hardware, cloud credits, and vendor proofs of concept. The larger returns lie in the operating budget: training time, workflow redesign, risk management, and change processes. This is where many digital programs fall short. Research shows that 70% of significant transformations exceed their original budget—often because they underestimate the organizational effort involved. The empirical evidence on potential payoff is becoming clearer. PwC’s analysis links AI exposure to faster productivity growth and increased revenue per employee. MIT’s call center experiment, along with the Copilot RCT, provides estimates of the gains firms can expect from well-planned adoption. These figures support a shift in perspective: view training and change as investments with measurable results, not just expenditures to cut.
What could effective operating expenses look like? Start with hours saved. If typical users can save around 5% of their weekly time now—and even more on repetitive knowledge tasks—modest adoption across a 10,000-person company can yield thousands of hours freed weekly. Add small-group coaching, workflow standards, and secure model access, and the time savings can accelerate further. In practice, measurable benefits often appear quickly once tools are integrated: Bain’s Southeast Asia analysis notes that many firms see returns within 12 months. On the public side, targeted skills programs can increase returns on private investments. The ILO’s new initiative to deliver digital skills in ASEAN’s construction sector serves as a valuable model for employer-linked training. Microsoft’s large-scale upskilling efforts in Indonesia aim in the same direction. A practical rule emerges: if we cannot identify scheduled training hours and a redesigned workflow, we should expect Southeast Asia's AI productivity to disappoint, regardless of how much computing power we acquire.
Figure 2: Only 23% of SEA organisations operate at a transformative AI level and just ~33% of employees report proper AI training; typical users save ~5.4% of weekly hours—small but scalable once training and workflow redesign are funded.
Governing Southeast Asia AI productivity for the long run
Sustained productivity improvements require policies that facilitate diffusion while minimizing harm. The World Bank’s work in East Asia and the Pacific highlights that skill policies, mobility, taxes, and social protections will determine whether technology promotes inclusion or inequality. In education, this means expanding from pilot programs to overarching curricula that include training in prompting, verification, and tool selection from upper secondary levels onward. In TVET systems, this involves establishing AI labs linked to local businesses and introducing stackable micro-credentials that align with real jobs. In universities, it means enforcing strict academic integrity policies while still allowing supervised AI use for drafting, coding, and analysis.
For administrators, procurement should focus on outcomes rather than just acquiring licenses. Contracts can stipulate vendor-funded training hours per license, workflow templates, and measurable time savings at six- and twelve-month intervals. Ministries could collaborate to establish regional standards for model safety, data governance, and interoperability, thereby reducing costs and risks for smaller institutions. The OECD's caution regarding uneven diffusion, combined with PwC's findings on wage premiums, supports reskilling subsidies tied to wages and mobility assistance, ensuring benefits don't just concentrate in already-advantaged areas. Lastly, infrastructure policy must remain practical. Reports on Thailand’s data center expansion and coverage of Indonesia’s hyperscale investments illustrate this point. Data centers are vital, but their social return depends on practical skills and open access. Otherwise, these power-hungry assets could remain unused while schools and clinics lack the necessary tools. The goal of governance is steady, inclusive, measurable, and sustainable improvement in Southeast Asia's AI productivity.
The key figures introduced at the beginning of this essay—greater productivity growth and a 56% wage premium in AI-focused roles—are not inevitable; they are invitations to action. They demonstrate what can be achieved when tools meet trained individuals and when work processes are restructured. In Southeast Asia, capital is flowing in through national data center initiatives and hyperscaler commitments for training. Research results consistently indicate that productivity increases most rapidly when newcomers learn quickly and when managers allocate resources for change. The region now faces a clear choice. It can view AI as a competition for hardware and settle for narrow benefits concentrated in a few companies and cities. Alternatively, it can prioritize people—teachers, nurses, programmers, clerks—and invest in the time, coaching, and standards necessary for practical tool usage. If it chooses the latter path, Southeast Asia's AI productivity could become a strong driver of the next growth cycle: compounding, inclusive, and evident in both paychecks and profits.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Adecco Group. (2024, October 17). AI saves workers an average of one hour each day (press release). AP News. (2024, April 30). Microsoft will invest $1.7 billion in AI and cloud infrastructure in Indonesia. Bain & Company; Google; Temasek. (2024). economy SEA 2024. Key highlights page. BCG. (2024, June 26). AI at Work in 2024: Friend and Foe. Deloitte. (2025). Generative AI in Asia Pacific (regional pulse). IDC (commissioned by SAS). (2024, November 6). IDC Data & AI Pulse: Asia Pacific 2024 (SEA cut). ILO. (2025, June 26). New initiative to boost green and digital skills in ASEAN construction. McKinsey & Company. (2023, April 11). Why most digital transformations fail—and how to flip the odds. NBER (Brynjolfsson, Li, & Raymond). (2023). Generative AI at Work (Working Paper No. 31161). OECD. (2024). The impact of artificial intelligence on productivity, distribution and growth. PwC. (2025, June 3/26). Global AI Jobs Barometer press materials (productivity growth; 56% wage premium). Reuters. (2025, March 17). Thailand approves $2.7 billion of investments in data centres and cloud services. St. Louis Fed. (2025, February 27). The Impact of Generative AI on Work Productivity. The Conversation (hosted via University of Melbourne). (2025, August 14/15). Does AI really boost productivity at work? Research shows gains don’t come cheap or easy. World Bank. (2025, June 2). Future Jobs: Robots, Artificial Intelligence, and Digital Platforms in East Asia and Pacific; (2025, August 5) How new technologies are reshaping work in East Asia and Pacific.
Picture
Member for
1 year 8 months
Real name
David O'Neill
Bio
Professor of AI/Policy, Gordon School of Business, Swiss Institute of Artificial Intelligence
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
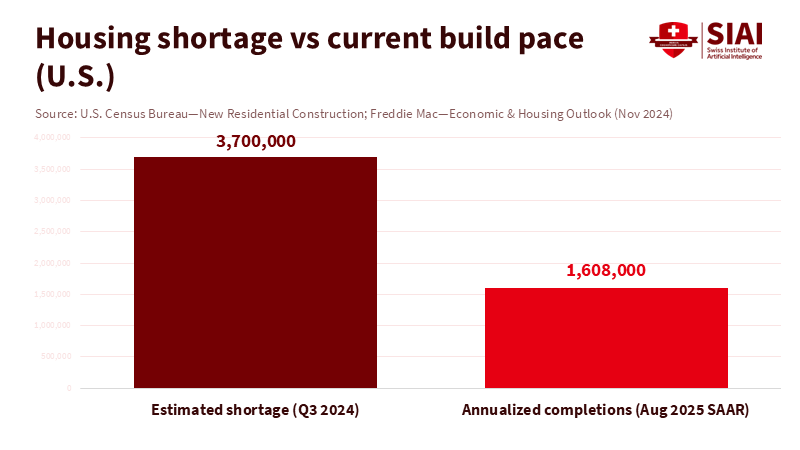
Tiny city samples won’t close the 3.7–3.9 million-home gap
Use real-time public and private data under shared standards and privacy rules
Governments set rails, platforms supply feeds, and weekly human review turns signals into units
Cities do not require a small survey of 50 or 100 households to address the housing shortage. They need a system that can track the market in real time. The key number is clear. The United States is short by about 3.7 to 3.9 million homes, depending on the measure used. This gap did not appear overnight, and it won't close with minor initiatives. It can only close if we utilize the data we already have — much of which is in the private sector — and establish clear guidelines for its use. We should measure, govern, and act at scale. This is the purpose of AI housing supply. It should not replicate the weaker aspects of a survey. Instead, it should strive for a comprehensive market view that updates monthly, or even weekly, and connects to permits, prices, and completions that already influence the system.
Reframing the Problem: From Sampling to Standards for AI Housing Supply
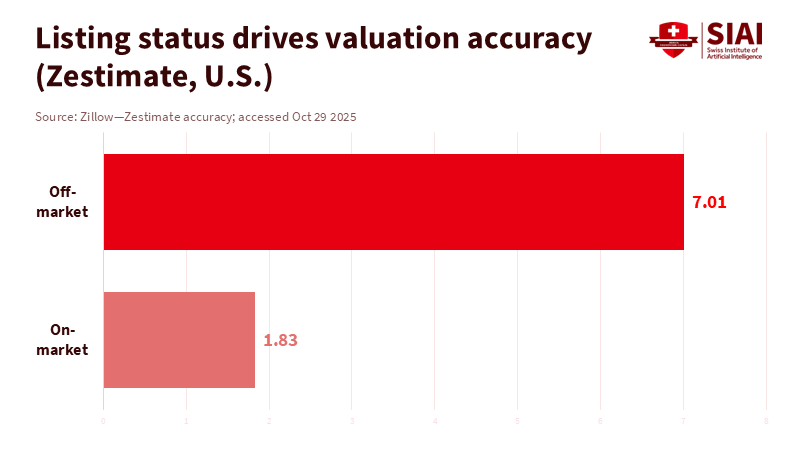
The current suggestions propose that cities create groups, harmonize a few fields, and test AI on small samples. The intention is positive. The aim is to accelerate approvals and site selections. However, relying on samples of a few homes per city cannot compete with the insights that private platforms gather from over 100 million properties every day. Zillow alone offers data on more than 110 million homes and publishes valuations on approximately 100 million, with median error rates under 2 percent for properties on the market in recent years. Redfin updates listings, demand, and price indicators weekly across different markets.
Additionally, public agencies publish timely information on completions, permits, and household counts. The issue is not a lack of data feeds. It lies in the absence of shared standards and lawful, privacy-sensitive methods for combining public and private signals. AI housing supply should begin there, not with a limited city-level sample that cannot capture the market's dynamic aspects.
The argument for smaller samples is based on quality and control. It implies that carefully curated records can address messy, biased inputs. However, this approach sacrifices broad coverage for attention to detail. Housing markets depend on marginal changes: the extra lot that gets rezoned, the small multifamily project that finishes construction, and the changes in price-to-income ratios that allow more buyers to enter the market. If your data falls short of these margins, your policies will not align with the market. Shared standards—such as standardized schemas, reference IDs, and governance—enable us to maintain broad coverage while improving quality. This is the necessary reframing at this moment.
What the Data Already Shows—and How to Use It
Start with the supply. Federal data tracks completions and new construction by unit type and region. In August 2025, the United States completed homes at an annualized rate near 1.6 million units. The single-family rate averaged about 1.09 million units, while the multifamily rate averaged around 500,000 units. Although these figures fluctuate monthly, they remain quick, public, and consistent. They provide a framework for cities to monitor supply and demand. They also allow us to evaluate whether zoning changes or fee modifications appear in future pipelines. AI systems do not need to guess these trends when the data is already available. They should incorporate this information, coordinate it with local rules, and identify where approvals are delayed.
Figure 1: At the August 2025 completions pace, clearing a 3.7M-unit shortage would take ~2.3 years if demand and obsolescence were flat—showing why we need standards and scale, not small samples.
Now let's examine demand and prices. Private platforms track listings, tours, concessions, and closing spreads almost in real time. Zestimates for listed homes maintain low median error rates and span both urban and rural markets. Redfin provides weekly updates on shifts in supply, sale-to-list ratios, and price reductions. When cities decide where to speed up reviews or allow higher housing density, these signals are crucial. They reveal market stress, slack, and how quickly policy changes reach the closing table. If we separate public systems from these private feeds, we limit the effectiveness of the AI tools we hope will assist us. The best approach is to establish lawful, transparent data-sharing with enforceable privacy protections, then train systems using the combined data.
The demand-supply gap is significant and persistent. Freddie Mac's latest analysis estimates the shortage at about 3.7 million homes as of late 2024. Up for Growth's independent estimate shows underproduction nearing 3.85 million in 2022, a slight decrease for the first time in several years. We do not require small samples to recognize the obvious. We need guidelines that allow local leaders to use high-coverage, high-frequency data to direct their limited time to the most pressing issues: land, permits, utilities, and financing timelines. AI can help prioritize cases and identify where an additional inspector or a small code change could create hundreds of units. But only if the models have a complete view.
Governance First: Privacy, Accuracy, and the Public-Private Divide in AI Housing Supply
Privacy poses a real risk on both sides. The federal government has acknowledged this in its policies. Executive Order 14110 directs agencies to manage AI risks, including privacy issues. The Office of Management and Budget has issued guidance on responsible federal AI use. The Census Bureau has strong disclosure controls, including differential privacy, for its core data products. These methods protect individuals but can impact accuracy in small areas if not correctly adjusted. That is a governance lesson, not a reason to shy away from standards. Cities should adopt privacy terms that align with federal practices, require vendor model evaluations, and maintain a simple register outlining "what data we use and why." The goal is balance: public entities share only what is necessary; private partners document their models and controls; and the public can audit both.
Figure 1: On-market valuations are far more accurate than off-market, which is why public–private pipelines must incorporate listing status and documentation rather than rely on tiny hand-built samples.
Accuracy is the second principle. Zillow's documentation outlines how coverage and error vary by market and listing status. Redfin explains when metrics are weekly, rolling, or updated. Public datasets indicate error ranges and revisions. The solution is not to assume that a hand-picked sample is more reliable. Instead, every data field in an AI pipeline should have an accuracy note, a last-updated tag, and a link to its methodology. This enables human reviewers and auditors to assess each signal. It also prevents models from overly relying on a single source in a thin market. Cities can specify these requirements in procurement and can reject claims lacking documentation. This is the kind of straightforward governance that makes AI valuable.
Next comes defining the public-private divide. The government should establish rules for common parcel IDs, zoning and entitlement schemas, timelines for permit statuses, and open APIs for decision-making and appeals. It should not attempt to recreate national market feeds that brokerages and platforms already assemble and refresh. Instead, cities should integrate those feeds into their regulations through contracts, complete with audit rights and sunset clauses. This division of labor respects expertise and accelerates learning. It also reduces the temptation to create a flashy but ineffective government app that wastes funds and stalls after a pilot.
What This Means for Regions—For Universities, School Districts, and City Halls
An education journal should focus on training systems, not just on models. Universities can lead this effort by creating cross-disciplinary studios where planning, data science, and law students develop “living codes” for AI housing supply. These studios can outline a region's permitting steps, label each with data fields, and provide an open schema that any city can implement. They can also assess model biases with real zoning cases and publish the results. This work is practical. It provides cities with ready-made resources and opens pathways for students to pursue meaningful careers in public problem-solving.
School districts have a direct interest in this issue. Housing developments affect enrollment, bus routes, and staffing. Districts should participate when cities establish data standards, ensuring school capacity and equitable access goals are considered alongside sewer maps and transit plans. When AI models highlight growth areas, districts can anticipate teacher hiring and special needs services earlier. They can also verify that new housing aligns with safe walking zones. This is how “AI housing supply” becomes beneficial for families rather than just a distant technical discussion.
City halls can take three actions. First, they should publish a clear, machine-readable entitlement map with parcel IDs and decision timelines. Second, they should sign agreements for data sharing with one or two major private feeds and one public feed that together cover listings, permits, and completions. Third, they should form a small human team that reviews flagged models weekly and updates the public about changes: a rule modified, a utility conflict resolved, or an appeal settled. The weekly frequency is crucial. It fosters transparency and turns data into actionable units.
The objections to these proposals are predictable and deserve responses. One concern is privacy. Here, federal practices demonstrate both the risks and the solutions. Strong disclosure controls can protect individuals while still providing valid aggregate data, and cities can require similar safeguards from vendors. Another objection is that private data might reflect platform interests and potentially include biases. This is valid, which is why contracts should demand documentation of training data, regular error updates, and the possibility of independent audits. A third objection claims that the government must “own” the core models. This confuses ownership with control. Clear standards, transparent contracts, and public dashboards provide absolute control without forcing cities to become data brokers themselves.
There is also the belief that a public cohort will build expertise. It can, but only if it focuses on the correct elements: standards, IDs, APIs, and governance. Much of the necessary framework already exists. Zillow provides extensive coverage in its valuation system; Redfin updates its market data weekly; and federal datasets track counts and completions. The innovative public strategy is to integrate these resources rather than replicate them. And when a private dataset disappears, such as Zillow’s ZTRAX for open research, the response should not be to create a weaker copy. Instead, it is essential to require portable schemas and maintain a minimal public “backbone” of critical fields, so cities can seamlessly exchange data sources.
The timeline is essential. In September 2025, the Census Bureau released new one-year ACS estimates. In August 2025, completions were approximately 1.6 million SAAR. These are current signals, not historical artifacts. They should now be part of city dashboards. When a governor extends a missing-middle incentive or a council adjusts parking requirements, we should see results in permit statuses within weeks and in construction starts within months. AI can help to identify these shifts faster and filter out noise. But standards and data access are necessary for this detection to be effective.
The “home genome” metaphor is compelling, but it risks misinterpretation. The Human Genome Project required new measurements to uncover what was previously invisible. Housing is different. Much of it is already visible. Parcels, zoning, utilities, permits, listings, prices, rents, starts, and completions are available, albeit scattered. The challenge is not discovery but rather integration and governance. This is the leap we need to take: stop acting as if we need to gather a new organism; instead, focus on wiring the system we already have.
Build the Infrastructure, Not Another Sample
Return to the number: a shortage of about 3.7 to 3.9 million homes. That is the key takeaway. AI housing supply must target that scale. A small sample cannot handle this challenge, no matter how well curated it is. The most efficient route is to create public infrastructure—standards, IDs, APIs, and privacy regulations—and apply the best available public and private data to it. Cities maintain control by setting the rules and auditing the models. Platforms should continue what they do best: gathering signals and updating them. Educators should train the workforce that can maintain this infrastructure and question the models. If we succeed, weekly dashboards will translate into construction starts and new residents. If we fail, we will spend another cycle on pilots that yield little and provide less help. The choice is clear: build the infrastructure now and let the market's complete signals guide our efforts.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Brookings Institution. “A home genome project: How a city learning cohort can create AI systems for optimizing housing supply.” Accessed Oct. 29, 2025. Brookings Census Bureau. “American Community Survey (ACS). 2024 1-year estimates released.” Sept. 11, 2025. Census.gov Census Bureau. “New Residential Construction: August 2025.” Sept. 17, 2025. Census.gov Census Bureau. “Simulation, Data Science, & Visualization (research program pages).” 2025. Census.gov Census Bureau. “Disclosure Avoidance and the 2020 Census.” 2023. Census.gov Community Solutions. “Can AI Help Solve the Housing Crisis?” Sept. 23, 2025. Community Solutions Executive Office of the President. “Executive Order 14110: Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.” Nov. 1, 2023. Federal Register Freddie Mac. “Economic, Housing and Mortgage Market Outlook—Updated housing shortage estimate (3.7 million units as of Q3 2024).” Nov. 2024 and Jan. 2025 updates. HUD & Census Bureau. “American Housing Survey (AHS) 2023 release and topical modules.” Sept. 25, 2024. Redfin. “Data Center: Downloadable Housing Market Data.” Accessed Oct. 29, 2025. Up for Growth. “Housing Underproduction in the U.S. (2024).” Oct. 30, 2024. Zillow. “Why Doesn’t My House Have a Zestimate?” Accessed Oct. 29, 2025. Zillow. “Zestimate accuracy.” Accessed Oct. 29, 2025. Zillow. “Building the Neural Zestimate.” Feb. 23, 2023.
Picture
Member for
1 year 8 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Public R&D subsidies de-risk innovation in poor countries
Brazil’s Embrapa shows ~110% productivity gains and ~17:1 payoffs
Fund local adaptation, build capacity, and open data to crowd in private capital
Industrial subsidies in East Asia misallocate resources and dampen productivity
Cheap credit and opaque, incumbent-favoring programs entrench weak firms
Make support transparent, performance-based, and linked to skills and exit
Europe shouldn’t ban multi-issuer stablecoins; it should backstop them
Require joint redemption, a prefunded mutual buffer, and fast resolution to contain failures
This builds euro-scale alternatives to dollar coins while reducing systemic risk